
Table of Contents
You type a prompt. A few seconds later, a photorealistic image appears. But what actually happened between those two moments inside Gemini image generation?
Most explanations stop at “it’s AI.” That’s not good enough for developers who need to reason about model behaviour, debug unexpected outputs, or make architectural decisions. This blog tears open the black box: how Gemini image generation encodes your prompt, operates in latent space, and denoises into a coherent image, and why its architecture beats earlier AI image generation approaches.
The Foundational Shift: From Bolted-On to Native Multimodality
To understand how this system works, you first need to understand what it replaced.

How Earlier Systems Worked
Earlier AI image generation systems operated in pipelines: a language model produced a text embedding, then handed it off to a separate diffusion model (such as Stable Diffusion or DALL·E 2), which used that embedding as a conditioning signal.
The critical problem: two separate systems, two separate training regimes. The language model never truly understood the image it was producing; it provided a static embedding that the diffusion model tried to follow. Gemini image generation was built specifically to eliminate this disconnect.
How Google Gemini Image Generation Is Different
Google Gemini image generation breaks this pipeline entirely. It’s a natively multimodal system; text, images, audio, and video are all processed within the same transformer architecture, using shared representations from the ground up.
The model doesn’t translate text into images; it reasons about images the same way it reasons about text, in a unified token space. Ask Gemini AI image generation to “add a shadow consistent with the light source in the upper right”, and the model has an actual understanding of spatial relationships and light physics, not a pattern-matched approximation. This is why iterative image editing works in Gemini, where it fails in pipeline-based systems.
The Architecture: Multimodal Diffusion Transformer (MDT)
Gemini image generation is built on a Multimodal Diffusion Transformer (MDT) architecture. Three core components are worth understanding.
1. Shared Token Space
Every input, whether text, an uploaded image, or a voice instruction, is tokenised into a unified sequence of discrete tokens. There’s no separate “image branch” or “text branch”; a sentence and a pixel patch are both tokens in the same stream, processed by the same attention layers.
This enables context-aware image generation AI. The model attends to text and image tokens simultaneously, which is why it produces images deeply faithful to compositionally rich prompts rather than surface-level keyword matches.
2. Sparse Mixture-of-Experts (MoE) Routing
The model scales from 450 million to 8 billion parameters, depending on task complexity, but doesn’t activate all of them for every request. A sparse MoE routing layer selects which expert sub-networks are relevant for each input.
| Request Type | Expert Behaviour |
|---|---|
| Photorealistic architectural rendering | Rendering-focused experts |
| Illustrated children’s book character | Style and illustration experts |
| Abstract compositional prompt | Layout and spatial reasoning experts |
This lets a single model maintain coherent quality across wildly different visual styles without one mode degrading another.
3. Diffusion-Based Generation in Latent Space
Gemini image generation doesn’t construct images pixel by pixel. It runs an iterative denoising process in compressed latent space:
- The model starts with a tensor of pure random noise, sampled from a Gaussian distribution.
- A learned reverse diffusion process steers that noise toward a coherent image across multiple timesteps.
- Denoising happens in latent space, not raw pixel space, which makes 4K generation computationally tractable.
- At each timestep, the transformer cross-attends to the encoded prompt, keeping the output on target.
The result isn’t retrieved from a database. It’s synthesised from nothing, guided by your words, timestep by timestep.
Inside a Single Generation: Step-by-Step Breakdown
Here’s exactly what happens from prompt submission to returned image.
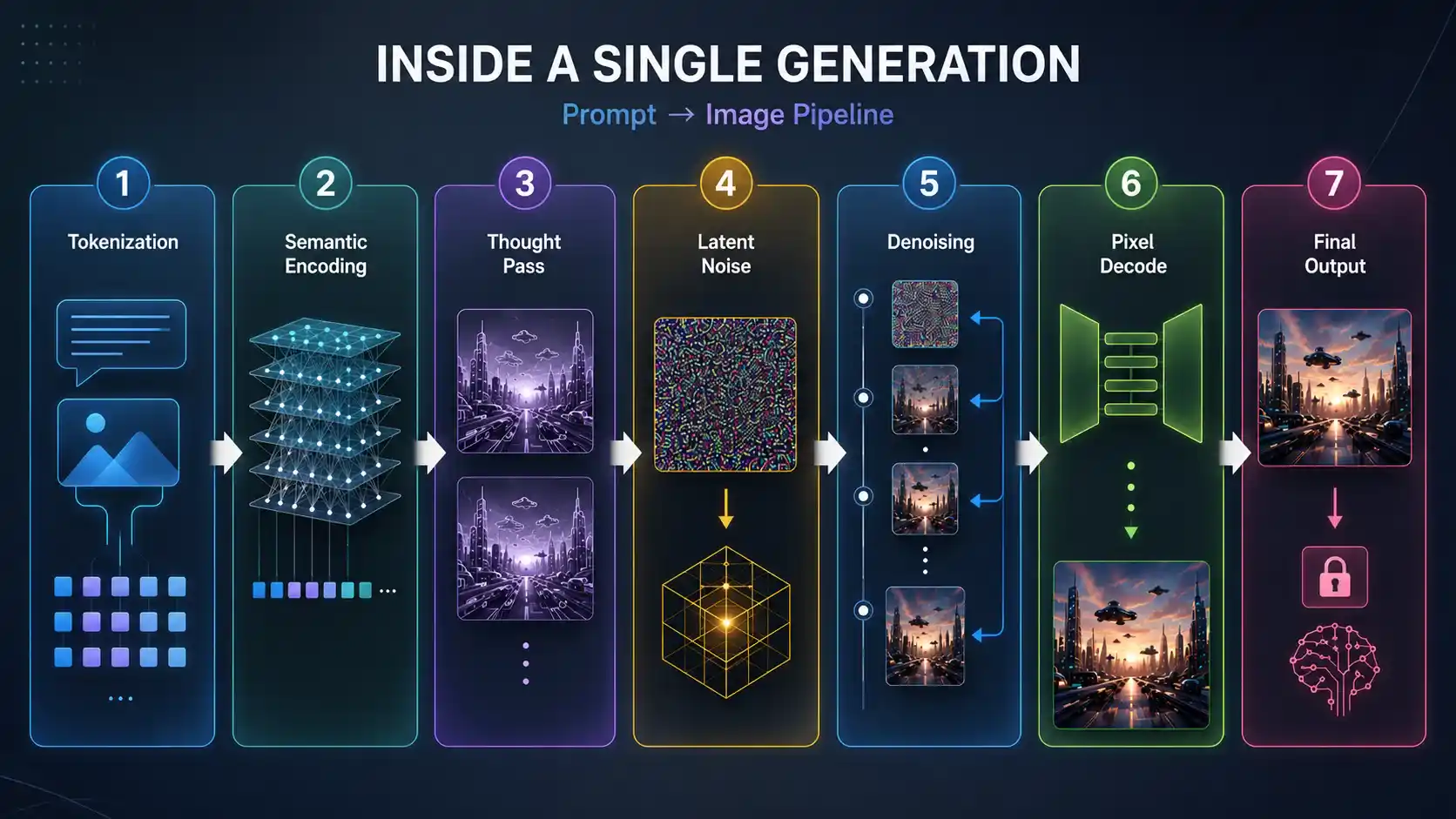
Step 1: Prompt Tokenisation. Your text is tokenised and embedded into the shared multimodal token space. An uploaded image is tokenised the same way and interleaved with your text tokens, the entry point for every Gemini image generation request.
Step 2: Semantic Encoding. The transformer’s attention layers build a rich internal representation of your prompt, spatial layout, material properties, lighting intent, and style signals.
Step 3: Thought Pass (Advanced Models Only). In Nano Banana Pro (Gemini 3 Pro Image), the model generates 1–2 intermediate “thought images” before the final output, evaluating compositional logic first.
Step 4: Latent Noise Initialisation. A random noise tensor is sampled in latent space, the raw material the model sculpts into your image.
Step 5: Iterative Denoising. The denoising transformer runs across T timesteps, each reducing noise and adding structure, with cross-attention to your prompt steering the trajectory.
Step 6: Latent-to-Pixel Decode. A VAE decoder maps the refined latent representation back into full pixel space.
Step 7: Output + Thought Signature. The image bytes return with an encrypted thought signature, a compact encoding of the model’s reasoning state, preserving context across multi-turn editing.
Developer Note: Every image produced by this Gemini image generation pipeline costs exactly 1,290 output tokens regardless of resolution, a fixed footprint that makes per-image cost predictable.
How Prompt Quality Creates Nonlinear Output
Small prompt changes produce disproportionately large output changes in Gemini AI image generation. Because your prompt conditions the entire denoising trajectory, ambiguity propagates through every one of T steps. A vague prompt doesn’t produce a vague version of what you wanted; it produces a confident interpretation of something adjacent to it.
| Prompt Signal | What the Model Does |
|---|---|
| Vague subject | Defaults to generic from training distribution |
| Specific spatial language | Cross-attention weights preserve layout |
| Contradictory descriptors | Finds a compromise point, often unexpected |
| Style + content + lighting specified | Each conditions independent attention heads |
Developer Implication: Iterative refinement via multi-turn editing consistently outperforms trying to write a perfect Gemini prompt for image generation in one shot. The thought signature preserves what was already decided, making progressive refinement more reliable than a single exhaustive prompt for Gemini image generation. Well-structured Gemini prompts for image generation that specify subject, composition, lighting, and style in one pass produce tighter first-generation results.
Nano Banana Pro Internals: What Changes Inside
The standard Gemini Flash image generation model (Nano Banana / Gemini 2.5 Flash Image) runs a single denoising pass. Nano Banana Pro adds extended thinking with reasoning images: 1–2 intermediate image states that evaluate spatial logic, visual consistency, and text legibility before final rendering, like a developer who sketches pseudocode before typing.
| Capability | Gemini Flash Image | Nano Banana Pro |
|---|---|---|
| Multi-element composition accuracy | Standard | Measurably better |
| Text rendering error rate | Higher | Under 10% |
| Max resolution | Standard | 4096×4096 (true 4K) |
| Relative cost per image | 1× baseline | ~3.4× baseline |
The reasoning pass is computationally expensive, which is why Nano Banana Pro costs more, but for compositional accuracy or text-in-image rendering, the difference is real, not just a marketing tier.
Training Regime: What the Model Learned and How
The training regime behind Google Gemini image generation gives it semantic depth that earlier AI for image generation systems lacked. The dataset spans web documents, image-text pairs, code (contributing to structural reasoning), high-resolution images, and audio/video for spatial reasoning.
Critically, all modalities were trained jointly, not sequentially, forcing the architecture to develop representations that generalise across modalities from the start.
One downstream effect: Gemini image generation has genuine world knowledge. It understands what a “brutalist concrete facade” looks like or what “depth of field at f/1.4” implies, not because these were hard-coded, but because the model built these associations across its training corpus. This depth is why Gemini AI outperforms earlier image generation AI tools on semantically complex prompts.
The U-Net-to-DiT Transition and Why It Matters
Older diffusion models, including early Stable Diffusion, which used a U-Net backbone, were effective at local spatial structure but limited at capturing long-range dependencies across an image.
Gemini uses a Diffusion Transformer (DiT) backbone instead. Every patch can attend to every other patch at every denoising step, producing better global compositional coherence.
This shift from convolutional U-Net to attention-based DiT is one of the core reasons Google Gemini image generation produces results that feel more composed than what earlier best AI for image generation tools could achieve.
Known Architectural Limitations
These aren’t implementation bugs; they’re consequences of the latent space, attention-based design.
Iterative Drift. After 3+ editing turns, the denoising trajectory can drift from the original image, a common friction point in long Gemini image generation editing sessions, since each edit compounds small shifts in the latent representation. Fix: reset the prompt rather than patching a drifting session.
Spatial Counting Errors. “Three red chairs around a table” may produce two or four, since spatial relationships are encoded in attention weights rather than a discrete counter. Fix: specify layout (“one on the left, one on the right”) instead of count.
Compositional Conflict. Two strong style signals, “hyperrealistic photo” and “watercolour painting”, create a latent space conflict, and the model compromises between the two. Fix: separate the signals or make one dominant.
High-Frequency Texture Detail. Fine textures like fabric weave or dense handwritten text are often smoothed during denoising, since the VAE round-trip loses high-frequency information by design. Fix: upscale post-generation rather than prompting for more detail.
Key Technical Takeaways
- Gemini image generation is natively multimodal; all modalities share a single token space and transformer architecture, not a pipeline of separate models.
- Generation works through iterative latent-space denoising: noise to coherent image, guided by cross-attention across T timesteps.
- Sparse MoE routing activates only relevant expert sub-networks per request, enabling quality consistency without parameter bloat.
- Thought signatures encode the model’s reasoning state, essential for multi-turn editing, and the root cause of the most common 400 INVALID_ARGUMENT error in iterative sessions.
- The U-Net-to-DiT shift enables global compositional coherence across the entire frame.
- Known failure modes (drift, counting errors, compositional conflict) are architectural, not bugs. Understanding them up front gets you more reliable results out of Gemini image generation on the first attempt.
Gemini AI image generation continues to close the gap on what was previously only achievable with purpose-built AI image generator tools, making it one of the best AI systems for image generation available for developers who need generation and editing in a single multimodal context.
FAQs
Is Gemini image generation just running Stable Diffusion under the hood?
No, it’s a purpose-built Multimodal Diffusion Transformer, proprietary to Google DeepMind, not a wrapper around any open-source backbone.
Why do my outputs look different each time, even with the same prompt?
Diffusion is inherently stochastic, starting from a freshly sampled noise tensor every run. A fixed seed (where supported) removes this randomness.
Does Gemini store the images I generate or remember my prompts?
No, each generation is stateless. The model stores learned weights from training, not any individual user’s output.
How does native multimodal generation differ from Imagen 4?
Nano Banana models support image input and multi-turn editing. Imagen 4 is text-to-image-only, optimised for throughput at a lower price.
Does Gemini use my generated images to retrain its model?
Per Google’s terms, API-generated content isn’t used to train models by default. Consumer app content may be used for improvement unless you opt out.