
Table of Contents
If you ask ChatGPT to summarize a 50-page PDF, it doesn’t actually read the document the way a human does. It doesn’t understand the nuance of the English language, and it doesn’t “think” about the concepts on the page.
Computers are fundamentally terrible at understanding language. They only understand math.
So how does an AI model instantly connect a question about “affordable housing” to a document discussing “budget-friendly apartments” if the exact keywords don’t match?
The answer is a technology called a vector embedding.
Recently, I was helping a friend put together a presentation. We uploaded several images and raw data documents into an AI tool to pull out key summaries. When the tool accurately described exactly what was happening inside the images, my friend, who is relatively new to AI, was stunned. He asked me how the machine could possibly “know” what it was looking at. I had to explain that the AI wasn’t looking at pictures or reading words; it was simply extracting meaning by turning everything into highly complex mathematical coordinates.
While business leaders spend countless hours debating which Large Language Model (LLM) to use, the vector embedding is the actual, silent engine making the magic happen behind the scenes. It is the critical bridge that translates human meaning into computer math.
If your organization is building AI tools, evaluating semantic search, or trying to figure out why your internal wiki is so hard to use, you don’t need a PhD in machine learning. But you do need to understand how vector embeddings work.
What Does “Vector Embedding” Actually Mean?
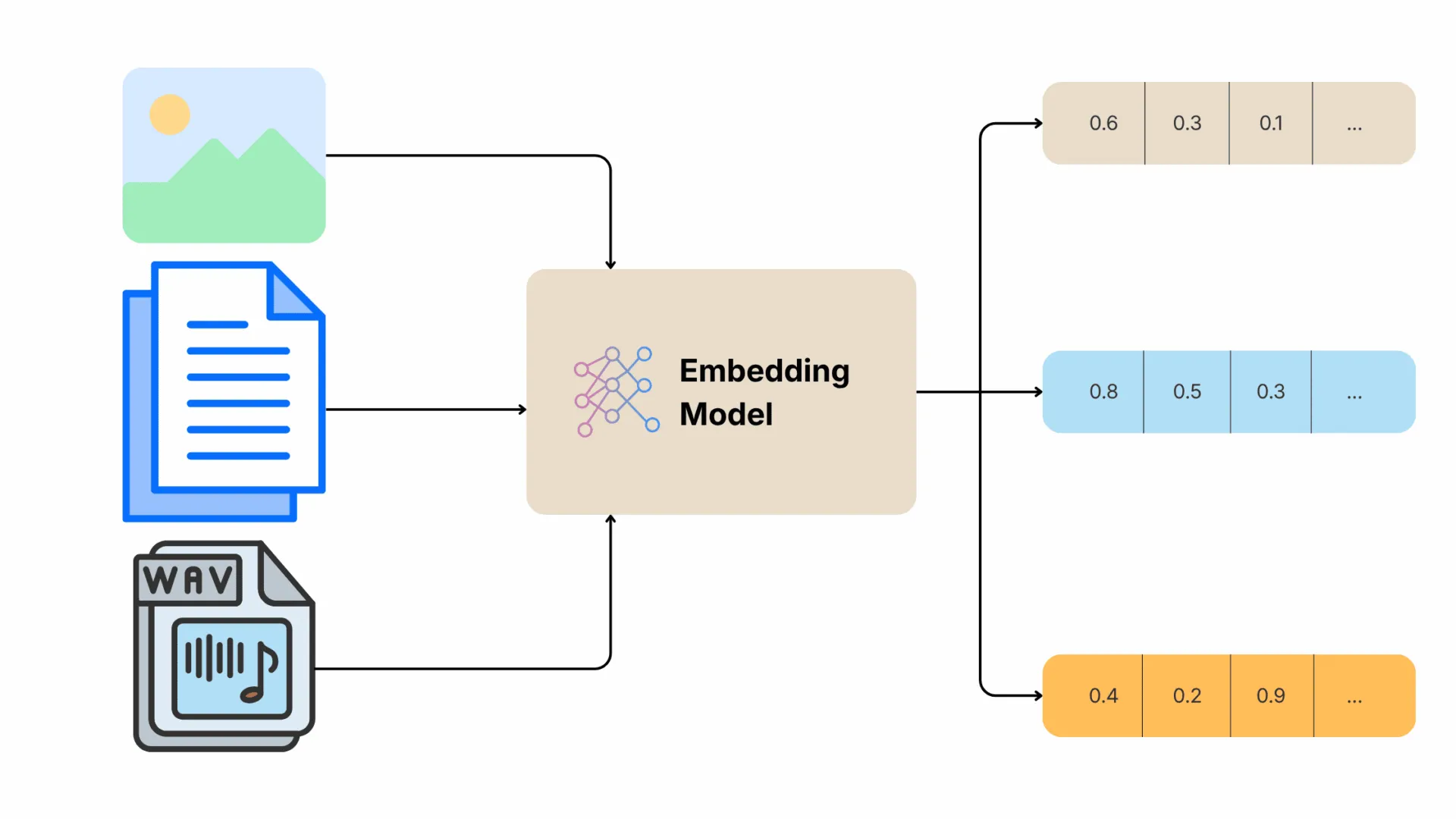
At its core, the vector embedding meaning is surprisingly simple: it is a way to translate words, sentences, or even images into long lists of numbers so that a computer can measure how related they are.
When you look at the word “doctor,” you immediately associate it with “hospital,” “nurse,” and “medicine.” A computer cannot make those associations natively. To a computer, the word “doctor” is just a string of six meaningless letters.
To solve this, AI engineers use vector embeddings to assign a unique list of numbers to every word or concept. This list of numbers acts like a set of GPS coordinates on a massive, invisible map.
The golden rule of vector embeddings is this: Proximity equals similarity.
If two concepts mean the same thing, their number lists will be very similar, and their “GPS coordinates” will place them right next to each other on the map. If two concepts are unrelated, their numbers will be vastly different, placing them far apart.
I have faced the limitations of traditional search multiple times. Whether I’m using the file manager on my laptop or searching within specific mobile apps, if I don’t type the exact, correct keyword, the files simply won’t show up. It is incredibly frustrating when you urgently need to pull up an important bank statement or an application document, but you can’t remember the exact filename. Vector embeddings solve this by allowing systems to search for the meaning of what you want, rather than demanding the exact keystrokes.
The Grocery Store Analogy: How Computers Map Meaning
To visualize how this works without getting bogged down in the math, imagine walking into a massive grocery store.
The store manager doesn’t place items on the shelves randomly. They map out the store based on relationships. You won’t find apples sitting next to bleach. You will find apples near oranges (the fruit aisle), and milk near cheese (the dairy aisle). The physical distance between the items tells you how related they are.
A vector embedding does the exact same thing, but instead of a physical grocery store, it organizes concepts in a mathematical space.
Instead of an aisle for “dairy,” the AI creates a coordinate space for “business leadership.” On this map, the word “CEO” is placed right next to the word “Founder.” The word “Banana” is placed miles away.
Because the computer has mapped out where everything lives, it doesn’t need to know the definition of “CEO.” It simply looks at the math, sees that “CEO” and “Founder” share almost the exact same coordinates, and understands that they are highly related. This is the foundation of how AI actually understands the data you feed it.
Embedding vs. Vector: What is the Difference?
When discussing this technology, you will frequently hear the terms “vector” and “embedding” used interchangeably. While they are closely related, understanding the subtle difference between an embedding vector and the embedding process helps clarify how AI works.
- The Vector: A vector is simply the list of numbers. In mathematics and computer science, an array of numbers (like [0.45, -1.2, 0.89, …]) is called a vector. Think of the vector as the exact GPS coordinates.
- The Embedding: The embedding is the actual space where these numbers live, or the process of translating the word into that space.
To use our grocery store analogy: the “embedding” is the physical layout of the store itself (the aisles and shelves), while the “vector” is the specific aisle number and shelf location where you placed the apples.
How Are Vector Embedding Created?
You don’t have to manually assign numbers to words. That would take human beings thousands of years. Instead, these number lists are generated automatically using embedding vector machine learning models.
To create these embeddings, data scientists feed massive amounts of text, often billions of sentences from books, articles, and websites, into a machine learning algorithm. The algorithm’s only job is to play a giant game of fill-in-the-blank.
As it reads through millions of documents, the algorithm notices patterns. It notices that the word “bank” frequently appears in the same sentences as “money,” “deposit,” and “loan.” Because these words share the same context over and over again, the algorithm automatically adjusts their mathematical coordinates to be closer together.
Through sheer repetition and massive computing power, the model learns the context and relationships of human language, mapping out a multi-dimensional universe of meaning entirely on its own.
This training evolution is exactly why interacting with AI feels so different today than it did a few years ago. Earlier, when AI agents and chatbots were new, they routinely provided generic, clunky answers that rarely gave you exactly what you wanted. Today, the models have come so far that I can share a specific detail or document with an AI agent, and months later, it still has the ability to accurately recall that specific answer and context. It isn’t just matching keywords anymore; it fundamentally understands the meaning of the conversation.
Comparing the Top Vector Embedding Models
Today, you do not need to train your own models from scratch. Major tech companies have already mapped out human language and made their embedding models available for businesses to use.
Choosing the right model depends on your budget, whether you need to process text or images, and how complex your data is. Here is a look at how the industry’s top models compare:
| Model Name | Creator | Best Use Case | Key Advantage |
|---|---|---|---|
| text-embedding-3 | OpenAI | General business applications and conversational AI. | Highly accurate, cost-effective, and integrates seamlessly if you already use ChatGPT APIs. |
| Cohere Embed | Cohere | Enterprise search and heavy document retrieval. | Supports over 100 languages natively; excellent at matching search queries to long documents. |
| all-MiniLM-L6-v2 | SentenceTransformers | Open-source, budget-friendly semantic search. | Free to use and small enough to run locally on your own servers for strict data privacy. |
| Word2Vec | Google (Legacy) | Simple, single-word relationships. | One of the original models; highly efficient but struggles to understand the context of full sentences. |
| Multimodal Embeddings | Google Vertex | E-commerce and catalog search. | Can embed images and text into the exact same space (e.g., searching for a picture using a text description). |
The Different Types of Vector Embedding
While we have focused mostly on text, the true power of vector embedding methods is that they can be applied to almost any type of data. Once data is translated into math, a computer can compare anything to anything.
- Word and Sentence Embeddings: These map individual words or entire paragraphs. This is what allows an AI to know that “The puppy chased the ball” and “A small dog ran after the toy” mean the same thing, even though they share almost no identical words.
- Image Embeddings: Machine learning models can analyze the pixels in a photograph and translate the visual concepts (shapes, colors, objects) into a vector.
- Audio Embeddings: Audio signals can be converted into numbers based on tone, pitch, and waveform.
- Multimodal Embeddings: The most advanced models place text, images, and audio into the same mathematical map. This is how a reverse image search works: you upload a picture of a chair (image embedding), and the AI finds the exact product name in a catalog (text embedding) because they share the same GPS coordinates on the map.
Where Vector Embedding Show Up in AI Tools You Already Use
You are already interacting with vector embeddings in AI every single day, even if you don’t realize it.
When you log into Netflix or Spotify, the recommendation engine isn’t just guessing what you want. The platform has created a vector embedding of you, a list of numbers representing your taste based on your watch history. It then finds movies or songs that have similar mathematical coordinates and recommends them to you.
More recently, this technology has become the backbone of enterprise AI. If you have ever uploaded a massive PDF to an AI tool and asked it questions, you are using embeddings. This process is called Retrieval-Augmented Generation (RAG).
When you ask the AI a question, it doesn’t read the whole PDF from scratch. Instead, it converts your question into an embedding vector, instantly finds the paragraphs in the document that share similar coordinates, and feeds only that highly relevant information to the Large Language Model (LLM) to generate an answer.
At HyScaler, we see this all the time: clients have mountains of historical data but no clear idea of how to use it to drive their business. For example, we worked with an e-commerce client who had three years of raw sales data. By implementing AI, they were able to easily estimate demand and prepare their inventory based on historical patterns. The exact sales figures fluctuate, but the AI calculated the trends to deliver highly valuable, actionable insights. Vector embeddings do the same thing, but for your unstructured data, turning thousands of messy text documents, support tickets, and emails into a structured map of insights that your business can actually use.
Real Business Use Cases for Embedding
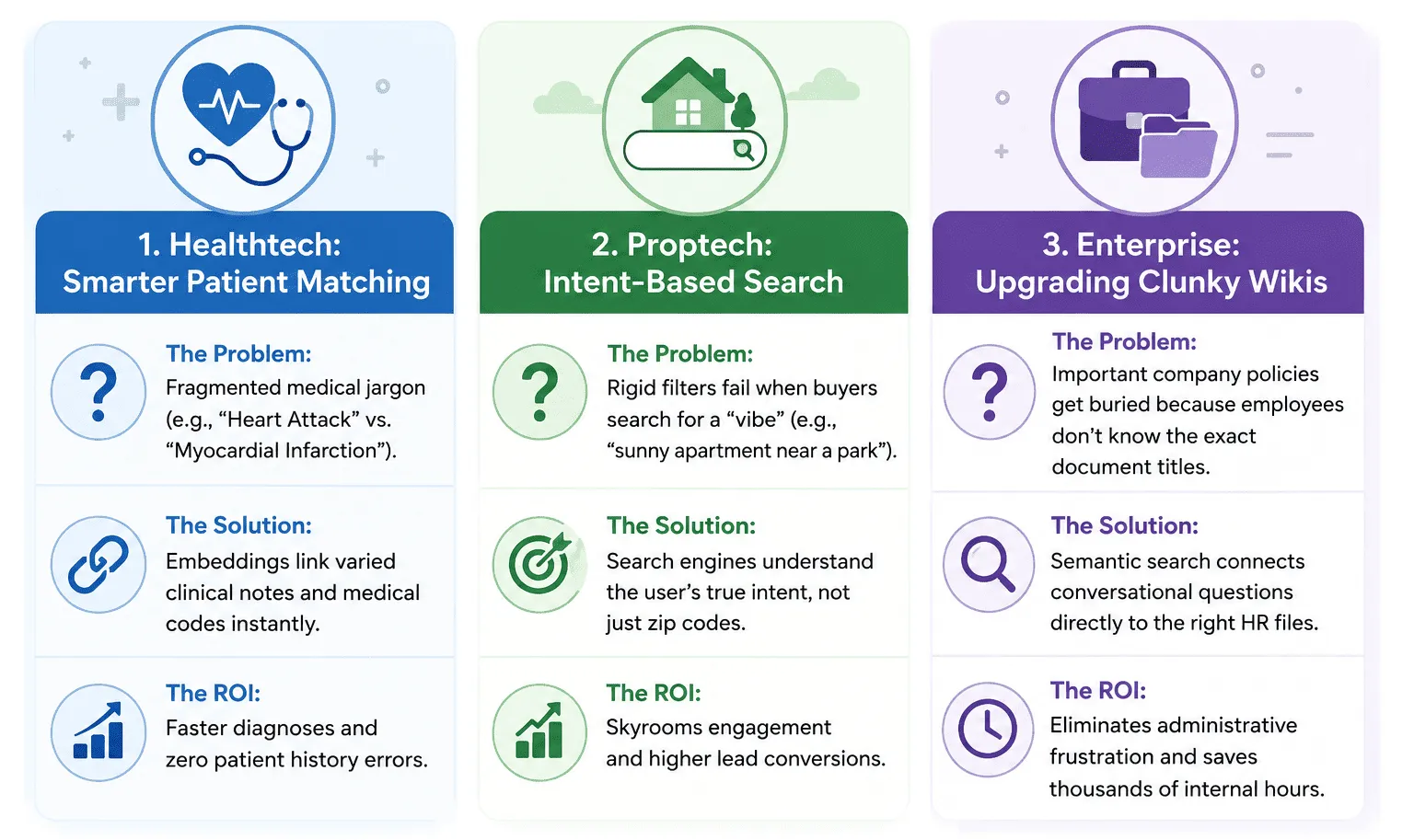
Understanding the theory is great, but the real value is how this technology drives revenue, efficiency, and better user experiences. At HyScaler, we see vector embeddings solving massive data problems across several industries.
- Healthtech: Matching Patient Records and Symptoms. In healthcare, terminology is notoriously complex. A doctor might write “myocardial infarction” in one chart and “heart attack” in another. Traditional databases struggle to link these records. By using vector embeddings, Healthtech applications can instantly recognize that different clinical notes, patient symptoms, and standardized medical codes mean the exact same thing. This improves diagnostic tools, accelerates medical research, and prevents dangerous errors in patient history matching.
- Real Estate Tech: Intent-Based Property Search. Real estate platforms are infamous for rigid search filters. If a buyer searches for “a sunny apartment near a park,” traditional systems fail because they only understand zip codes and square footage. Vector embeddings allow real estate apps to understand the vibe and intent of a user’s search, instantly returning listings that have bright windows and nearby green spaces in the description, dramatically improving the user experience and lead conversion.
- Enterprise: Upgrading Clunky Internal Wikis. Almost every mid-to-large organization has an internal knowledge base or intranet where company policies go to die. Employees can’t find what they need because they don’t know the exact title of the HR document. By replacing keyword search with vector-powered semantic search, employees can type, “How many days off do I get for a new baby?” and the system will instantly retrieve the “Paternity and Maternity Leave Policy,” saving countless hours of administrative frustration.
When You Should (and Shouldn’t) Use Vector Embedding
While embeddings are powerful, they are not a silver bullet for every data problem. Knowing when to use them, and when to avoid them, is the mark of mature tech leadership.
When you SHOULD use them:
- Searching through unstructured data: If you have massive amounts of text, PDFs, emails, images, or audio files, embeddings are the best way to make that data searchable.
- When context and intent matter: If your users search using natural language or vague concepts (e.g., “software for tracking employee hours” instead of exact product names), embeddings will match the intent perfectly.
- Building RAG applications: If you want a chatbot to accurately answer questions based exclusively on your company’s private documents, vector embeddings are the mandatory foundation.
When you SHOULD NOT use them:
- Exact keyword matching: If a user is searching for a specific serial number, order ID, or exact phrase, traditional search is faster and more accurate.
- Highly structured numerical data: If you are analyzing spreadsheets, accounting ledgers, or doing basic inventory forecasting, you need traditional relational databases and statistical machine learning, not vector embedding.
The Limitations and Trade-Offs of Embedding
To make an informed decision about implementing this technology, it is important to understand the trade-offs.
- Cost and Compute Power: Translating millions of documents into massive lists of numbers takes significant processing power. Storing those numbers requires specialized infrastructure called Vector Databases, which can be expensive to run at scale.
- The “Black Box” Problem: If an embedding model decides that two concepts are related, it is often very difficult for a human engineer to audit why the AI grouped those two concepts. This lack of explainability can be a hurdle in highly regulated industries.
- Loss of Nuance: Sometimes, condensing a massive, nuanced document into a single coordinate on a map means losing some of the granular, specific details of the original text.
Frequently Asked Questions (FAQs)
Does ChatGPT use embeddings?
Yes. While ChatGPT is famous for generating text, it relies heavily on embeddings behind the scenes to understand the prompt you type, retrieve relevant context, and organize its internal memory.
What is an example of an embedding in NLP?
In Natural Language Processing (NLP), an embedding might take the word “King” and convert it into an array of 300 different numbers. This allows the computer to mathematically subtract the concept of “Man” and add the concept of “Woman,” arriving at coordinates that closely match the word “Queen.”
Can I create my own embeddings?
Yes, but you rarely need to. Building a model from scratch requires massive amounts of data and computing power. Instead, most businesses use pre-trained open-source models (like SentenceTransformers) or commercial APIs (like OpenAI) to embed their own private data.
Your Next Steps with AI
Vector embeddings are no longer an academic concept reserved for research labs; they are the fundamental building blocks of modern business AI. They act as the universal translator, turning the messy, human world of language and images into the precise, mathematical world that computers understand.
Whether you are looking to upgrade an internal wiki, build a smarter customer support routing system, or implement an enterprise-grade AI assistant, the first step is organizing your unstructured data.
If you know your organization is sitting on a goldmine of data but you aren’t sure how to extract the value from it, you don’t have to figure it out alone. At HyScaler, we specialize in helping businesses cut through the hype and build real, revenue-driving AI solutions.
Explore our Artificial Intelligence consulting services to see how we can help you turn your raw data into a measurable business advantage.