Table of Contents
AI agents are only as useful as the knowledge they can reach. A model might be excellent at writing code, summarizing a report, or analyzing a spreadsheet, but none of that matters if it cannot find the one internal fact it actually needs: what a metric means to your business, why a table was deprecated, or which two systems share a join key. Google Cloud’s answer to that gap is the Google Open Knowledge Format(OKF), and it’s quickly becoming one of the most talked-about ideas in agentic AI infrastructure.
This piece walks through what open knowledge format Google engineers actually built, why they built it, and how the broader Google open knowledge push differs from the wikis, catalogs, and retrieval systems teams already rely on. We’ll also look at the llm wiki thinking that shaped the design and where the open knowledge format Google specification fits for teams deciding whether to adopt it.
Why Google Built the Open Knowledge Format
Foundation models keep improving, but their usefulness in agentic settings is bottlenecked by something simpler than raw capability: access to the right context at the right moment. A model can be asked to compute a business metric, debug a pipeline, or explain a deprecated API, and in each case it needs facts that were never written down in one place to begin with. OKF exists to fix exactly that gap.
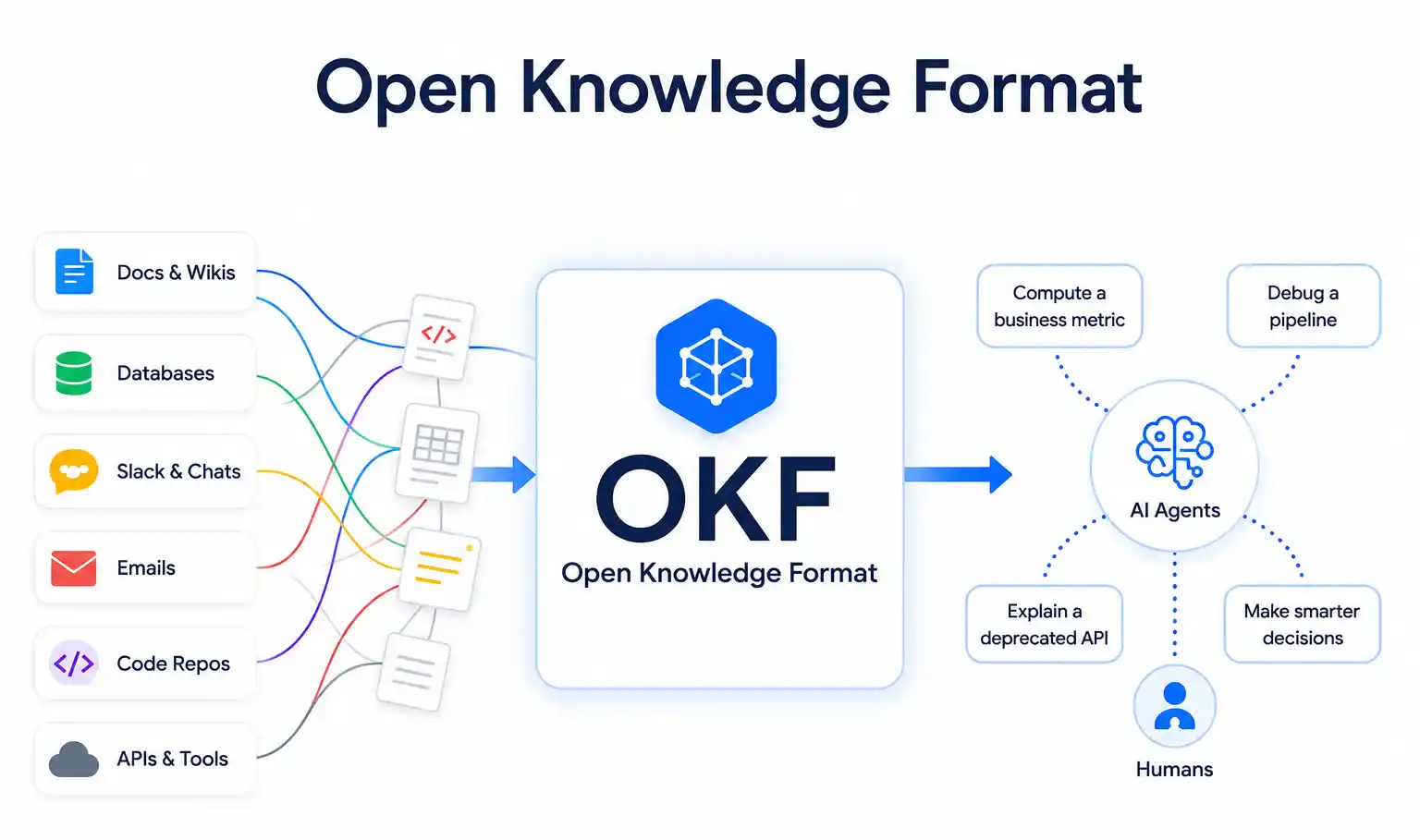
That’s the core problem the Open Knowledge Format, or OKF, was designed to solve. Google describes the Google Open Knowledge Format specification as a vendor-neutral, agent- and human-friendly standard for capturing the metadata, context, and institutional knowledge that AI systems depend on. Rather than asking organizations to adopt a new platform, Google published it as version 0.1, a freely available specification anyone can implement, with no proprietary software required to read or write it.
The Real Problem Google Open Knowledge Format Was Built to Solve
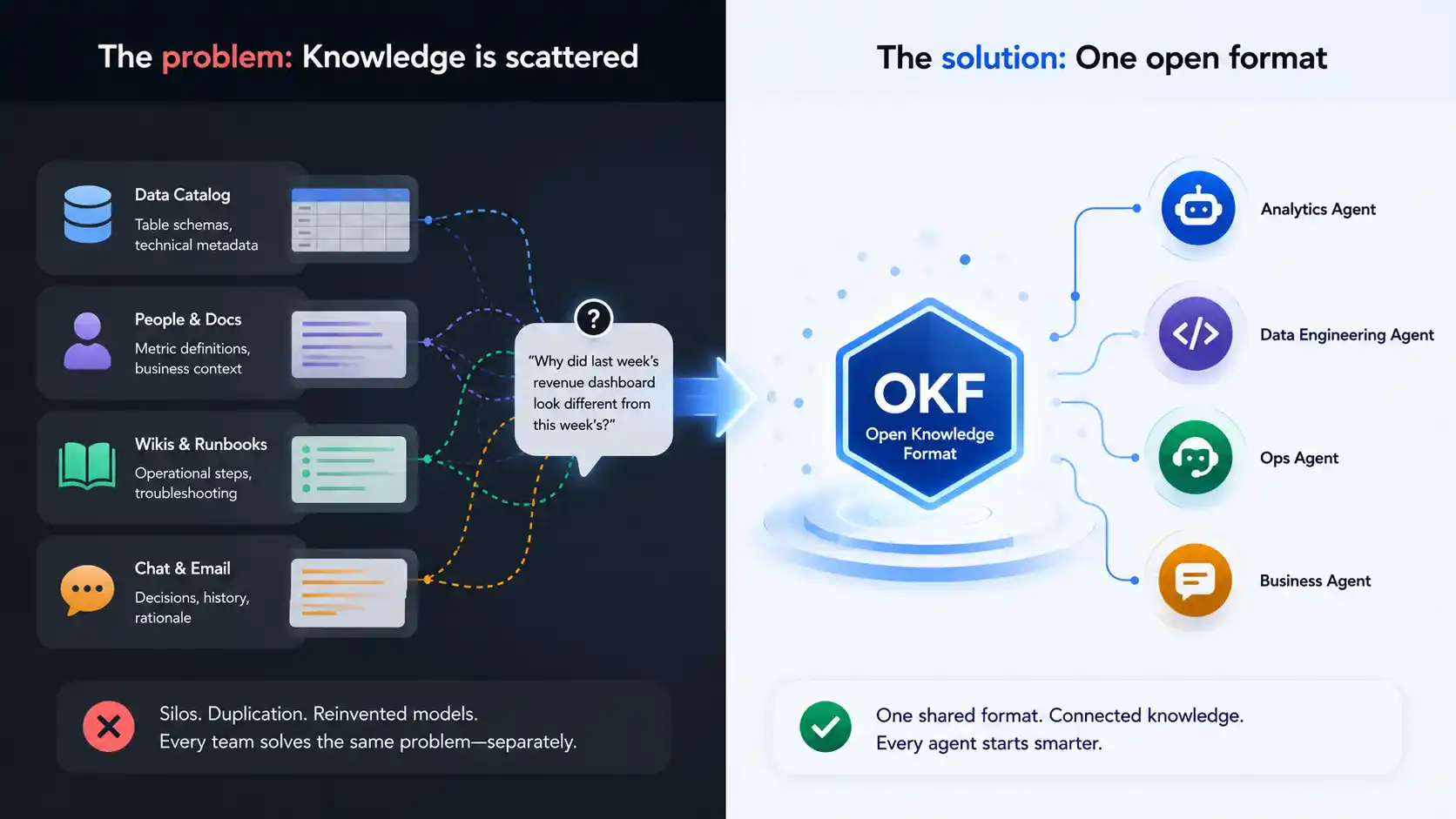
Inside most companies, the facts an AI agent needs are not missing; they’re just scattered across places that were never built to talk to each other:
- A table’s schema lives in one catalog.
- The business definition of a metric lives in someone’s head or an old slide deck.
- The runbook for handling an outage lives in a wiki nobody has opened in months.
- The reason an old endpoint was deprecated lives in a Slack thread that scrolled away years ago.
When an agent is asked something like “why did last week’s revenue dashboard look different from this week’s?” it has no single place to look. It has to reconstruct the answer from incompatible systems never designed to cooperate. Multiply that across every team-building agent inside a large organization, and the duplicated effort becomes enormous: each group builds its own connector to its own catalog, with no way to hand that knowledge to a different team’s agent without starting from zero.
Google’s framing is direct about this: every catalog vendor has been reinventing the same data models, and every agent builder has been solving the same context-assembly problem independently, simply because no shared format like OKF existed for representing this kind of knowledge.
The LLM Wiki Pattern Behind Google’s Open Knowledge Format
Long before Google formalized anything, individual engineers and small teams had already started solving a version of this problem on their own. The pattern usually looked the same: a folder of markdown notes, cross-linked by hand, that an AI coding assistant could read directly instead of waiting for a human to explain things from scratch.
This is the idea AI researcher Andrej Karpathy described in his widely circulated LLM Wiki gist: language models don’t get bored maintaining cross-references, don’t forget to update a stale link, and can touch around fifteen files in a single pass – exactly the kind of tedious upkeep that causes most personal wikis to get abandoned within a few weeks of being started.
The trouble was that everyone solved this llm wiki problem the same way independently, and none of those solutions were compatible with each other. One team’s folder of markdown files looked similar to another’s, but the field names, the linking conventions, and the file structure were all different enough that nothing could be shared without manual rework.
Google’s bet with OKF is that giving this informal pattern an actual specification, instead of leaving every team to reinvent it, is what finally makes it portable.
How a Google Open Knowledge Format Bundle Is Structured
An OKF bundle is simply a folder. Inside it, every piece of knowledge, dataset, metric, API, and operational playbook becomes one Markdown file, called a ‘concept’. The file’s location inside the folder serves as its identity, so there’s no separate ID system to manage.
Picture a customer support team documenting its escalation process: a support/ folder with subfolders for playbooks/, metrics/, and integrations/. A file named playbooks/billing-dispute.md holds the escalation steps, while metrics/first-response-time.md defines how that metric is calculated and where the underlying data lives, plain folders and files, nothing exotic.
At the top of each file sits a short block of YAML, structured fields that stay queryable even though the rest of the document is free-form text:
type: the only field that’s actually requiredtitle: a short, human-readable name for the conceptdescription: a one-line summary of what the concept coversresource: a link back to the original system the concept describestags: optional labels for grouping related conceptstimestamp: when the concept was last updated
Below that block, the rest of the file is ordinary markdown prose, written the way a person would write internal documentation. Files reference one another with regular markdown links, and those links turn a flat folder into something closer to a knowledge graph: an agent reading the billing-dispute playbook can follow a link straight to the metric it depends on, with no separate index needed to connect the two.
Two filenames carry special meaning inside a bundle:
index.mdacts as a summary an agent can read first, deciding whether to descend further into that branch.log.md, where present, keeps a running history of what changed and when: useful for an agent checking whether a concept it’s about to rely on is still current.
Why a Format, Not Another Knowledge Service
The instinct when facing a fragmented-knowledge problem is usually to reach for another tool: a new catalog, a new search index, a new platform to consolidate everything into. Google’s framing pushes back on that instinct directly. The actual gap wasn’t a missing service; it was a missing way to represent knowledge that:
- Anyone can produce it without needing an SDK
- Anyone can consume it without building a custom integration
- Survives moving between systems, organizations, and tools
- Lives in version control alongside the code it describes
- Is readable by a human and parseable by an agent from the same file, with no translation layer in between
OKF is built to be that format, deliberately, rather than another walled-off service competing for the same problem space.
Three Design Rules Behind the Google Open Knowledge Format
Reading Google’s own announcement, three design choices stand out as deliberate trade-offs rather than accidents.
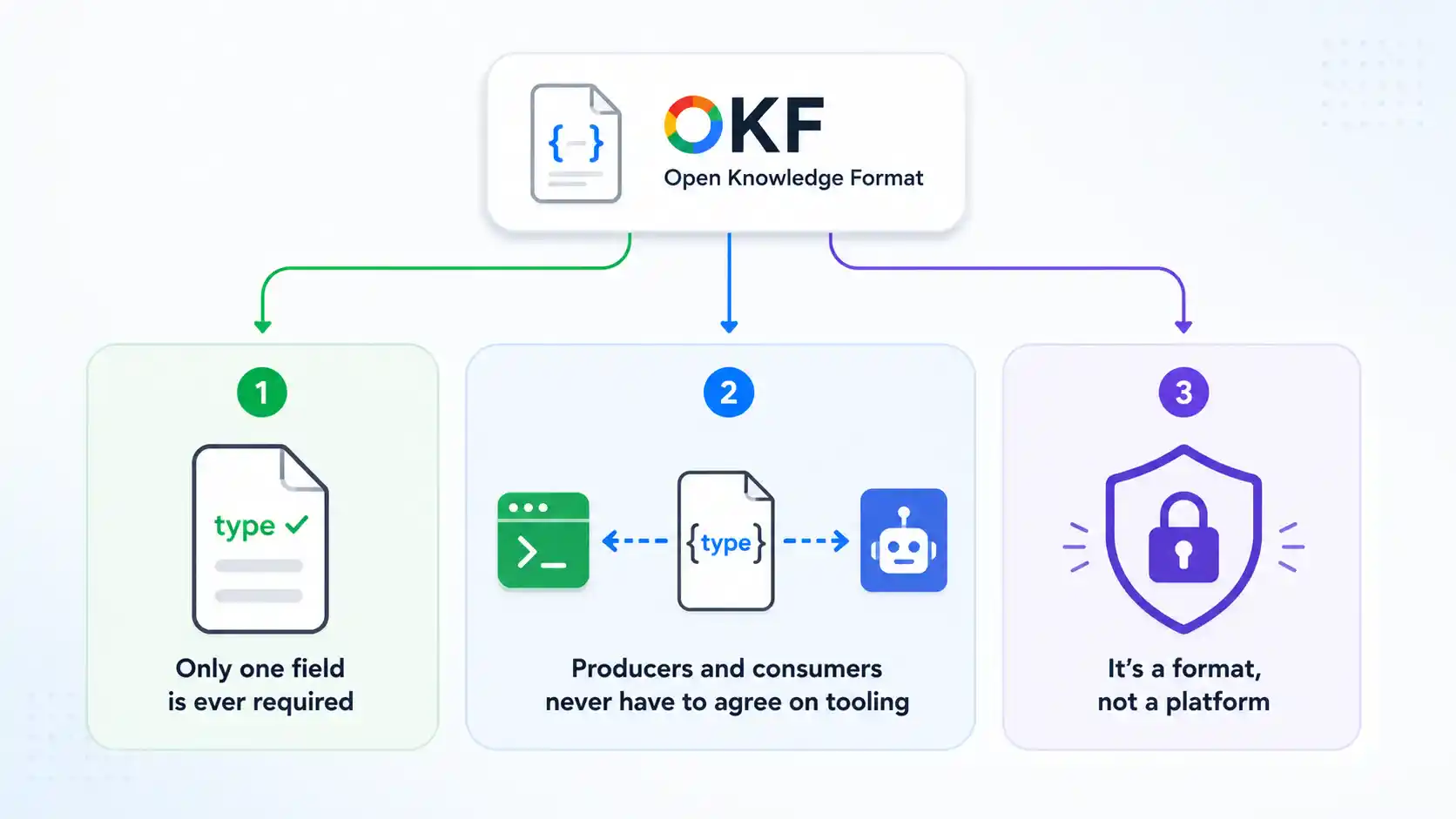
Only one field is ever required. Every OKF concept needs a type value, and nothing else is mandatory. Google standardized the smallest possible surface just enough for interoperability and left what it actually means, what other fields make sense, and how a body should be organized entirely up to whoever is writing the bundle.
Producers and consumers never have to agree on tooling. A bundle written by a person with a text editor should be just as readable to an agent as a bundle generated automatically by a script walking a database. Because the format is the only contract, software on either end can be swapped out independently.
It’s explicitly a format, not a platform. OKF doesn’t ask anyone to sign up for anything: no proprietary runtime, no required account, and no vendor lock-in built into the specification. Google has stated plainly that adoption beyond its own products is the actual goal.
What Google Shipped Alongside the Open Knowledge Format Spec
A specification alone is easy to ignore, so Google paired the OKF announcement with working examples:
- An enrichment agent that walks an existing BigQuery dataset and drafts a starting concept document for every table and view it finds, then runs a second LLM pass that crawls authoritative documentation to add citations, schemas, and join paths.
- A lightweight visual tool that renders any OKF bundle as an interactive, explorable graph, a single file that runs entirely in the browser, with no server and no data leaving the page.
- Three sample bundles built from public datasets covering e-commerce analytics, Stack Overflow data, and Bitcoin transactions, so anyone curious can browse real examples first.
Google frames all of this as one possible implementation, not the only correct one; nothing about the specification requires this particular agent, visualizer, or any specific AI model.
Separately, Google Cloud’s Knowledge Catalog, its metadata management product, now reads OKF bundles directly and makes that knowledge available to agents running inside Google Cloud, a signal that Google is wiring the format into a product its own customers already use, not just publishing a spec and walking away.
Open Knowledge Format Google vs. Retrieval and Existing Wiki Tools
It’s worth being precise about what this format is not, since the comparisons people reach for first aren’t always the right ones. The table below lines up OKF against the approaches it gets compared to most often:
| OKF | Retrieval (RAG) | Obsidian | Notion | Hugo | |
|---|---|---|---|---|---|
| What it stores | Curated, pre-written concepts | Raw text chunks and embeddings | Personal markdown notes | Pages in a proprietary database | Markdown content for static sites |
| When meaning is created | Once, by a person or pipeline | Re-derived at every query | Whenever the author writes it | Whenever the author writes it | Whenever the author writes it |
| Cross-team portability | Built in, by design | Not applicable | Not enforced, vaults vary | Requires manual export | Format-portable, not agent-aware |
| Agent-readable out of the box | Yes | Yes, but answers can drift | Only with custom conventions | Only via API | No, built for human readers |
| Lock-in risk | None, open spec | Depends on the vector store | None, plain files | Tied to the platform | None, plain files |
A few of these differences are worth unpacking. Retrieval-augmented generation searches unstructured text at query time, reconstructing an answer from whatever fragments seem most relevant. That’s useful for open-ended questions, but the same fact can be assembled slightly differently every time it’s queried.
An OKF bundle takes the opposite approach: someone writes the curated, correct version of a fact once, and an agent reads that finished concept directly. For stable institutional knowledge, metric definitions, API contracts, and escalation procedures, that distinction removes an entire category of inconsistency.
Obsidian, Notion, and Hugo solve an adjacent but different problem. Obsidian already stores notes as portable Markdown files, so portability isn’t what OKF adds there; convention is. Two Obsidian vaults built by different teams won’t necessarily share any structure at all.
Notion keeps content inside a proprietary database that must be exported before anything outside Notion can read it. Hugo turns Markdown into a static site, which is great for publishing but says nothing about how an agent should interpret the files underneath.
Neither tool’s writing experience gets replaced here; what’s added is the missing agreement on structure – a required field, reserved filenames, and a linking convention specific enough that a bundle from one team’s tooling opens cleanly in a different team’s agent.
Is Google Open Knowledge Worth Adopting Now?
Google has been upfront that version 0.1 is a starting point, not a finished standard, and that OKF will likely change as real-world usage surfaces gaps the initial design didn’t anticipate. That’s worth taking at face value rather than dismissing as boilerplate.
A few signals suggest this format has a better chance than most newly announced specifications. It asks nothing new of anyone; technically, Markdown and YAML are about as low-friction as a file format gets. It also formalizes something teams were already independently building in slightly different shapes.
And Google has wired it into a product its own teams use internally, meaning there’s at least one serious producer and consumer already depending on it.
Teams running internal copilots against scattered company knowledge, data platform teams maintaining metric definitions across dozens of dashboards, and anyone tired of writing yet another bespoke wiki integration are the most obvious early candidates for OKF. If your organization isn’t yet running agents against its own internal data, this is reasonable to watch rather than rush into adopting this quarter.
Where to Get the Open Knowledge Format Spec and Reference Tools
Everything Google published alongside the announcement is open and free to use, with no signup required. Here’s where to find each piece:
- The full v0.1 specification covers conformance criteria, cross-linking rules, and the reserved filenames and fits on a single page. Available in the Knowledge Catalog repository on GitHub.
- The BigQuery enrichment agent and HTML visualizer: the reference tools described earlier in this article, including the code behind both. Found in the same GitHub repository.
- Three sample bundles: the GA4 e-commerce, Stack Overflow, and Bitcoin datasets, ready to browse before writing a single file of your own.
- Google Cloud’s Knowledge Catalog: Google’s own metadata management product, now updated to ingest this format directly. Worth a look if your team is already on Google Cloud.
Google has explicitly invited outside contributions, alternative implementations, and extensions to the spec, so this isn’t a one-way publication; it’s meant to be built on.
Conclusion
What makes this announcement worth watching isn’t the file format on its own; Markdown with YAML frontmatter is hardly a novel idea. It’s that a major cloud provider has put a name and a versioned specification behind a pattern engineers had already been reinventing independently for over a year.
A few things are worth keeping in mind as OKF moves past its first release:
- It’s still early. Version 0.1 is explicitly a starting point, and the format will likely change as real teams put it to use.
- Adoption isn’t guaranteed. Plenty of well-designed specifications never get traction; this one’s odds improve because it formalizes a pattern engineers had already converged on independently.
- The payoff compounds quietly. If standardization takes hold, the biggest beneficiaries may not be the teams that adopt it directly, but everyone downstream of tools like Obsidian, Notion, and Hugo that eventually add native support for importing and exporting OKF bundles.
For data and platform teams already feeling the pain of scattered context, the practical move is simple: read the spec, try building a small bundle around one team’s documentation, and see whether an agent reads it better than the wiki it replaced. That’s a low-risk way to find out whether OKF earns a permanent place in your stack.
Frequently Asked Questions
What is the Google Open Knowledge Format (OKF)?
An open specification, published by Google Cloud as OKF version 0.1, for representing organizational knowledge as a directory of markdown files with YAML frontmatter, built so AI agents can read that knowledge directly, without a translation step.
What does the LLM wiki pattern mean in Google Open Knowledge Format?
It’s the informal practice of keeping a folder of cross-linked markdown notes that an AI agent can read and update directly, a pattern that predates OKF and that Google’s specification now formalizes into a shared standard.
Does the Open Knowledge Format require any specific software?
No. It’s deliberately a format rather than a platform: no required SDK, no proprietary runtime, and no account needed to read or write a bundle.
How is this different from retrieval-augmented generation?
Retrieval reconstructs an answer from raw text fragments at query time. An OKF bundle stores a single curated, pre-written fact that an agent reads directly, without reassembling it each time.