Table of Contents
Modern software delivery has become a distributed systems problem masquerading as an engineering culture problem.
The average engineering organization today runs dozens of microservices, multiple Kubernetes clusters, several CI/CD pipelines, and a constellation of cloud-native tooling, all maintained by teams that spend a disproportionate amount of time navigating infrastructure instead of shipping product.
According to DORA’s research, elite engineering teams deploy code significantly more frequently than low-performing teams, but that gap isn’t purely a talent gap; it’s an operational leverage gap.
High-performing teams have systematically reduced the friction between a developer’s intent and the production environment.
That reduction in friction has a name: the Internal Developer Platform.
This guide is written for CTOs, principal engineers, and platform engineering leads evaluating whether an IDP belongs in their stack, and how to build or buy one that actually delivers ROI.
What Is an Internal Developer Platform (IDP)?
An Internal Developer Platform is the curated, opinionated layer of tooling, automation, and APIs that an engineering organization builds and maintains to abstract infrastructure complexity away from application developers.
It packages infrastructure provisioning, deployment workflows, observability wiring, secrets management, and policy enforcement into repeatable, self-service primitives that developers can consume without deep platform expertise.
The simplest analogy: an IDP is to your infrastructure what a well-designed SDK is to an external API.
It hides irrelevant complexity, enforces correctness, and accelerates velocity by standardizing the path to production.
Internal Developer Platform vs. Internal Developer Portal
These terms are frequently conflated.
The distinction matters operationally:
| Dimension | Internal Developer Platform | Internal Developer Portal |
|---|---|---|
| Primary purpose | Infrastructure orchestration and automation | Developer-facing UI and discoverability |
| Core function | Provisions, deploys, and manages systems | Displays services, documentation, and ownership |
| Focus | Automation and enforcement | Visibility and navigation |
| Without the other | Hard to use at scale | A dashboard with no backend impact |
A portal without a platform is only a dashboard.
A platform without a portal creates invisible infrastructure that developers can’t discover or reason about.
Production-grade IDPs integrate both layers.
Why Engineering Organizations Are Investing in IDPs
The engineering challenges that IDPs address are not new; they are the accumulated consequences of Kubernetes adoption, microservices proliferation of microservices, and multi-cloud expansion at scale.
Tool sprawl: is the most pervasive symptom. Developers regularly context-switch between eight to twelve distinct tools to deploy a single service: a Git host, a CI system, a container registry, a secrets manager, a Kubernetes dashboard, a cloud console, a monitoring platform, and an incident management system. Each tool has its own authentication model, API surface, and mental model.
Infrastructure bottlenecks: are the operational consequence. When developers can’t self-serve infrastructure, every environment request becomes a ticket routed to a platform or SRE team. At scale, this creates a constant low-grade operational tax on your most expensive headcount.
Slow onboarding: compounds the cost. Without standardized paths to production, new engineers spend weeks learning organizational infrastructure conventions that are tribal knowledge, often undocumented and inconsistently applied.
Kubernetes complexity: deserves specific mention. The Kubernetes abstraction is powerful but low-level. Writing production-grade YAML for deployments, ingress, HPA, Pod Disruption Budgets, RBAC, and Network Policies correctly requires deep expertise. Most application engineers don’t have it and shouldn’t need it.
The business impact of solving these problems is quantifiable:
| Benefit | Business Impact |
|---|---|
| Self-service environments | Reduced dependency on platform team bandwidth |
| Standardized deployment workflows | Fewer production incidents from configuration drift |
| Golden paths | Faster time-to-market for new services |
| Reduced cognitive load | Improved developer satisfaction and retention |
| Policy enforcement at the platform layer | Consistent security and compliance posture |
How Internal Developer Platforms Work
Core Components of an IDP
A production-grade IDP integrates several functional layers:
Developer Portal / UI: The interface through which developers interact with the platform: browsing the service catalog, requesting environments, viewing deployment status, and discovering documentation.
Infrastructure Orchestration Layer: The engine that translates self-service requests into infrastructure actions. This layer interfaces with Kubernetes, cloud provider APIs, and IaC tooling to provision and manage resources declaratively.
CI/CD Integration: IDPs don’t replace CI/CD pipelines; they orchestrate them. When a developer deploys via the platform, the IDP triggers the appropriate pipeline, injecting context such as environment variables, target clusters, and deployment strategies.
Kubernetes Abstraction: A critical layer for organizations running container workloads. Instead of exposing raw Kubernetes manifests, the IDP provides higher-level primitives: “deploy this image to the staging environment with 2 replicas and this environment config.”
Policy and Governance Engine: Enforces organizational standards at request time: resource quotas, approved base images, required security scanning, and network policies. Policies are applied consistently regardless of who initiates the deployment.
Service Catalog: A registry of all services, their owners, their dependencies, and their operational runbooks. Enables discoverability and accelerates incident response.
Observability Stack Integration: Automatically wires deployed services into logging, metrics, and tracing infrastructure, eliminating the manual step that frequently gets skipped under time pressure.
Secrets Management: Centralized, auditable secrets injection rather than scattered .env files and manually rotated credentials.
AI Assistance Layer: Increasingly, IDPs integrate LLM-powered features: natural language infrastructure requests, intelligent deployment recommendations, automated root cause analysis, and AI-generated scaffolding templates.
IDP Architecture: Request Flow
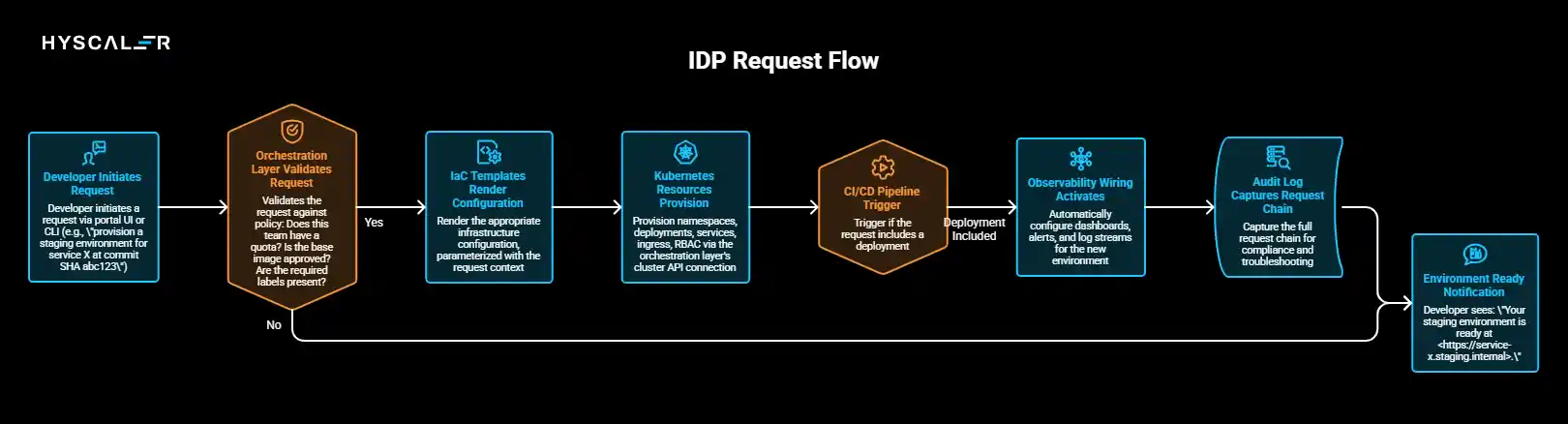
The end-to-end request flow through a well-designed IDP looks like this:
- Developer initiates a request via portal UI or CLI (e.g., “provision a staging environment for service X at commit SHA abc123”)
- Orchestration layer validates the request against policy: Does this team have a quota? Is the base image approved? Are the required labels present?
- IaC templates render the appropriate infrastructure configuration, parameterized with the request context
- Kubernetes resources provision (namespaces, deployments, services, ingress, RBAC) via the orchestration layer’s cluster API connection
- CI/CD pipeline triggers if the request includes a deployment
- Observability wiring activates dashboards, alerts, and log streams, which are automatically configured for the new environment
- Audit log captures the full request chain for compliance and troubleshooting
The developer sees: “Your staging environment is ready at https://service-x.staging.internal.”
Golden Paths Explained
Golden paths are the opinionated, pre-paved deployment workflows that platform teams define to encode organizational best practices.
The term originates from Spotify’s internal platform work and has become a standard concept in platform engineering.
A golden path is not a mandate; it’s a well-maintained road that’s genuinely faster and safer than the alternatives.
The best platform teams make golden paths so ergonomic that developers choose them voluntarily.
Concrete examples of golden paths:
- Microservice deployment template: A parameterized template that provisions a Kubernetes Deployment, Service, HPA, PodDisruptionBudget, and NetworkPolicy with organizational defaults. Developers specify image, resource profile, and environment variables; the rest is handled.
- Kubernetes service template: Standardizes ingress configuration, TLS termination, and service mesh enrollment for any new service.
- AI inference deployment template: A GPU-aware golden path for ML workloads, pre-configured with appropriate node selectors, resource limits, and model artifact mounting.
- Internal API workflow: A complete path from scaffolding to deployment for new internal APIs, including OpenAPI spec validation, contract testing setup, and service catalog registration.
The key insight is that golden paths reduce cognitive load without reducing capability.
Advanced users can still customize; the golden path simply eliminates the default case where developers have to research and assemble configurations from scratch.
Internal Developer Platforms and Kubernetes
Kubernetes accelerated the need for IDPs more than any other technology shift in the past decade.
The platform is extraordinarily powerful, but it exposes enormous complexity to application developers who simply want to deploy and run services.
| Without an IDP | With an IDP |
|---|---|
| Developers write raw YAML manifests | Developers submit higher-level service configurations |
| Infrastructure tickets for every environment | Self-service provisioning in minutes |
| Kubernetes expertise required for deployment | Domain expertise sufficient; platform expertise optional |
| Policy enforcement is manual and inconsistent | Policies enforced automatically at request time |
| RBAC managed per-developer, per-cluster | Role assignments managed at the platform layer |
| Debugging requires kubectl access and knowledge | Observability surfaced in the portal UI |
The abstraction layer that an IDP provides over Kubernetes is one of the clearest ROI arguments for platform engineering investment, particularly as organizations scale past 50 engineers with Kubernetes workloads.
Top Internal Developer Platform Tools in 2026
The IDP tooling landscape has matured significantly.
Most organizations combine a portal layer with an orchestration layer rather than relying on a single monolithic product.
| Platform | Best For | Open Source | Kubernetes Native | Operational Complexity |
|---|---|---|---|---|
| Backstage | Developer portals, service catalog | Yes | Partial | High requires substantial plugin development and maintenance |
| Humanitec | Enterprise platform orchestration | No | Yes | Medium opinionated orchestration model with strong Kubernetes integration |
| Port | No-code IDP builder, rapid customization | No | Yes | Low flexible data model, fast time-to-value |
| Qovery | Kubernetes abstraction for product teams | No | Yes | Medium-strong self-service UX for deployment workflows |
| Cortex | Engineering operations and service maturity | No | Partial | Medium focused on service ownership and scorecards |
| OpsLevel | Service ownership and catalog management | No | Partial | Medium emphasizes service maturity and operational readiness |
Key selection criteria for engineering leadership:
- Backstage: has the largest ecosystem, but demands significant platform engineering investment to maintain. It is a portal framework, not a complete IDP. Plan for a dedicated team.
- Commercial orchestration platforms: (Humanitec, Port, Qovery) reduce build burden substantially and typically reach production value in weeks rather than months.
- Service catalog tools: (Cortex, OpsLevel) are complementary to, not replacements for, an orchestration layer.
Build vs. Buy: The Real Cost Calculation
This is the decision that consumes disproportionate engineering leadership bandwidth, and the answer is rarely binary.
When building an IDP makes sense:
- Your infrastructure patterns are genuinely unique, and no existing abstraction fits
- You have a dedicated platform team (minimum 4–6 engineers) with the capacity to own a product long-term
- Your scale justifies the investment (typically 100+ engineers with complex infrastructure)
When buying makes sense:
- Time-to-value matters (6–12 months vs. 12–24 months for a homegrown platform)
- Your platform team is small or nascent
- Vendor roadmap aligns with your platform engineering maturity trajectory
| Factor | Build | Buy |
|---|---|---|
| Initial investment | High | Medium |
| Time to production value | 12–24 months | 4–12 weeks |
| Ongoing maintenance | Continuous, owned fully | Vendor-managed core, team owns configuration |
| Flexibility | Maximum | Medium constrained by product model |
| Hidden costs | Staffing, on-call, technical debt | Licensing, vendor lock-in risk |
The total cost of building and maintaining an IDP is frequently underestimated.
Factor in: initial engineering time, ongoing feature development, on-call burden, documentation, and the opportunity cost of platform engineers not working on other leverage points.
How to Implement an Internal Developer Platform
Platform engineering adoption fails most often not because of poor tooling choices but because of poor organizational sequencing.
The following roadmap reflects patterns from successful IDP rollouts.
Step 1: Audit developer pain points quantitatively – Survey developers on where they spend non-coding time. Measure ticket volume to platform/infra teams. Identify the three highest-friction workflows; these become your first golden paths.
Step 2: Establish a platform engineering team with a product mindset – The platform is an internal product. It needs an owner, a roadmap, and a feedback loop with its users (your developers). Platform teams that operate purely as infrastructure teams produce platforms that engineers route around.
Step 3: Define initial golden paths – Start with the highest-volume use case, typically: “deploy a new service to staging.” Build the path end-to-end before expanding the scope.
Step 4: Select tooling with a minimally viable platform in mind – Resist the urge to boil the ocean. Start with portal + orchestration + service catalog. Add observability integration, policy enforcement, and AI features incrementally.
Step 5: Standardize incrementally, not mandatorily – Make golden paths attractive, not compulsory. Adoption driven by ergonomics compounds; adoption driven by mandate breeds resentment and shadow infrastructure.
Step 6: Measure developer productivity continuously – Track DORA metrics (deployment frequency, lead time for changes, MTTR, change failure rate), infrastructure provisioning time, and developer satisfaction (via regular surveys). Tie platform investments to measurable outcomes.
Step 7: Scale adoption through champions, not mandates – Identify early adopters in each product team. Make their success visible. Let social proof drive broader adoption.
Platform Engineering Maturity Model
| Level | Characteristics |
|---|---|
| Level 1 Manual DevOps | Ad-hoc infrastructure provisioning; no standardized deployment process; heavy platform team dependency |
| Level 2 Basic Automation | CI/CD pipelines exist; IaC is used inconsistently; some golden path thinking, but not productized |
| Level 3 Self-Service Platform | Developers provision environments without tickets; golden paths defined and adopted; service catalog operational |
| Level 4 Intelligent Platform | Policy enforcement automated; observability wired at provision time; platform metrics tracked systematically |
| Level 5 AI-Augmented Platform | LLM-assisted development workflows; autonomous operations for routine tasks; predictive infrastructure scaling |
Most organizations with 50–200 engineers sit at Level 2.
The transition from Level 2 to Level 3 delivers the largest developer experience improvement per unit of platform investment.
AI and LLM Integration in Internal Developer Platforms
AI integration in IDPs is no longer speculative; it is actively being deployed in production platform engineering environments.
The integration patterns fall into several categories:
AI copilots for infrastructure requests: Natural language interfaces that translate developer intent (“I need a staging environment for the payments service with a Postgres 15 database and Redis cache”) into validated, policy-compliant infrastructure configurations. This dramatically reduces the learning curve for new engineers.
Intelligent deployment recommendations: AI models trained on your deployment history can flag anomalous configurations, recommend resource sizing based on similar services, and predict failure modes before deployments reach production.
Automated troubleshooting: LLM-assisted root cause analysis that correlates deployment events with observability signals and surfaces actionable hypotheses, reducing MTTR without requiring senior engineer intervention on every incident.
AI-generated scaffolding templates: On-demand generation of golden path templates for new service archetypes, customized to your organizational conventions and reviewed by platform teams before publishing.
Natural language runbook generation: Automatically generating operational runbooks from deployment configurations and historical incident data, keeping documentation synchronized with infrastructure reality.
The forward trajectory for 2026 and beyond points toward agentic DevOps: AI agents capable of autonomously executing multi-step operational workflows, scaling infrastructure in response to anomalies, rolling back deployments on degraded signals, and provisioning environments in response to pull request creation with human approval gates for high-impact actions.
Security and Compliance in Internal Developer Platforms
A well-designed IDP is a compliance force multiplier: by centralizing the path to production, you centralize the enforcement of security controls.
RBAC at the platform layer – Role definitions in the IDP (developer, team lead, platform admin) map to Kubernetes RBAC, cloud IAM policies, and secrets access controls. Engineers get least-privileged access by default without manual configuration.
Policy-as-code enforcement – Tools like OPA/Gatekeeper or Kyverno integrate into the IDP’s orchestration layer to enforce policies at admission: required labels, approved base images, resource limit requirements, network policy mandates. Violations are surfaced at deployment request time, not discovered in production audits.
Secrets management integration – Centralized secrets (Vault, AWS Secrets Manager, GCP Secret Manager) injected at runtime, with audit logs for every access event. Eliminates the proliferation of long-lived credentials in environment variables and config files.
Audit logging – Every infrastructure action, environment provisioning, deployment, configuration change, and secrets access should produce an immutable audit event. Essential for SOC 2, HIPAA, and ISO 27001 compliance evidence.
Zero trust network architecture – IDPs that manage service mesh enrollment (Istio, Linkerd) can enforce mutual TLS between services and apply zero trust policies by default on every newly provisioned service.
Measuring IDP Success
Platform engineering investment is only defensible if it produces measurable outcomes.
The metrics that matter:
DORA Metrics (the industry standard for software delivery performance):
- Deployment frequency
- Lead time for changes
- Mean time to recovery (MTTR)
- Change failure rate
Platform-specific metrics:
- Infrastructure provisioning time (target: under 10 minutes for standard environments)
- DevOps ticket volume to platform team (target: declining quarter-over-quarter)
- Developer onboarding time to first deployment
- Golden path adoption rate (% of deployments using standardized workflows)
- Developer satisfaction score (measured via quarterly surveys)
The most impactful leading indicator is often the simplest: how long does it take a new engineer to deploy their first change to a production-like environment?
Elite organizations measure this in hours.
Most measure it in days.
An IDP should move that number decisively toward hours.
Common Internal Developer Platform Mistakes
Overengineering the initial platform: Building a five-layer platform before validating that developers will use it is the most common failure mode. Start with one golden path used by one team. Ship it. Iterate.
Building a platform without a product owner: Infrastructure-minded platform teams frequently underinvest in developer experience. The IDP’s UX, its CLI ergonomics, portal design, and error messages determine adoption. Treat it as a product.
Ignoring developer feedback loops: Platforms built without continuous developer input accumulate misalignment. Ship a feedback mechanism (a Slack channel, a monthly office hours session, an embedded survey) before you ship the first feature.
Enforcing golden paths before they’re ready: Mandating the adoption of immature golden paths is a guaranteed way to generate resentment and shadow infrastructure. The path should be mature and demonstrably better before it becomes required.
Measuring output instead of outcomes: Platform teams that report “we deployed X features” instead of “deployment frequency increased by Y%” lose organizational credibility quickly. Instrument your platform’s impact from day one.
Conclusion
Internal Developer Platforms have crossed from forward-looking infrastructure investment to table stakes for engineering organizations operating at scale.
The compounding returns of standardized, self-service infrastructure, faster deployments, reduced cognitive load, consistent compliance posture, and better developer retention are measurable, well-documented, and increasingly hard to ignore as engineering organizations scale past 50–100 engineers.
The practical implication for engineering leadership in 2026 is not whether to invest in platform engineering, but how to sequence that investment intelligently: what pain points to solve first, what tooling to build versus buy, how to measure success, and how to maintain the developer feedback loops that separate high-adoption platforms from expensive infrastructure no one uses.
The organizations shipping fastest in 2026 have not just adopted Kubernetes, microservices, and cloud-native tooling; they have built the internal platforms that make those technologies accessible to every engineer on their team, not just the ones who wrote the YAML.
Explore how modern platform engineering practices improve developer productivity, reduce operational complexity, and accelerate cloud-native software delivery.
FAQ
What is the difference between IDP and DevOps?
DevOps is a philosophy and set of practices for aligning development and operations. An IDP is a product that implements those practices at scale through automation and self-service tooling. DevOps describes the “what”; an IDP is part of the “how” at the organizational scale.
Is Backstage an IDP?
Backstage is a developer portal framework that provides the UI and plugin ecosystem for building a portal layer. It is not, by itself, a complete IDP. Most Backstage deployments require integration with separate orchestration tooling to become a functional platform.
What are golden paths?
Golden paths are opinionated, pre-built deployment and development workflows that encode organizational best practices. They’re designed to be the fastest and safest way to accomplish common tasks, reducing cognitive load without eliminating flexibility for advanced use cases.
How much does an IDP cost?
Build costs vary widely: a homegrown IDP typically requires 12–24 months of engineering time from a 4–6 person team. Commercial platforms range from $20K to $300K+ annually, depending on scale and feature set. The more relevant cost comparison is the total cost of ownership, including developer time lost to infrastructure friction, which an IDP reduces.
Are IDPs only for Kubernetes?
No, but Kubernetes environments benefit most visibly from IDP adoption due to YAML complexity and operational surface area. IDPs are valuable in any environment with significant infrastructure complexity, multi-cloud operations, or high developer-to-platform-engineer ratios.
Can smaller engineering teams benefit from IDPs?
Yes, but the ROI curve changes. Teams under 30 engineers typically benefit more from lightweight tooling (standardized CI/CD templates, basic self-service scripts) than from a full platform engineering investment. The inflection point where a dedicated platform team delivers positive ROI is typically 50–80 engineers.
How do AI tools integrate with IDPs?
AI integration occurs at multiple layers: natural language interfaces for infrastructure requests, LLM-assisted configuration generation, intelligent anomaly detection in observability pipelines, and AI-powered runbook generation. The most mature integrations today center on developer productivity (scaffolding, configuration assistance) rather than autonomous operations.