Table of Contents
The promise of artificial intelligence has never been more tangible.
Yet for every breakthrough AI deployment making headlines, dozens of projects quietly fail in corporate corridors around the world.
The difference between success and failure rarely lies in the sophistication of the algorithm; it lies in how well organizations manage the complete AI lifecycle.
Why Most AI Projects Fail
Around 85% of AI projects never reach production, and many that do fail to deliver long-term value.
The issue isn’t technology or talent, it’s approach.
Most organizations treat AI like traditional software, building models in isolation without considering the full ecosystem required to sustain them.
The result? Projects stall during deployment, degrade over time, or fail to solve real business problems.
The Real Problem
AI isn’t static.
Models evolve with data and can quickly lose accuracy if not continuously monitored and maintained.
A model at 95% accuracy today can drop significantly as real-world conditions change.
The Lifecycle Imperative
Success requires managing the entire AI lifecycle, from problem definition and data preparation to deployment, monitoring, and governance.
Each stage is interconnected, and neglecting one can break the system.
Who This Is For
Built for CIOs, AI leaders, MLOps teams, and product managers scaling AI effectively.

What Is the AI Lifecycle?
The AI lifecycle is the end-to-end journey of an AI system, from idea to deployment to retirement.
It’s not linear but continuous: production insights drive improvements, monitoring triggers retraining, and business needs keep reshaping the system.
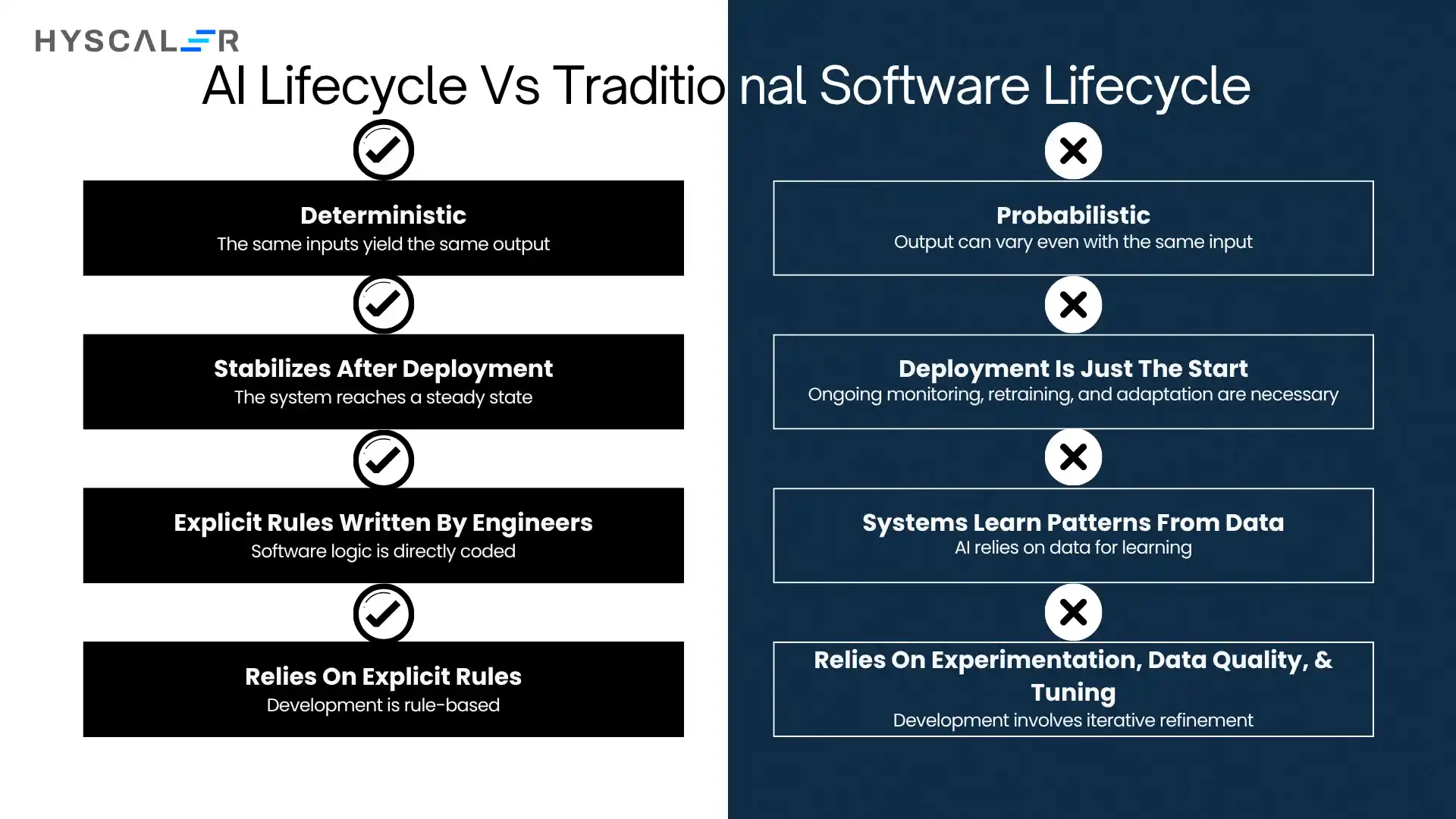
AI Lifecycle vs Traditional Software Lifecycle
Traditional software is deterministic (same input → same output) and stabilizes after deployment.
AI systems are probabilistic, evolving with data.
Deployment is just the start; models require ongoing monitoring, retraining, and adaptation due to issues like model drift.
Development also differs:
- Software = explicit rules written by engineers
- AI = systems learn patterns from data, relying on experimentation, data quality, and tuning
Relationship with Machine Learning and MLOps
- Machine Learning (ML): The core technology enabling predictions and pattern recognition
- MLOps: The operational layer that automates deployment, monitoring, and retraining
The AI lifecycle is broader, and it includes strategy, governance, ethics, and business alignment, with MLOps acting as its execution backbone.
Key Stages of the AI Lifecycle
1. Problem Definition
Start with a clear business problem, not the model.
Define measurable outcomes tied to real value.
- Metrics: Quantifiable (e.g., reduce resolution time by 30%)
- Automation vs Augmentation: Decide the role of AI early
- ROI: Align with cost, impact, and long-term value
2. Data Collection & Preparation
Data quality drives success.
- Sourcing: Use relevant internal + external data
- Cleaning: Fix missing, inconsistent, or biased data
- Feature Engineering: Turn raw data into meaningful signals
- Governance: Ensure compliance and data control
Biggest bottleneck: poor data quality
3. Model Development
Iterative experimentation to find the best model.
- Algorithm Selection: Based on use case + constraints
- Training & Validation: Prevent overfitting
- Experiment Tracking: Ensure reproducibility
- Tools: TensorFlow, PyTorch, Scikit-learn
4. Evaluation & Validation
Measure performance beyond accuracy.
- Metrics: Precision, recall, F1, business impact
- Bias & Fairness: Detect and mitigate bias
- Explainability: Build trust and transparency
- Regulation: Meet compliance requirements
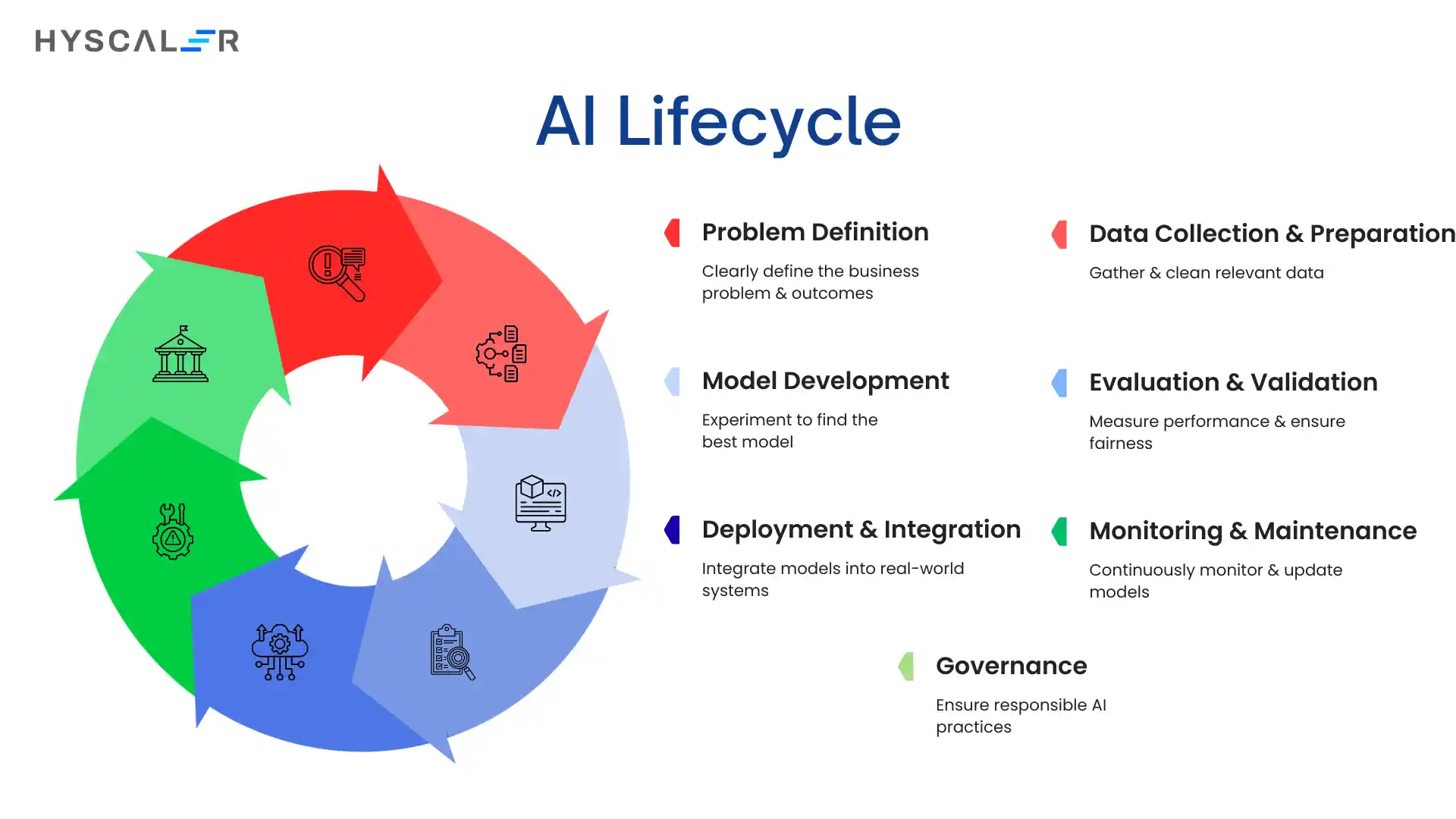
5. Deployment & Integration
Turn models into real-world systems.
- Batch vs Real-time: Based on latency needs
- CI/CD for ML: Automate pipelines
- APIs: Enable integration
- Edge vs Cloud: Balance speed, cost, and privacy
6. Monitoring & Maintenance
AI needs continuous care.
- Model Drift: Detect performance decline
- Data Drift: Track input changes
- Performance Monitoring: Watch key metrics
- Retraining: Update models regularly
- LLMOps: Manage prompts, cost, and outputs
7. Governance (Cross-Lifecycle)
Ensures responsible AI at every stage.
- Responsible AI: Fairness, transparency, accountability
- Risk Management: Identify and mitigate risks
- Security & Privacy: Protect data and models
- Auditability: Track decisions and changes
- Regulations: Stay compliant globally
AI Lifecycle vs MLOps vs LLMOps
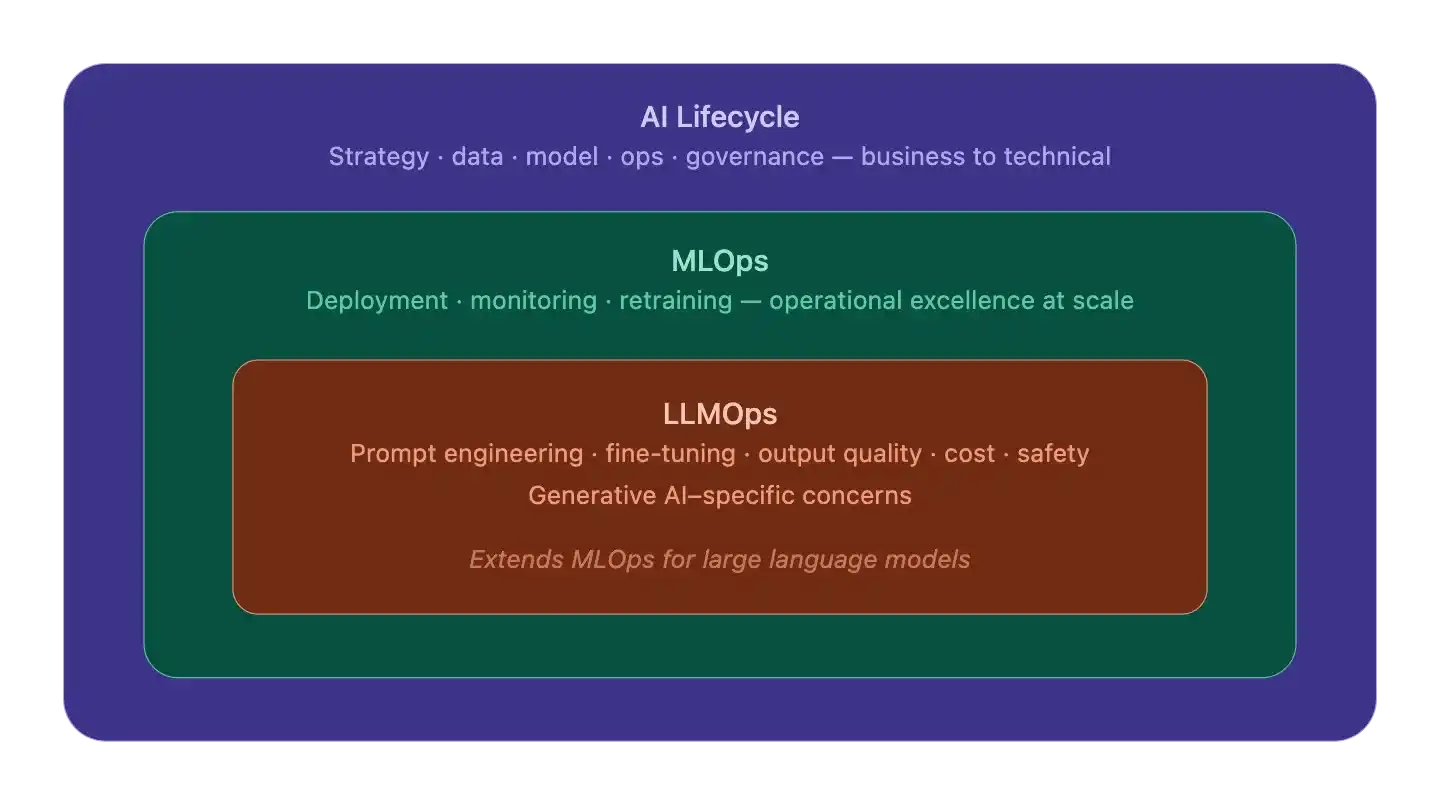
Three nested layers, each building on the one outside it:
AI Lifecycle is the outermost frame – the full journey from business problem to governance. It sets the why and what.
MLOps lives inside that – it’s how you operationalize any ML model reliably: deployment pipelines, monitoring, retraining loops.
LLMOps is the innermost layer – MLOps extended for generative AI’s quirks: prompt management, inference cost, safety guardrails, output quality.
They’re not competing alternatives.
Think of it as: the lifecycle gives direction, MLOps provides the engine, and LLMOps provides the specialized components for working with LLMs.
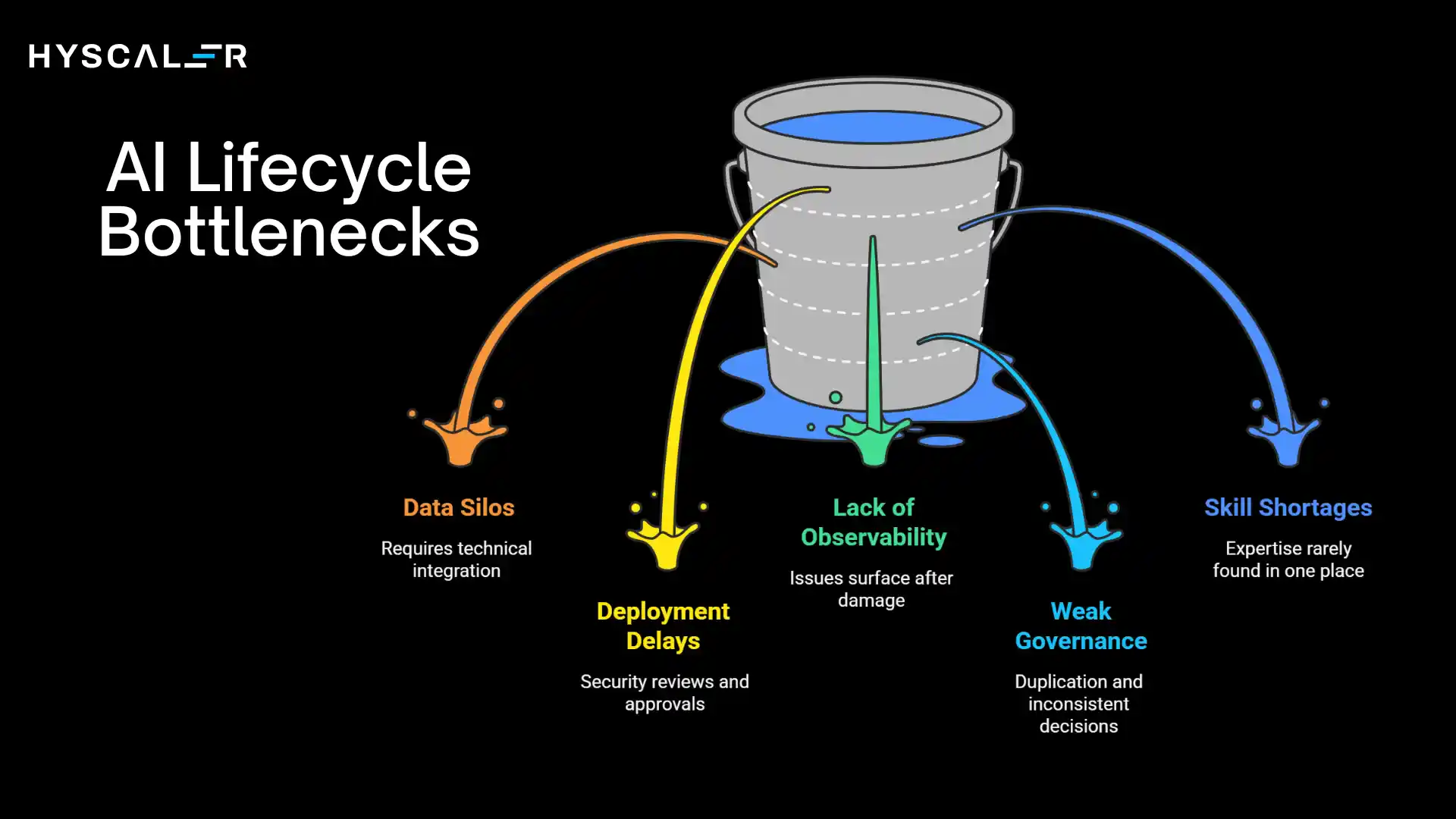
Common AI Lifecycle Bottlenecks
Data Silos
Customer, transaction, and interaction data trapped in separate systems require technical integration, organizational alignment, and governance negotiations to unify.
Solutions: executive sponsorship, clear data ownership policies, and integration platforms.
Deployment Delays
Models validated in development can take months to reach production due to security reviews, approvals, and cross-team handoffs.
Solutions: MLOps automation, streamlined approvals, and standardized deployment patterns.
Lack of Observability
Deploying models without monitoring means issues only surface after damage is done.
Solutions: instrument prediction distributions, performance metrics, and business outcomes from day one with dashboards and alerts.
Weak Governance
Without clear policies, teams duplicate work, make inconsistent ethical decisions, and create compliance risks.
Solutions: establish standards, risk-tiered review processes, and approval gates that balance control with agility.
Skill Shortages
AI requires expertise across data engineering, ML, DevOps, ethics, and business strategy, rarely found in one place.
Solutions: strategic hiring, university partnerships, staff upskilling, and platforms that abstract complexity.
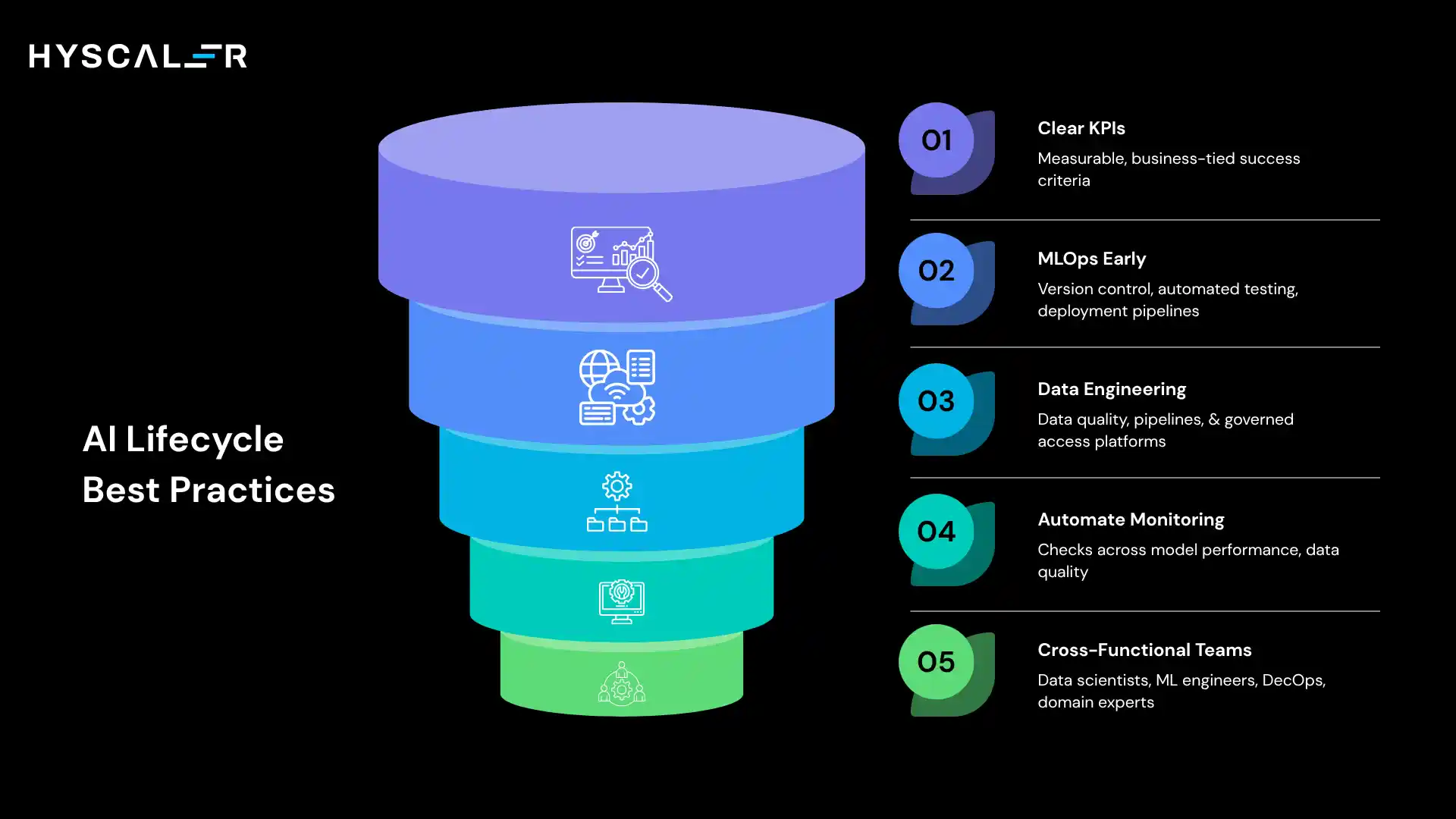
Best Practices for Managing the AI Lifecycle
Start with Clear KPIs
Define measurable, business-tied success criteria before development begins, agreed upon by both technical and business stakeholders.
Avoid vague goals and document any changes deliberately rather than chasing favorable metrics.
Implement MLOps Early
Don’t wait for scaling problems to adopt MLOps.
Start from the first model with version control, experiment tracking, automated testing, and deployment pipelines.
Early habits prevent technical debt later.
Invest in Data Engineering
Data quality matters more than algorithm sophistication.
Build pipelines, quality-monitoring systems, data catalogs, and governed-access platforms.
Skimping on this foundation guarantees ongoing struggles.
Automate Monitoring
Manual monitoring doesn’t scale.
Automate checks across model performance, data quality, system health, and business metrics.
Use alerts, dashboards, and logs to catch issues early and enable continuous improvement.
Build Cross-Functional Teams
AI requires data scientists, ML engineers, DevOps, domain experts, legal, and product managers working together.
Co-locate or establish strong communication channels, and align everyone around shared objectives to prevent siloed thinking.
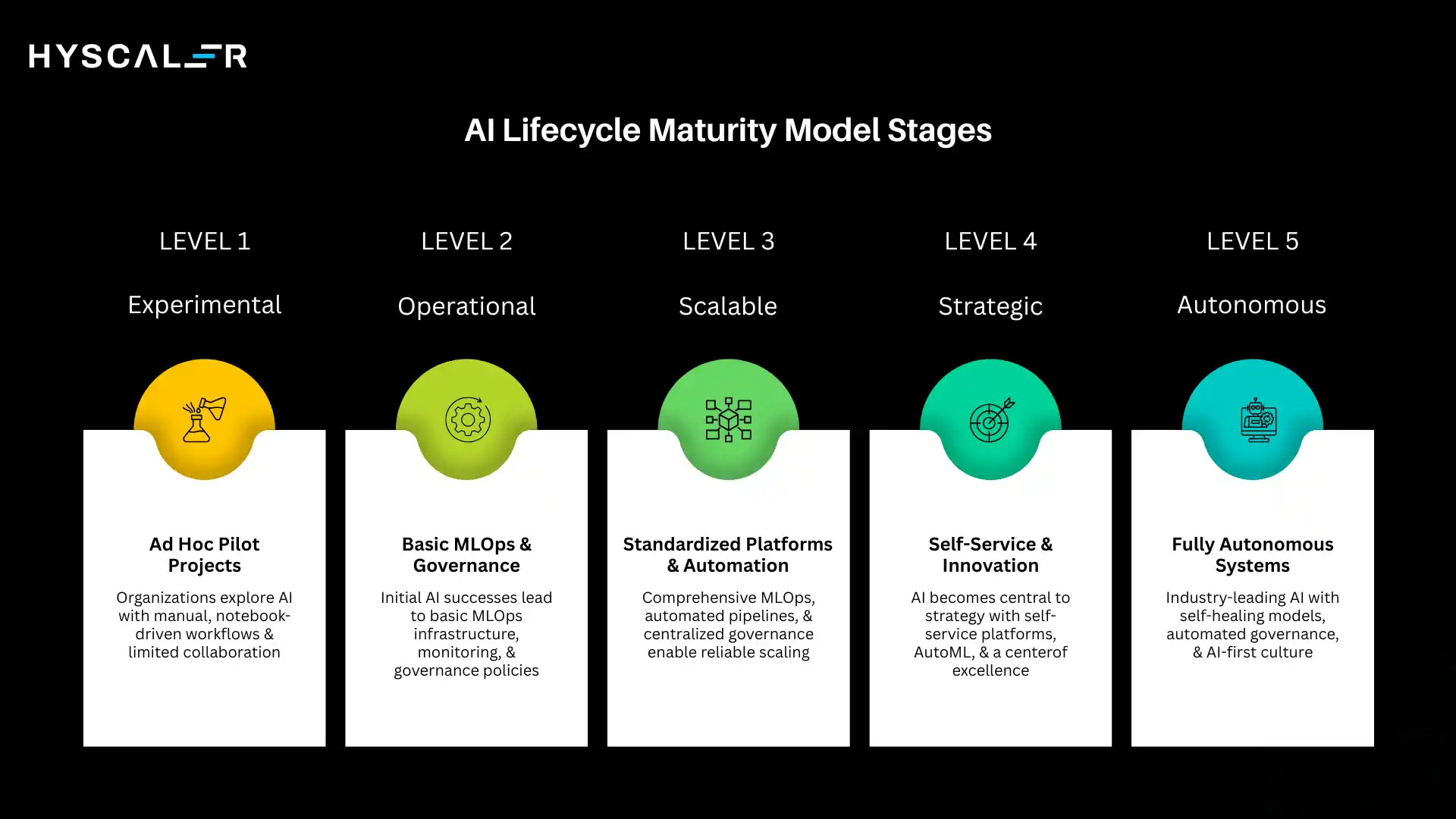
AI Lifecycle Maturity Model
Organizations progress through distinct maturity stages as they develop AI capabilities.
Understanding these stages helps set realistic expectations and identify improvement opportunities.
Experimental (Level 1)
Organizations at this foundational level are exploring AI through pilot projects and proofs of concept.
Ad hoc efforts lack standardized processes, with individual data scientists working independently on isolated problems.
Success depends heavily on individual expertise rather than organizational capabilities.
Key Characteristics:
- Manual, notebook-driven development workflows
- No formal model deployment processes
- Limited collaboration and knowledge sharing
- Siloed data access with manual integration
- No systematic monitoring or retraining
Metrics:
- Models in production: 0-2
- Time to deploy: 6+ months
- Model reuse: <10%
- Governance: Informal
Operational (Level 2)
Initial AI successes motivate establishing basic operational capabilities.
The organization deploys some models to production and begins developing repeatable processes, though significant manual intervention remains necessary.
Key Characteristics:
- Basic MLOps infrastructure for deployment
- Simple monitoring and alerting
- Initial governance policies
- Departmental data platforms
- Small dedicated AI teams
Metrics:
- Models in production: 3-10
- Time to deploy: 3-6 months
- Model reuse: 10-30%
- Governance: Basic policies established
Scalable (Level 3)
The organization has proven AI value and built infrastructure supporting multiple teams deploying models reliably.
Standardized platforms, automated workflows, and clear processes enable scaling while maintaining quality.
Key Characteristics:
- Comprehensive MLOps platform
- Automated training and deployment pipelines
- Centralized monitoring and governance
- Enterprise data lake/warehouse
- Multiple AI teams with defined roles
Metrics:
- Models in production: 10-50
- Time to deploy: 2-8 weeks
- Model reuse: 30-50%
- Governance: Comprehensive framework
Strategic (Level 4)
AI becomes central to business strategy, with capabilities that create competitive advantages.
The organization systematically identifies AI opportunities, rapidly deploys solutions, and continuously improves performance.
Data and AI literacy pervade the company culture.
Key Characteristics:
- Self-service platforms enabling citizen data scientists
- Advanced AutoML and automated feature engineering
- Real-time monitoring with automated responses
- Federated data mesh architecture
- Center of excellence driving innovation
Metrics:
- Models in production: 50-200
- Time to deploy: Days to weeks
- Model reuse: 50-70%
- Governance: Embedded in workflows
Autonomous (Level 5)
The organization achieves industry-leading AI capabilities with largely autonomous systems that continuously learn, adapt, and improve with minimal human intervention.
AI and human intelligence synergize seamlessly.
Key Characteristics:
- Autonomous experimentation and optimization
- Self-healing models with automatic drift detection and retraining
- Continuous governance with AI-driven compliance
- Real-time data fabric with intelligent orchestration
- AI-first culture with pervasive automation
Metrics:
- Models in production: 200+
- Time to deploy: Hours to days
- Model reuse: 70-90%
- Governance: Automated with continuous compliance
Few organizations currently operate at Level 5, representing an aspirational state enabled by emerging technologies.
Most enterprises currently function at Levels 2-3, working toward Level 4 capabilities.
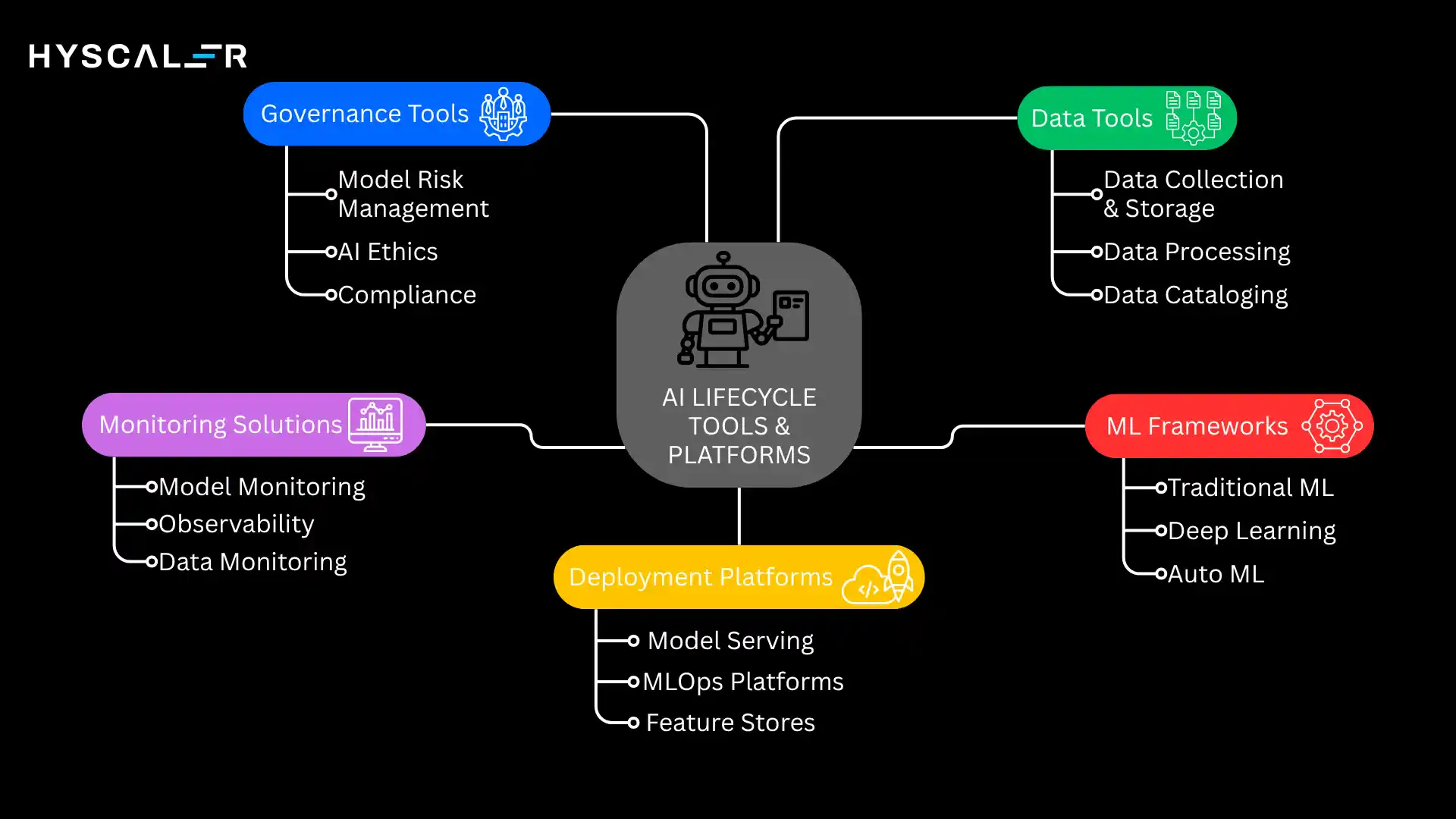
AI Lifecycle Tools & Platforms
The ecosystem offers specialized tools supporting each lifecycle stage.
Strategic tool selection balances capabilities, integration, costs, and organizational needs.
Data Tools
Data Collection & Storage:
- Cloud data warehouses: Snowflake, Google BigQuery, Amazon Redshift
- Data lakes: Azure Data Lake, AWS S3, Google Cloud Storage
- Streaming platforms: Apache Kafka, Amazon Kinesis, Google Pub/Sub
Data Processing:
- Batch processing: Apache Spark, Apache Beam, Databricks
- ETL/ELT: Fivetran, Airbyte, dbt
- Data quality: Great Expectations, Monte Carlo, Anomalo
Data Processing:
- Alation, Collibra, Amundsen
- Metadata management and data discovery, enabling self-service
ML Frameworks
Traditional ML:
- Scikit-learn: Comprehensive library for classical algorithms
- XGBoost, LightGBM, CatBoost: Gradient boosting implementations
Deep Learning:
- TensorFlow/Keras: Google’s framework with a high-level API
- PyTorch: Facebook’s framework favored by researchers
- JAX: High-performance numerical computing
AutoML:
- H2O.ai, DataRobot, Google AutoML
- Automated feature engineering, model selection, and hyperparameter tuning
Deployment Platforms
Model Serving:
- TensorFlow Serving, TorchServe: Framework-specific serving
- Seldon Core, KServe: Kubernetes-native deployment
- SageMaker, Azure ML, Vertex AI: Cloud platform solutions
MLOps Platforms:
- MLflow: Open-source experiment tracking and model management
- Kubeflow: End-to-end ML workflows on Kubernetes
- Weights & Biases: Experiment tracking and collaboration
- Neptune.ai: Metadata store for ML
Feature Stores:
- Feast, Tecton, Hopsworks
- Centralized feature management enabling reuse and consistency
Monitoring Solutions
Model Monitoring:
- Arize AI, Fiddler, WhyLabs
- Drift detection, performance tracking, and explainability
Observability:
- Datadog, New Relic, Grafana
- System metrics, logging, tracing
Data Monitoring:
- Monte Carlo, Bigeye, Databand
- Data quality and pipeline observability
Governance Tools
Model Risk Management:
- ValidMind, Credo AI, Fiddler
- Validation, documentation, bias testing
AI Ethics:
- IBM AI Fairness 360, Google What-If Tool
- Fairness testing and explainability
Compliance:
- OneTrust, TrustArc
- Privacy management and regulatory compliance
The optimal stack depends on organization size, cloud strategy, technical expertise, budget, and specific requirements.
Many organizations adopt cloud platform solutions (AWS SageMaker, Azure ML, Google Vertex AI), providing integrated capabilities, while others assemble best-of-breed tools for flexibility.
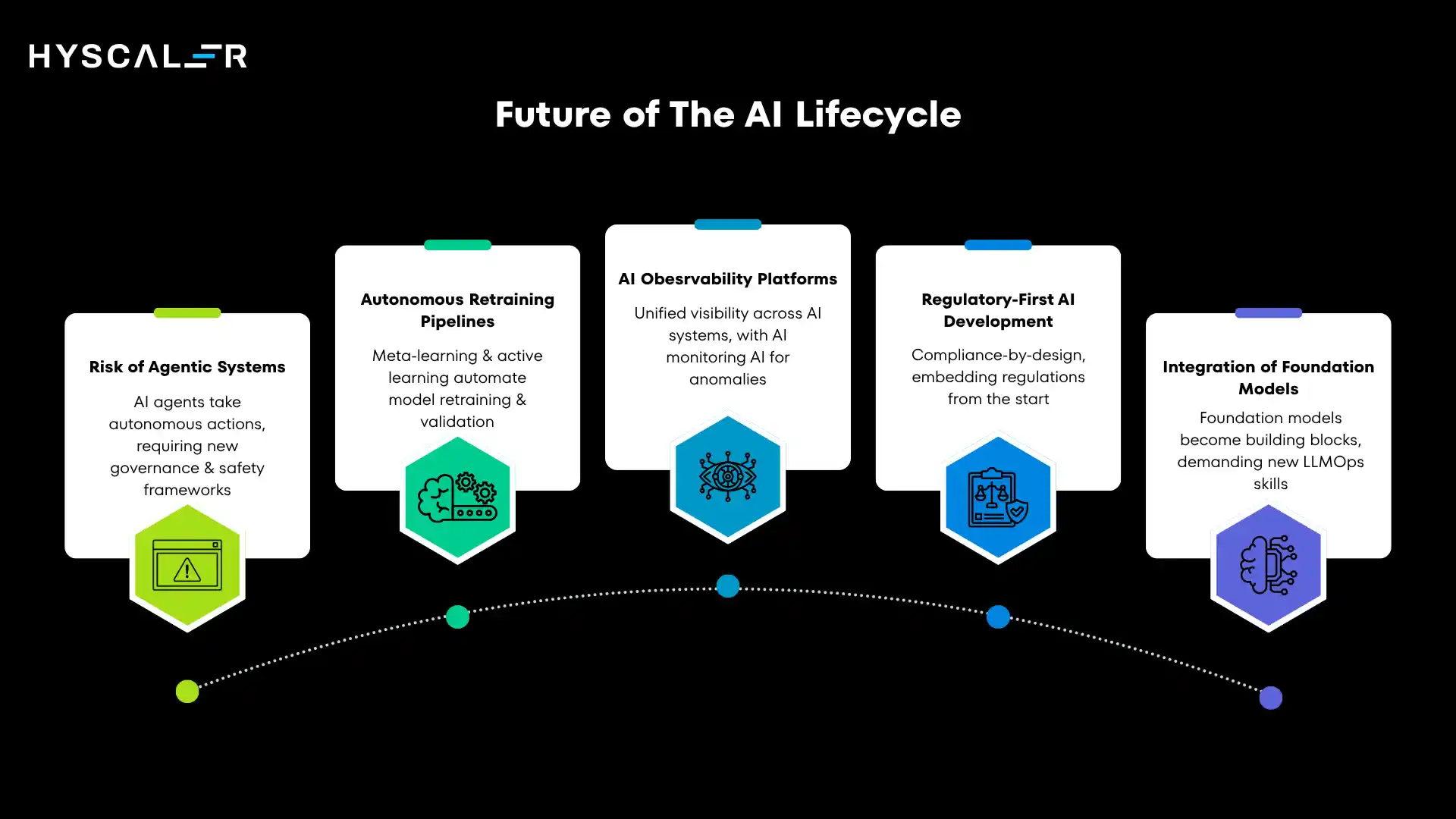
Future of the AI Lifecycle (2026 and Beyond)
The AI landscape continues evolving rapidly. Several trends will reshape how organizations manage AI lifecycles in the coming years.
Rise of Agentic Systems
AI is shifting from passive prediction to autonomous agents that take actions, use tools, retain memory, and pursue goals with minimal supervision.
This introduces new lifecycle challenges: aligning agents to intended objectives, enforcing safety constraints, coordinating multi-agent interactions, and establishing accountability for autonomous decisions.
Organizations will need governance frameworks defining when agents can act independently versus requiring human approval, along with monitoring and intervention mechanisms for when behavior goes off course.
Autonomous Retraining Pipelines
Current model retraining typically requires human oversight, analyzing drift reports, approving retraining, and validating new models.
Emerging systems automate these decisions using meta-learning approaches that determine when retraining is necessary, active learning to select which new data provides the most value, and automated validation to ensure new models improve over existing versions.
These capabilities enable models to continuously adapt to changing patterns while maintaining safety through automated testing and rollback mechanisms.
Organizations will shift from scheduled retraining to continuous learning systems that evolve in near real-time.
AI Observability Platforms
As AI systems grow more complex, next-generation observability platforms will provide unified visibility across models, data pipelines, infrastructure, and business outcomes, linking technical metrics directly to business impact.
Increasingly, AI will monitor AI: using machine learning to detect anomalies, predict failures, identify root causes, and recommend fixes, enabling human operators to manage complex AI ecosystems through AI-powered tools.
Regulatory-First AI Development
Unregulated AI experimentation is giving way to compliance-by-design, embedding regulatory requirements into development from the start rather than retrofitting them later.
This requires technical capabilities like differential privacy, federated learning, formal verification, and explainable AI.
Compliance specialists now participate throughout the entire lifecycle, not just at the end.
Automated compliance tools are becoming essential for navigating complex, multi-jurisdictional requirements.
Integration of Foundation Models
Foundation models like GPT-4, Claude, and Gemini are becoming building blocks within larger AI systems rather than standalone tools.
Organizations increasingly combine them with proprietary data, fine-tuning, retrieval-augmented generation (RAG), and traditional ML models.
This hybrid approach demands new skills: prompt engineering, efficient fine-tuning, vector database management, multi-model orchestration, and inference cost optimization, making LLMOps a standard part of enterprise AI infrastructure.
Conclusion
Enterprise AI success isn’t primarily a technology challenge; it’s a lifecycle management challenge.
Organizations win not by building the most sophisticated models, but by creating robust processes that sustain business value in production.
AI Success Equals Lifecycle Optimization
Every deployment reflects thousands of decisions across the lifecycle.
No single area of excellence compensates for weakness elsewhere; the best model fails if deployment takes six months, and perfect data means nothing if monitoring misses drift.
Success requires optimizing the entire system, from business need through development, deployment, and continuous improvement.
That demands investment in infrastructure, processes, and culture, less glamorous than algorithms, but far more impactful.
Models Don’t Fail, Workflows Do
When AI initiatives stumble, the model is rarely the culprit.
Failures trace back to ill-defined problems, undetected data quality issues, deployment delays, missed drift, or absent retraining infrastructure, each a workflow breakdown.
Preventing failures means systematically strengthening every lifecycle stage and connecting them through feedback loops.
Continuous Improvement Mindset
The AI lifecycle is never finished.
Models degrade, patterns shift, business needs evolve, and regulations change.
Treat the lifecycle itself as a product: regularly identify bottlenecks, invest in automation, learn from successes and failures, and stay current with emerging practices.
The organizations that lead in AI won’t be those with the largest teams or most powerful infrastructure; they’ll be the ones that master the complete lifecycle, turning AI potential into consistent business results.
FAQs
How long does it typically take to deploy an AI model to production?
Timelines vary by maturity and complexity. Early-stage organizations may take 6+ months, mid-level 3-6 months, while mature teams can deploy in weeks or even days. Most delays come from data preparation and deployment, not model development.
What’s the difference between model drift and data drift?
Data drift is when input data changes over time (e.g., shifts in customer behavior or values). Model drift (concept drift) is when the relationship between inputs and outputs changes. Both hurt performance; data drift often needs retraining, while model drift may require redesigning features or the model itself.
Do we need separate teams for MLOps and LLMOps?
Not necessarily. LLMOps is a specialization within MLOps. Smaller teams can manage both together, while larger organizations with heavy generative AI use may need dedicated LLMOps experts for prompts, fine-tuning, and safety, working alongside MLOps teams.
How often should models be retrained?
There’s no fixed retraining schedule; it depends on data change and business impact. Some models need updates rarely, others frequently. Start with scheduled retraining, but add monitoring to trigger updates based on performance drops or data drift, then shift to fully performance-driven retraining.
What’s the minimum team size needed to implement MLOps?
Even a single data scientist can start MLOps with basics like version control, experiment tracking (e.g., MLflow), testing, and simple pipelines. As you scale to 3–5 models, add ML engineering support; at 10+, dedicated MLOps teams are needed. Start early with lightweight automation to avoid future bottlenecks.
How do we measure ROI for AI lifecycle investments?
Measure ROI through both direct and indirect impact. Direct gains include faster deployment, lower costs, fewer failures, and better model performance. Indirect gains include higher productivity, more model reuse, less technical debt, faster experimentation, and improved compliance. Track metrics like deployment frequency, incident rates, recovery time, and production adoption, and link them to business outcomes like revenue, cost savings, and risk reduction.
Should we build or buy our AI lifecycle platform?
Most organizations should start with managed platforms like AWS SageMaker, Azure Machine Learning, or Google Vertex AI, or use proven open-source tools. Building custom platforms is only worthwhile for highly specialized needs with strong engineering support. Start with existing solutions for speed, then add custom components where needed.
How do we handle AI governance without slowing down innovation?
Effective governance drives sustainable innovation. Use risk-based oversight, automate compliance in workflows, and provide clear guidelines and templates. Support teams with centers of excellence, the goal is to make the right, compliant approach the easiest one.
What skills are most critical for managing the AI lifecycle?
Success in AI requires both technical and organizational strength. Key technical skills include data, ML, software, and cloud engineering. Organizational capabilities span product, project, and change management, along with domain expertise. The most effective teams rely on “T-shaped” professionals, deep in one area, broad across others, to enable strong collaboration.
How do emerging AI regulations affect lifecycle management?
Regulations like the EU AI Act now make AI governance a legal requirement, not just best practice. High-risk systems must ensure data quality, documentation, bias testing, human oversight, and continuous monitoring. Organizations should embed compliance into the AI lifecycle from the start, maintain audit trails, enable explainability, and involve legal teams throughout, not just before deployment.