Table of Contents
MLOps in 2026 has changed what it used to be earlier.
87% of enterprises have AI in production.
Fewer than 40% scale beyond pilots.
The bottleneck isn’t the models, it’s the operations around them.
This guide covers what MLOps looks like in 2026, what’s changed, and what actually works.
What Is MLOps?
MLOps (Machine Learning Operations) is the practice of reliably building, deploying, monitoring, and governing ML systems at scale.
Think of it as DevOps, extended for the unique headaches of AI.
Here’s the uncomfortable truth most data science teams learn the hard way: the model is maybe 5–10% of an ML system.
The other 90% is data validation, infrastructure, monitoring, governance, and the continuous improvement loops that keep predictions useful after day one.
MLOps is the discipline that manages all of it.
How MLOps Has Changed Since 2022–2024
Then: Pipeline automation. Tools were fragmented, integration was manual, and “MLOps” mostly meant automating the training → deploy handoff.
Now: End-to-end platform operations. Governance is built in, not bolted on. Experiment tracking, feature stores, model registries, and drift detection are table stakes, not differentiators.
Where it’s heading: Unified AI operating systems that manage classical ML models, LLMs, and agentic workflows through one control plane.
The MLOps Lifecycle (2026 Framework)
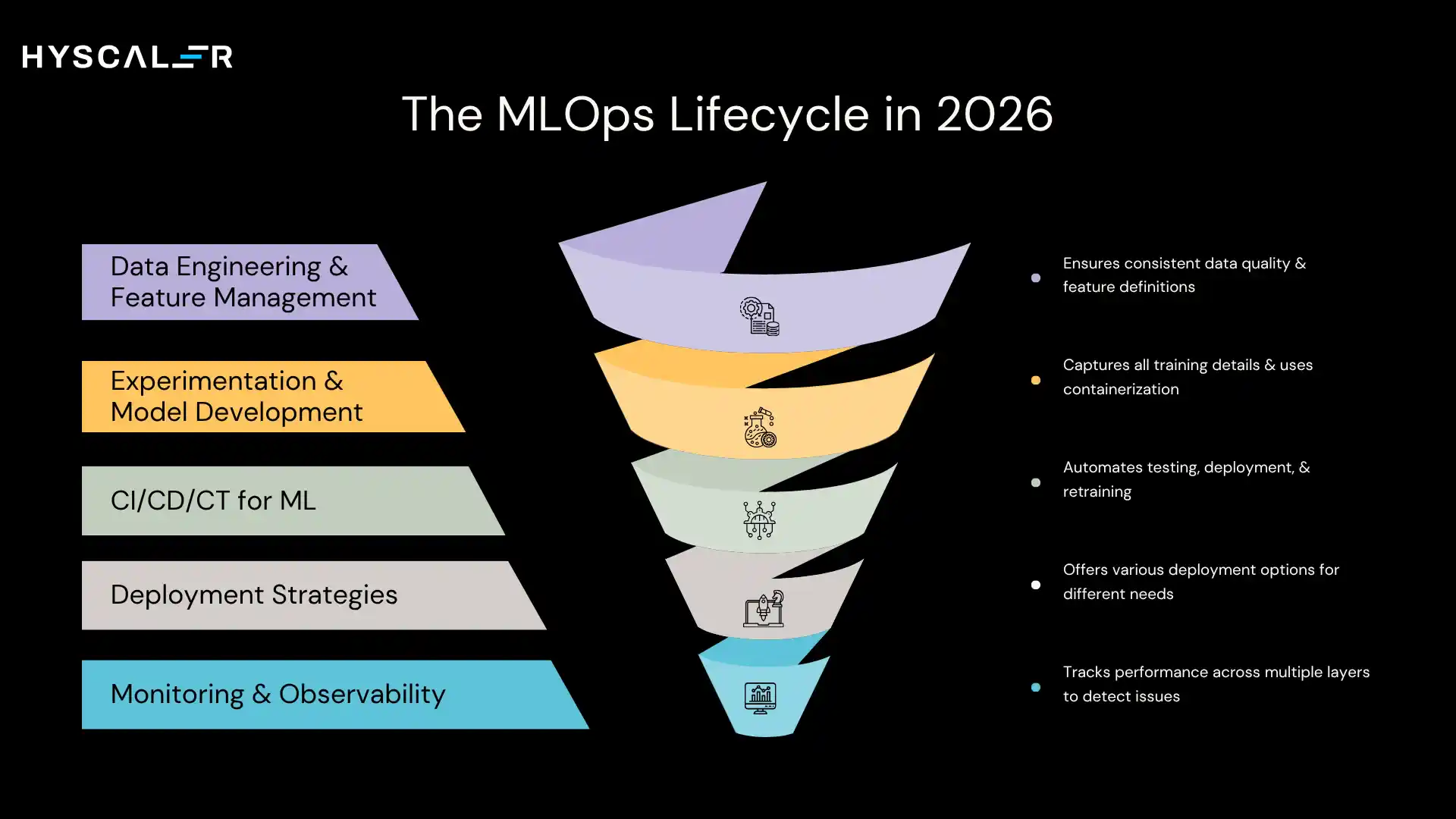
1. Data Engineering & Feature Management
Continuous data validation, automated anomaly detection, and centralized feature stores that ensure training and inference use the same feature definitions.
Data quality is no longer a pre-processing step; it’s an ongoing operation.
2. Experimentation & Model Development
Every training run captures hyperparameters, dataset versions, code commits, and performance metrics.
Container-based environments kill “works on my laptop” problems.
Git-style model versioning makes rollbacks fast.
3. CI/CD/CT for ML
- CI: Automated tests run on every commit, unit tests, pipeline integration tests, and model performance gates.
- CD: Models move through staging automatically when they pass tests. Blue-green deploys and canary releases reduce rollout risk.
- CT: This is where ML diverges from traditional software. Models retrain automatically when drift is detected, not on calendar schedules.
4. Deployment Strategies
No single pattern fits everything:
- Batch inference for pre-computed scores (fraud risk, churn prediction)
- Real-time APIs for live decisions (credit, pricing, recommendations)
- Edge deployment for latency-sensitive or privacy-constrained scenarios
- Multi-cloud for organizations that can’t commit to a single provider
5. Monitoring & Observability
Production monitoring covers four layers: infrastructure (latency, errors), data quality (drift, anomalies), model performance (accuracy, confidence), and business impact (revenue, conversion).
The goal is to detect degradation before business metrics move.
MLOps vs LLMOps vs AIOps
| Category | MLOps | LLMOps | AIOps |
|---|---|---|---|
| Primary Focus | Predictive ML models (classification, regression, forecasting) | Foundation models & Generative AI (LLMs, diffusion models) | IT operations automation & incident management |
| Data Dependency | Structured + tabular data, engineered features | Unstructured data (text, images), embeddings, prompts | System logs, metrics, traces, and topology data |
| Model Characteristics | Task-specific, trained from scratch or fine-tuned | Massive pre-trained models, prompt-engineered or fine-tuned | Pattern recognition in operational data |
| Key Monitoring | Data drift, model accuracy, prediction latency | Hallucinations, safety violations, prompt injection, and output quality | Anomaly detection, incident prediction, root cause analysis |
| Deployment Pattern | Versioned model artifacts served via APIs or batch | Hosted LLM endpoints + retrieval systems + guardrails | Embedded in monitoring and automation platforms |
| Cost Profile | Training costs moderate, inference optimizable | Training costs are extreme ($millions), inference is expensive (token-based) | Primarily, inference and data processing costs |
| Governance Focus | Bias, fairness, explainability, and regulatory compliance | Content safety, IP protection, hallucination prevention, and prompt leakage | Security, availability, and change management |
| Iteration Cycle | Weeks to months for retraining | Days to weeks for fine-tuning; continuous for prompt engineering | Continuous learning from operational feedback |
| Tooling Overlap | MLflow, Kubeflow, SageMaker, Databricks | LangChain, LlamaIndex, vector databases, specialized LLM platforms | Datadog, Dynatrace, Splunk, PagerDuty with AI modules |
In 2026, the lines blur.
Classical ML platforms now support LLM deployment.
RAG systems combine LLMs with embedding models.
AIOps platforms use LLMs for log analysis.
The winning strategy isn’t picking one, it’s building operations that span all three.
Key MLOps Trends in 2026

LLMOps convergence: Unified platforms manage XGBoost classifiers and fine-tuned LLaMA models through the same registry, monitoring, and deployment tooling. Less tool sprawl, more shared governance.
Regulation is real now: The EU AI Act and algorithmic accountability laws require auditability, explainability, and bias testing. Fines reach 6% of global revenue. Governance-first MLOps is risk management, not overhead.
Edge AI operations: Models are running on edge devices at scale, autonomous systems, manufacturing QC, and mobile apps. This adds compression, federated learning, and OTA update management to the MLOps scope.
Autonomous retraining: Closed-loop systems detect drift, evaluate whether retraining is cost-justified, retrain, validate, and deploy with humans reviewing policies and exceptions rather than executing each step.
FinOps for AI: GPU spending without accountability spirals out of control fast. Spot instances for training, model distillation to cut inference costs, chargeback systems that attribute AI spend to business units, these practices cut costs 40–60% versus undisciplined approaches.
Purpose-built AI observability: Generic monitoring tools miss ML-specific failure modes. Platforms like Arize, WhyLabs, and Fiddler track prediction drift, feature-importance shifts, and business-metric correlations in ways Prometheus alone cannot.
Common Enterprise Challenges For MLOps in 2026

Data silos: Five teams, five definitions of “customer lifetime value,” none trusted. Feature stores and data catalogs help, but they require executive sponsorship to break down territorial barriers.
Talent shortages: MLOps needs hybrid skills: data science, software engineering, infrastructure, and compliance. Few people have all of them. Self-service platforms that abstract infrastructure let data scientists focus on models.
Model sprawl: A financial services firm discovered 247 production models during a compliance audit. Only 89 were documented. Mandatory model registries and governance policies prevent this, but only if they’re enforced before the sprawl happens.
Lack of standardization: Every team uses different tools and conventions. Knowledge doesn’t transfer. A central platform team with reference architectures and opinionated templates fixes this without suppressing experimentation.
Shadow AI: Business units deploy models on personal accounts because official processes take weeks. The solution isn’t tighter restrictions; it’s making compliant deployment faster than workarounds.
MLOps Best Practices (What Actually Works)
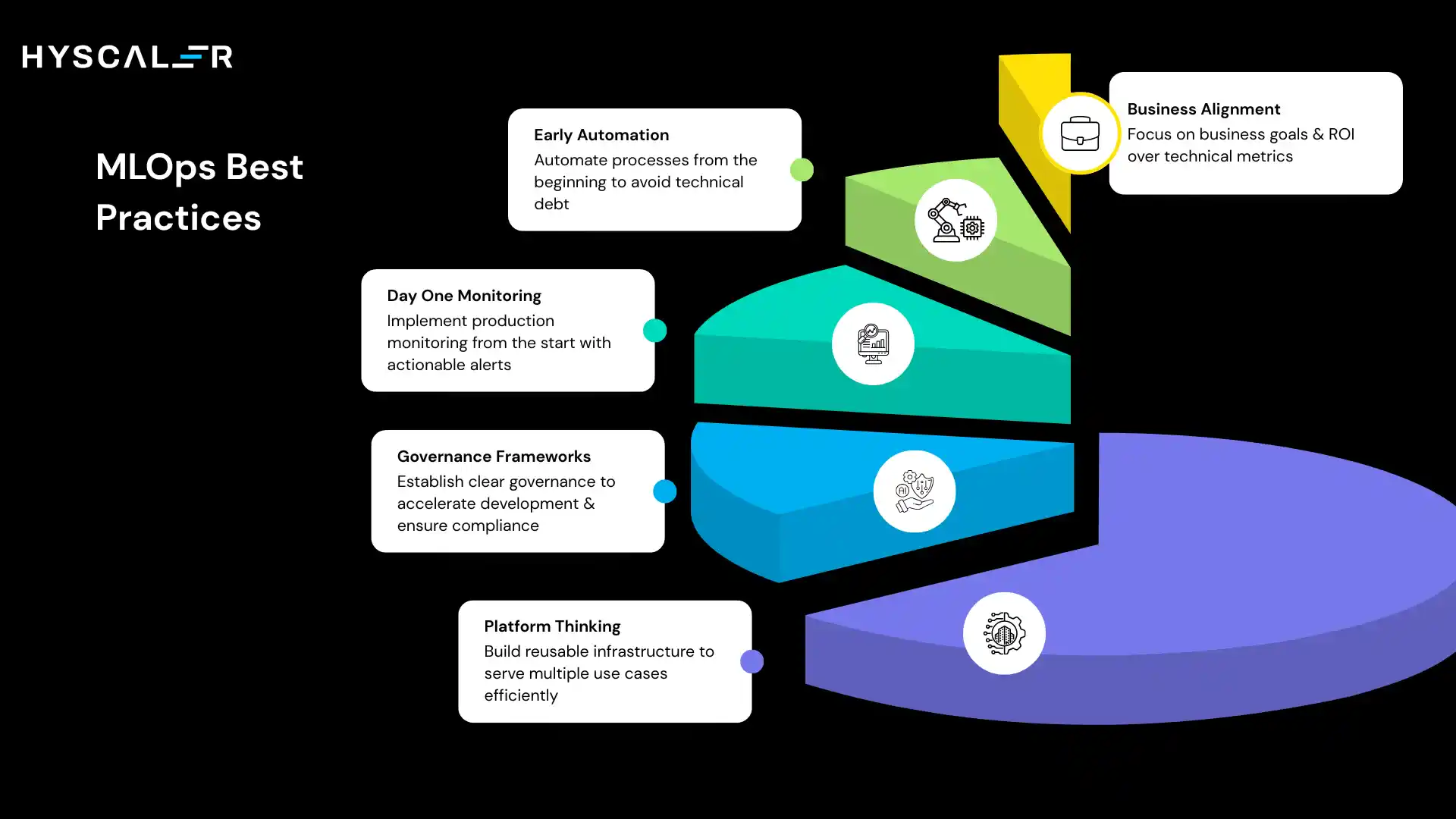
Start with business-aligned use cases: “Reduce churn by 15%” beats “achieve 92% AUC” as a success metric. ROI frameworks should be defined before model development, not after.
Automate early: The teams that plan to “automate later, once things stabilize” never do. Manual processes accumulate as technical debt. Even crude automation forces better habits.
Monitor from day one: Production monitoring isn’t optional. Every model needs observability before its first prediction. Alert only on actionable conditions; noisy alerts train humans to ignore them.
Invest in governance frameworks: Well-designed governance accelerates development by removing ambiguity. Model cards, approval workflows, and audit trails are built into the workflow, not layered on at deployment time.
Platform thinking over project thinking: Building reusable infrastructure that serves 50 use cases is better than building custom infrastructure 50 times. Treat internal MLOps platforms as products with a roadmap and internal customers.
MLOps Tools & Platforms (2026 Landscape)
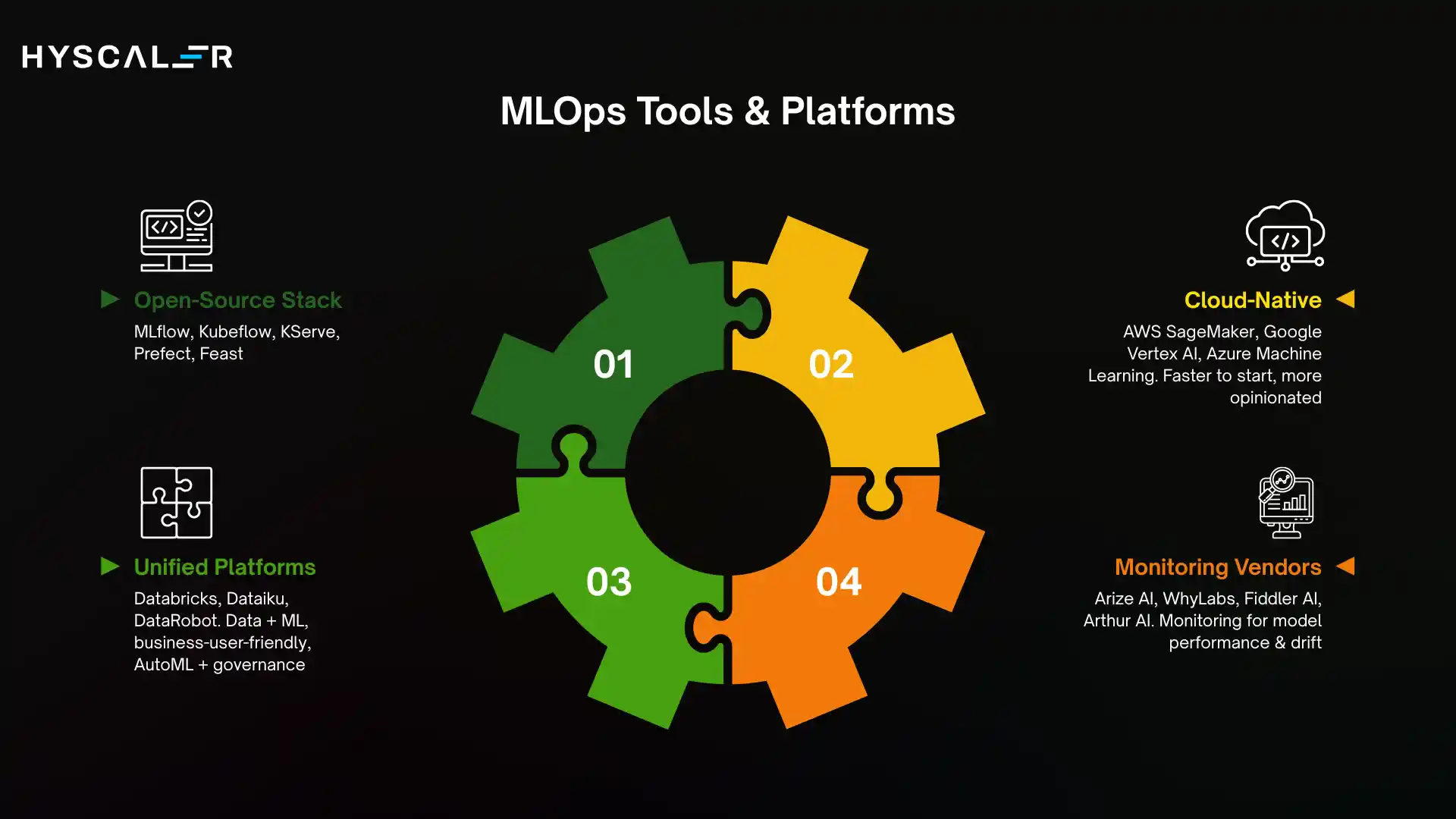
Open-source stack: MLflow (experiment tracking + model registry), Kubeflow (training pipelines), KServe or Seldon (model serving), Prefect or Airflow (orchestration), Feast (feature store).
Cloud-native: AWS SageMaker, Google Vertex AI, Azure Machine Learning. Faster to start, more opinionated, some vendor lock-in.
Unified platforms: Databricks (data + ML, strong for large-scale processing), Dataiku (business-user-friendly), DataRobot (AutoML + governance focus).
Monitoring vendors: Arize AI, WhyLabs, Fiddler AI, and Arthur AI.
How to choose:
- Single cloud, limited ML engineering → cloud-native platform
- Multi-cloud or strong engineering team → open-source foundation
- Regulated industry → platforms with strong governance + dedicated monitoring vendor
- Most enterprises → hybrid: cloud platform for commodity use cases, open-source for specialized needs
MLOps Maturity Model
| Level | Characteristics | Typical Deployment Time |
|---|---|---|
| 1: Experimental | Ad-hoc notebooks, manual deployments, no monitoring | Weeks to months |
| 2: Repeatable | Standardized templates, basic CI/CD, model registry | Days with manual steps |
| 3: Productionized | Full CI/CD/CT, self-service deployment, drift detection | Days, mostly automated |
| 4: Scalable Platform | Multi-tenant platform, auto-scaling, feature marketplace | Hours, fully automated |
| 5: Autonomous | Self-healing pipelines, policy-driven governance, agentic AI | Continuous |
Most organizations find sustainable value at Level 3–4.
Don’t skip levels; each builds on the foundations the previous stage installs.
Quick self-assessment: How do you discover model performance problems?
- Business users complain first → Level 1
- Periodic manual checks → Level 2
- Automated alerts → Level 3
- Predictive detection before impact → Level 4
How to Build an MLOps Strategy in 2026
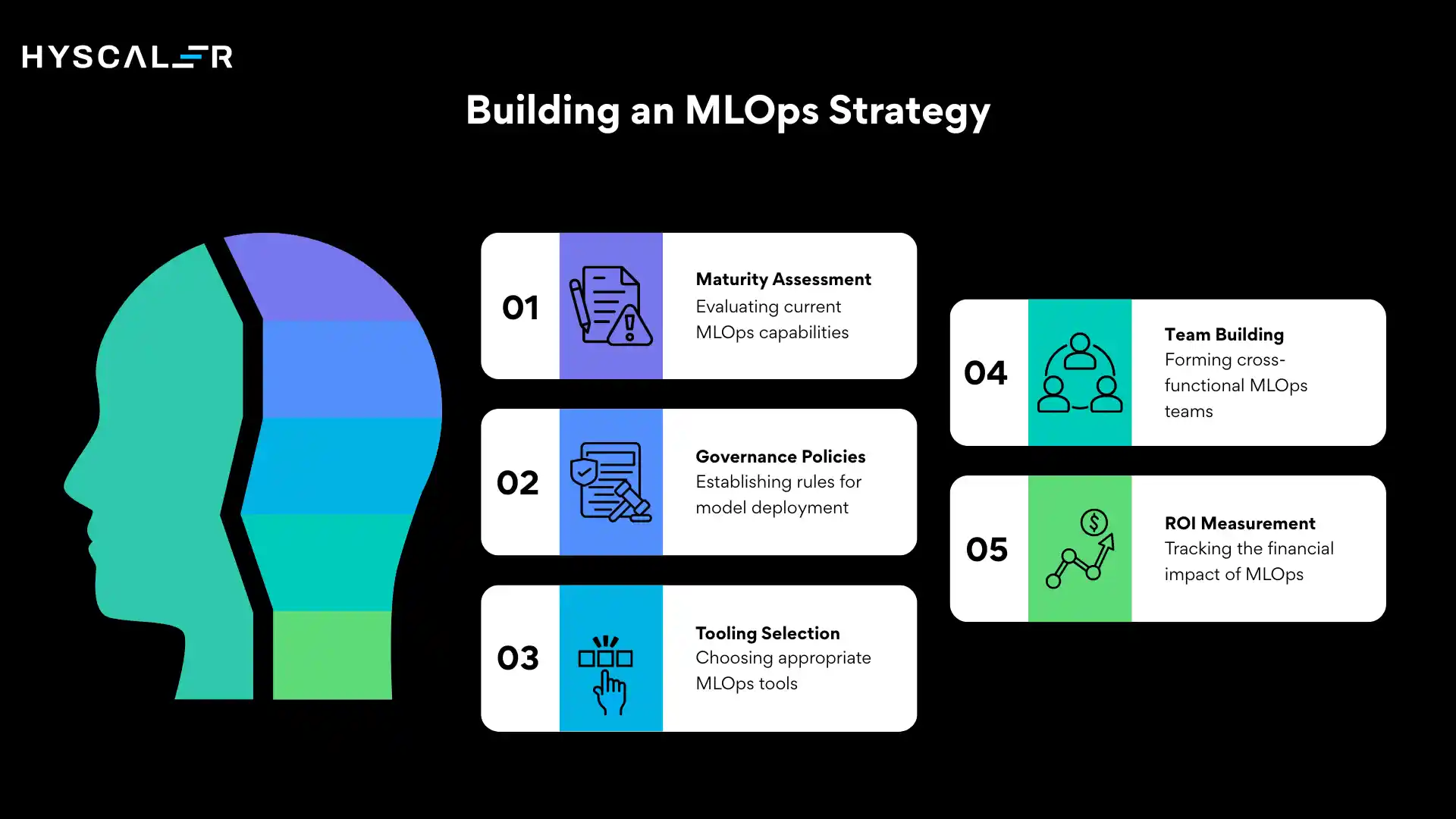
Step 1: Assess current maturity: Inventory all production models, document deployment methods, and map data sources, and identify monitoring gaps. Be honest about where you are.
Step 2: Define governance policies: Classify models by risk. Low-risk models (internal analytics) can auto-deploy after tests. High-risk models (credit, hiring, medical) need multi-stage sign-off. Document requirements before they become audit findings.
Step 3: Choose tooling: Match to your cloud strategy, team capabilities, scale requirements, and budget. Avoid over-engineering for where you are today.
Step 4: Build cross-functional teams: Data scientists own model accuracy. ML engineers own reliability and latency. Platform engineers’ own developer experience. Data engineers own pipeline quality. No one person covers all of this.
Step 5: Measure ROI: Track deployment frequency, time-to-production, incident rates, infrastructure costs per prediction, and business impact. A realistic 18-month ROI story: 30× faster deployments, 8× more models, 40% infrastructure cost reduction.
Timeline:
- Months 1–3: Assessment, governance policy, architecture decisions
- Months 4–6: Core platform, 2–3 pilot use cases, basic monitoring
- Months 7–12: Expand to 10–15 use cases, self-service capabilities, and ROI demonstration
- Months 13–18: Automation, advanced observability, organization-wide adoption
The Future: Autonomous AI Operations
Self-healing pipelines: detect anomalies, diagnose root causes, and attempt remediation without human intervention. Mainstream adoption expected 2027–2028.
Policy-driven governance: encodes compliance rules into executable policies enforced automatically throughout the ML lifecycle rather than being checked at a deployment gate once.
Agentic AI operations: extend MLOps to managing autonomous AI agents that plan, act, and adapt. Monitoring shifts from prediction accuracy to decision quality, goal achievement, and safety guardrails.
Federated MLOps: enables training across organizational boundaries, hospitals sharing patient data insights without sharing patient data, or fraud detection models trained on industry-wide signals.
The organizations that will use these capabilities effectively are the ones building solid Level 3 foundations now.
FAQs
What is MLOps?
MLOps is the practice of deploying, monitoring, and scaling ML models in production using automation, standardized workflows, and governance. It covers everything that happens after a model is trained.
How is MLOps different from DevOps?
DevOps manages code. MLOps manages code, data, and models with additional challenges like data drift, model versioning, continuous retraining, and regulatory compliance.
How long does MLOps implementation take?
Basic workflows: 6–12 months. Production maturity: 18–24 months. Advanced capabilities: 2–3 years. Early wins are possible in 3–6 months if you start with a well-scoped pilot.
What’s the difference between MLOps and LLMOps?
MLOps manages traditional predictive models. LLMOps covers generative AI and foundation models (prompt engineering, hallucination monitoring, RAG systems). In 2026, unified platforms will handle both.
How do I measure MLOps ROI?
Track deployment frequency, time-to-production, incident rates, infrastructure cost per prediction, and business impact (revenue influenced, cost saved, risk reduced). Teams running mature MLOps typically report 10× faster releases and 40–60% infrastructure cost reductions.
What skills does an MLOps team need?
Data scientists (model accuracy), ML engineers (production systems), platform engineers (infrastructure), data engineers (pipelines), and product managers (business alignment). Success comes from clear role separation, not finding unicorns who can do all of it.