
Table of Contents
Artificial intelligence is no longer a research experiment; it powers real products, real workflows, and real decisions every single day.
But building an AI application is only half the battle.
The harder challenge is making it reliable, scalable, secure, and continuously improving in production.
That is where LLMOps comes in.
This guide covers everything you need to know about LLMOps: what it is, why it matters, how it differs from traditional MLOps, its core components, popular tools, best practices, and the challenges organizations face when deploying large language models at scale.
What is LLMOps?
Definition of LLMOps
LLMOps (Large Language Model Operations) is the practice of managing, deploying, monitoring, and optimizing large language models in production.
It ensures reliability, security, performance, and governance of LLM-powered applications.
Think of LLMOps as the operational backbone behind every AI chatbot, copilot, or content generation tool you use.
Without it, these systems would be unstable, expensive to run, difficult to improve, and nearly impossible to govern responsibly.

How LLMOps Extends MLOps
Traditional MLOps (Machine Learning Operations) was designed to manage the lifecycle of conventional machine learning models, from training on structured data to deploying and monitoring prediction accuracy over time.
LLMOps builds on this foundation, adapting it to the unique demands of large language models.
Where MLOps focuses on model training pipelines and accuracy metrics, LLMOps introduces new workflows around prompt engineering, vector databases, output quality evaluation, hallucination detection, and dynamic API deployment.
The scale, complexity, and unpredictability of LLMs require an entirely new operational discipline.
Why LLMOps is Important for Modern AI Applications
As organizations move from experimenting with LLMs to deploying them in customer-facing applications, the operational stakes rise significantly.
A language model that works well in testing can fail unpredictably in production, generating incorrect information, drifting in quality over time, or becoming prohibitively expensive to run.
LLMOps provides the infrastructure, tooling, and processes to prevent these failures and sustain high-quality AI at scale.
Why LLMOps is Important
Deploying an LLM-powered application without operational discipline is like launching a product without quality control.
Here are the key reasons why LLMOps has become essential for modern AI teams.
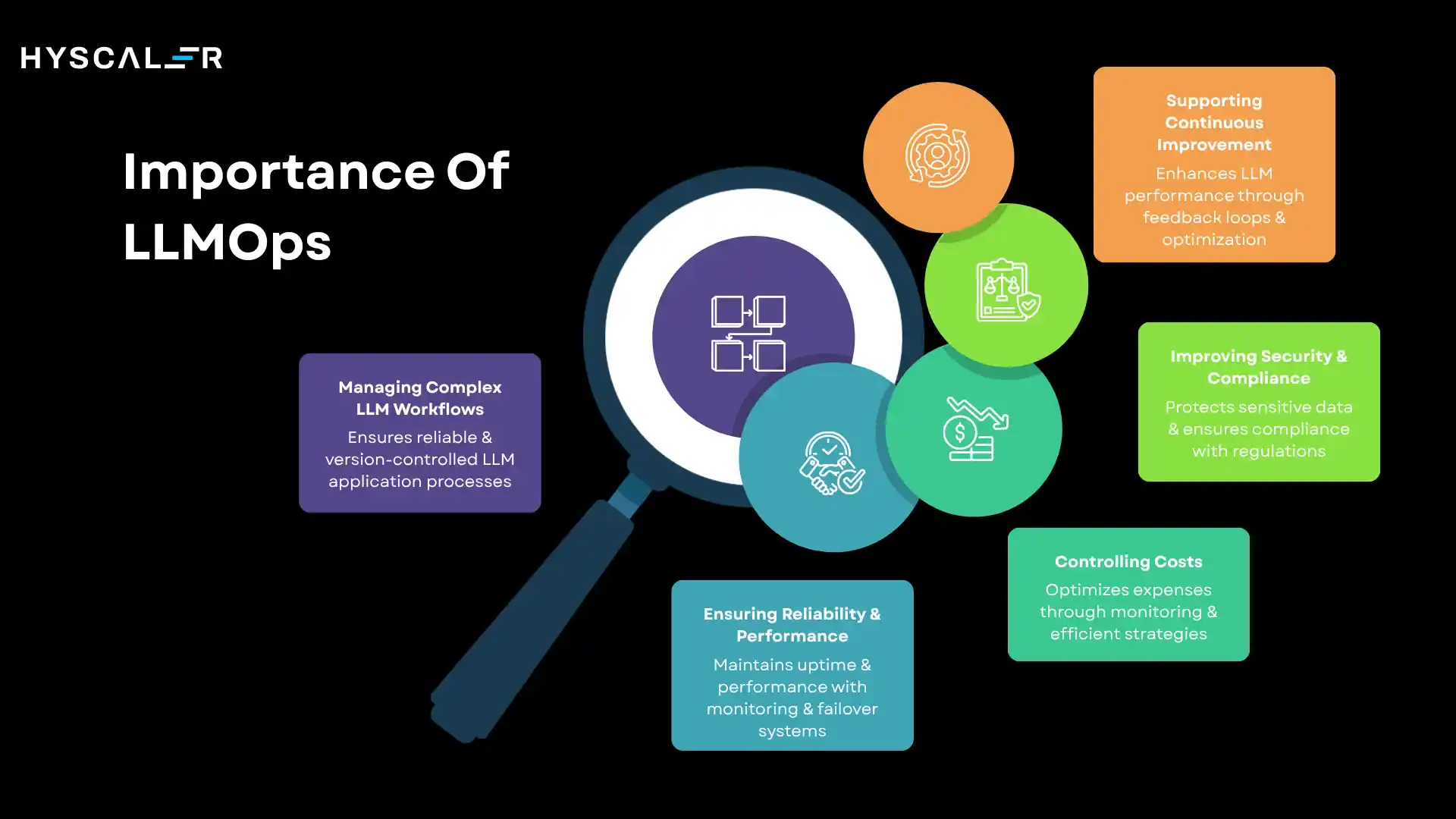
Managing Complex LLM Workflows
LLM applications are rarely simple.
They often involve chains of prompts, retrieval-augmented generation (RAG) pipelines, tool use, and multi-step reasoning.
LLMOps provides the orchestration layer that keeps these complex workflows functioning reliably, with clear version control, rollback mechanisms, and dependency management.
Ensuring Reliability and Performance
Production AI applications must meet strict uptime and latency requirements.
LLMOps establishes monitoring, alerting, and failover systems that catch degradation before it impacts users, ensuring consistent response quality and speed even under high load.
Controlling Costs
Large language models can be extraordinarily expensive to run at scale.
Without careful cost management, invoices can spiral rapidly.
LLMOps introduces cost monitoring, caching strategies, model tiering, and efficient batching to keep operational expenses under control.
Improving Security and Compliance
LLMs process sensitive data and can generate harmful outputs if left unchecked.
LLMOps enforces access controls, data privacy standards, output filtering, and audit trails, ensuring AI applications comply with regulatory requirements and organizational security policies.
Supporting Continuous Improvement
Language models are not static.
Their performance can degrade over time as language patterns shift, new edge cases emerge, or underlying models are updated.
LLMOps creates feedback loops that capture real-world performance data and feed it back into prompt optimization, fine-tuning, and evaluation processes.
How LLMOps is Different from MLOps
While LLMOps inherits many principles from MLOps, the two disciplines differ significantly across several dimensions.
The table below highlights the key distinctions:
| Feature | MLOps | LLMOps |
|---|---|---|
| Model type | Traditional ML | Large language models |
| Data | Structured | Unstructured text |
| Updates | Periodic retraining | Prompt updates, fine-tuning |
| Monitoring | Accuracy metrics | Output quality, hallucinations |
| Deployment | Static models | Dynamic APIs |
The most significant difference lies in updates.
Traditional ML models are retrained periodically on new data, a process that can take hours or days.
LLMs can be improved much more rapidly through prompt engineering, retrieval-augmented generation, or targeted fine-tuning, enabling faster iteration cycles but requiring more sophisticated version control for prompts and configurations.
Monitoring is also fundamentally different.
Evaluating whether a regression model is performing well involves checking accuracy against a labeled test set.
Evaluating whether an LLM response is helpful, accurate, and safe requires a combination of automated metrics, human feedback, and specialized evaluation frameworks.
Core Components of LLMOps Architecture
A mature LLMOps architecture consists of six core components, each addressing a distinct operational challenge.
Together, they form the foundation of a production-grade LLM system.
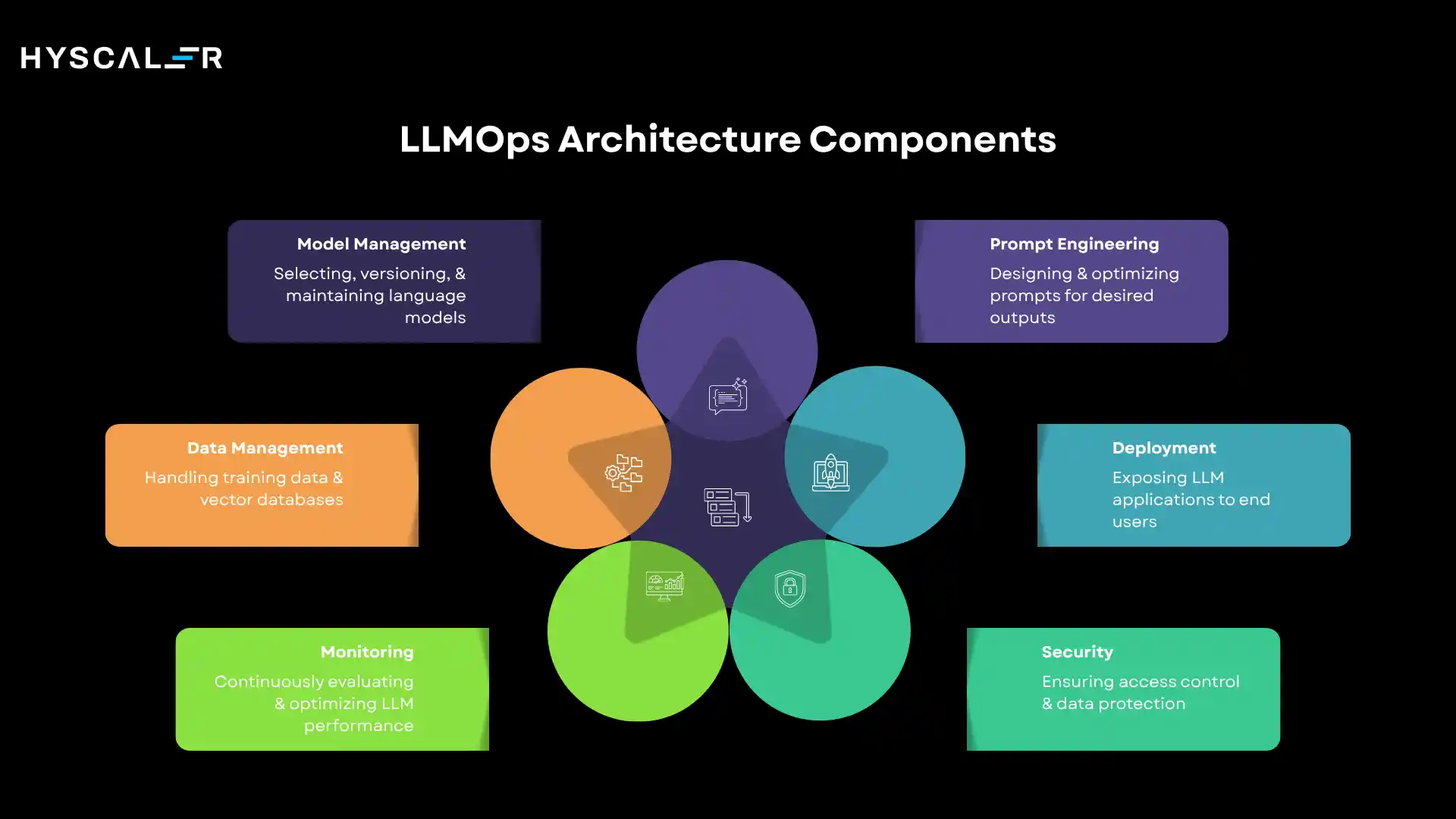
1. Model Management
Model management encompasses the selection, versioning, and ongoing maintenance of the language models that power your application.
- Model Selection: Choosing the right base model, whether a proprietary API like GPT-4 or Anthropic Claude, or an open-source model like Llama or Mistral, based on capability, cost, latency, and compliance requirements.
- Version Control: Tracking which model versions are in use across different environments (development, staging, production) and maintaining the ability to roll back to previous versions when issues arise.
- Fine-tuning: Adapting a base model to your specific domain or task using custom training data, improving performance on specialized use cases without training a model from scratch.
2. Prompt Engineering
Prompts are the primary interface between your application and the language model.
Effective prompt management is as critical as any other software engineering discipline.
- Prompt Design: Crafting instructions, context, and examples that reliably guide the model toward desired outputs, a skill that combines technical understanding with an intuition for how language models interpret natural language.
- Prompt Versioning: Treating prompts as code, tracking changes, testing new versions against baselines, and maintaining a history of what worked, what failed, and why.
- Optimization: Systematically improving prompts using techniques like chain-of-thought reasoning, few-shot examples, and structured output constraints to boost accuracy and consistency.
3. Data Management
LLMs operate on text, but the data infrastructure behind them is surprisingly complex, especially for applications that use retrieval-augmented generation.
- Training Data: Managing the datasets used for fine-tuning, including data cleaning, deduplication, annotation, and compliance with data privacy regulations.
- Vector Databases: Storing and querying semantic embeddings of documents, enabling the system to retrieve relevant context at inference time, a cornerstone of RAG-based applications.
- Embeddings: Generating and managing vector representations of text that allow the system to perform semantic search, clustering, and similarity matching efficiently.
4. Deployment
Deployment determines how your LLM application reaches end users and how it scales to meet demand.
- API Deployment: Exposing model capabilities through well-designed APIs with rate limiting, authentication, and versioning, whether using a third-party provider’s API or self-hosting model inference.
- Cloud Hosting: Leveraging cloud infrastructure (AWS, GCP, Azure) to run model inference at scale, with auto-scaling, load balancing, and geographic distribution for low latency.
- Edge Deployment: Running smaller, optimized models closer to the end user, on-device or at the network edge, for latency-sensitive or privacy-critical applications.
5. Monitoring and Observability
Ongoing monitoring is what separates a production system from a prototype.
LLM monitoring goes far beyond traditional application performance monitoring.
- Output Quality Monitoring: Continuously evaluating whether model outputs meet quality standards using automated metrics, human evaluation, and specialized LLM-as-judge frameworks.
- Latency Tracking: Measuring and optimizing response times across the full inference pipeline, including retrieval, prompt construction, model inference, and post-processing.
- Cost Monitoring: Tracking token usage and API costs in real time, with alerting when spending exceeds thresholds and visibility into which use cases drive the highest costs.
- Hallucination Detection: Identifying factually incorrect or fabricated model outputs using grounding checks, citation verification, and confidence scoring is one of the most critical and challenging aspects of LLM monitoring.
6. Security and Governance
As LLMs are deployed in high-stakes environments, security and governance become non-negotiable.
- Access Control: Enforcing role-based access to model APIs, training data, and configuration systems, ensuring that only authorized personnel can modify production systems.
- Compliance: Meeting industry-specific regulatory requirements (GDPR, HIPAA, SOC 2, etc.) around data handling, model transparency, and audit trails.
- Data Protection: Preventing sensitive information from being included in prompts sent to external model providers, and ensuring that model outputs do not inadvertently expose confidential data.
LLMOps Workflow (Step-by-Step)
A typical LLMOps workflow follows a continuous loop of development, deployment, and improvement.
Here is how it unfolds in practice:
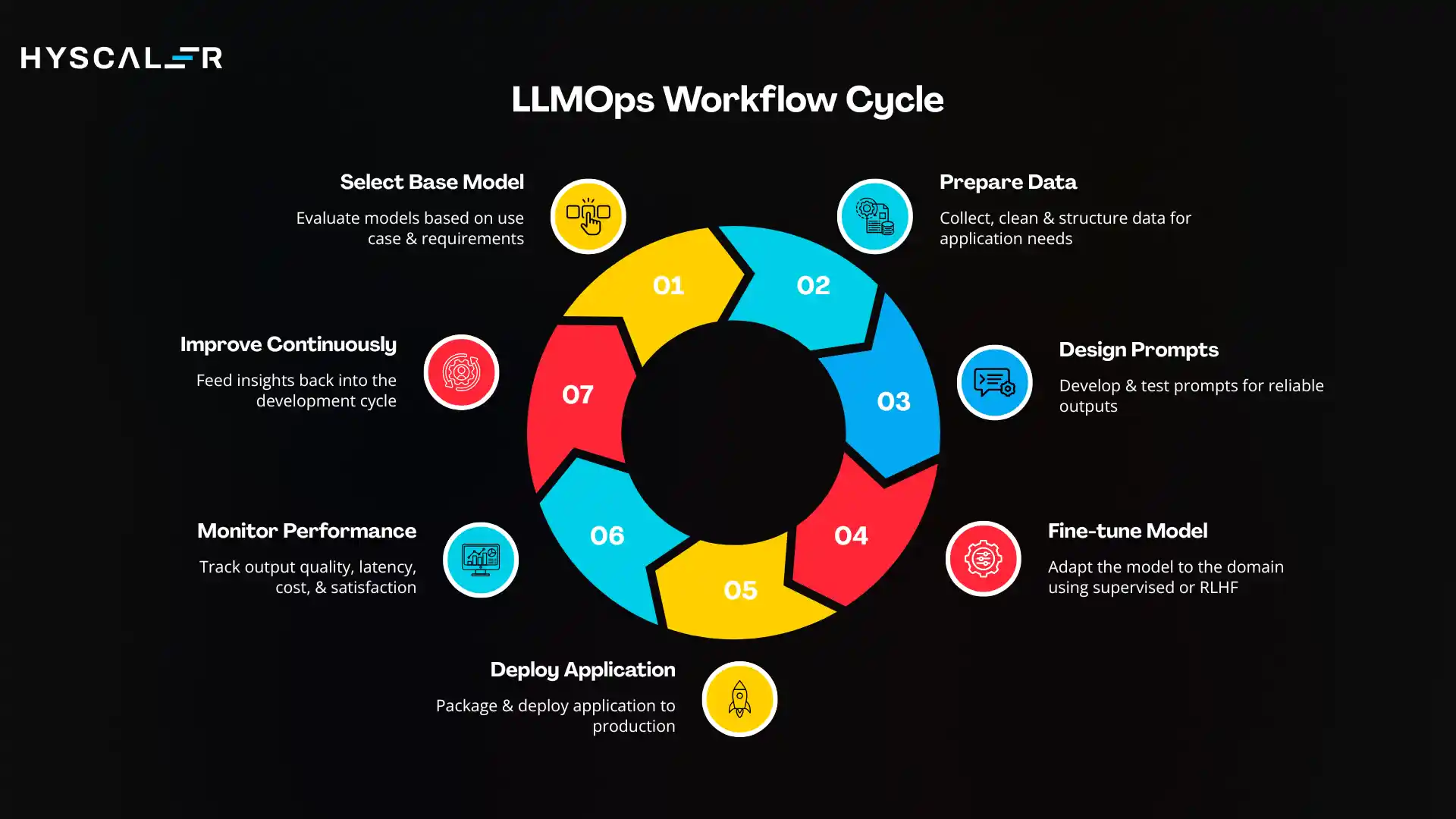
- Select Base Model: Evaluate available models based on your use case, budget, and technical requirements. Consider capability, cost per token, latency, context window, and data privacy implications.
- Prepare Data: Collect, clean, and structure the data your application needs, whether for fine-tuning, RAG retrieval, or evaluation. Ensure compliance with data governance policies.
- Design Prompts: Develop and test prompts that reliably guide the model toward correct, safe, and useful outputs. Document your prompt design rationale for future reference.
- Fine-tune Model (if needed): Adapt the base model to your domain using supervised fine-tuning or reinforcement learning from human feedback (RLHF) when prompt engineering alone is insufficient.
- Deploy Application: Package your application, including the model, retrieval system, and prompt logic, and deploy it to production with appropriate scaling and failover infrastructure.
- Monitor Performance: Implement continuous monitoring of output quality, latency, cost, and user satisfaction. Set up alerting for anomalies and regressions.
- Improve Continuously: Feed monitoring insights back into the development cycle. Update prompts, retrain models, expand knowledge bases, and iterate on evaluation frameworks based on real-world performance data.
Popular LLMOps Tools
The LLMOps tooling ecosystem has grown rapidly.
Here are the most widely used tools across the key categories:

Model Platforms
- OpenAI: The most widely used LLM API, offering GPT-4 and o-series models with robust documentation, fine-tuning capabilities, and enterprise-grade reliability.
- Anthropic: Provider of the Claude model family, known for safety research, long context windows, and strong reasoning capabilities.
- Hugging Face: The leading open-source model hub, offering thousands of pretrained models, fine-tuning tools, and a deployment platform called Inference Endpoints.
Vector Databases
- Pinecone: A managed vector database optimized for high-performance semantic search at scale, popular in production RAG applications.
- Weaviate: An open-source vector database with built-in machine learning integrations and flexible deployment options.
- FAISS: Facebook AI’s open-source library for efficient similarity search, widely used for local and research-oriented vector search.
Monitoring Tools
- LangSmith: A debugging, testing, and monitoring platform developed by the LangChain team, offering trace-level visibility into LLM application behavior.
- Arize AI: An ML observability platform with strong LLM monitoring capabilities, including embedding drift detection and output quality evaluation.
- WhyLabs: An AI observability platform focused on monitoring data and model quality in production, with LLM-specific features for hallucination and toxicity detection.
Frameworks
- LangChain: The most popular framework for building LLM applications, providing abstractions for chains, agents, memory, and retrieval, with integrations for virtually every LLM provider and vector database.
- LlamaIndex: A data framework optimized for connecting LLMs to external data sources, particularly strong for RAG applications with complex document structures.
LLMOps Best Practices
Drawing from production deployments across industries, here are the best practices that consistently separate successful LLMOps implementations from those that struggle.
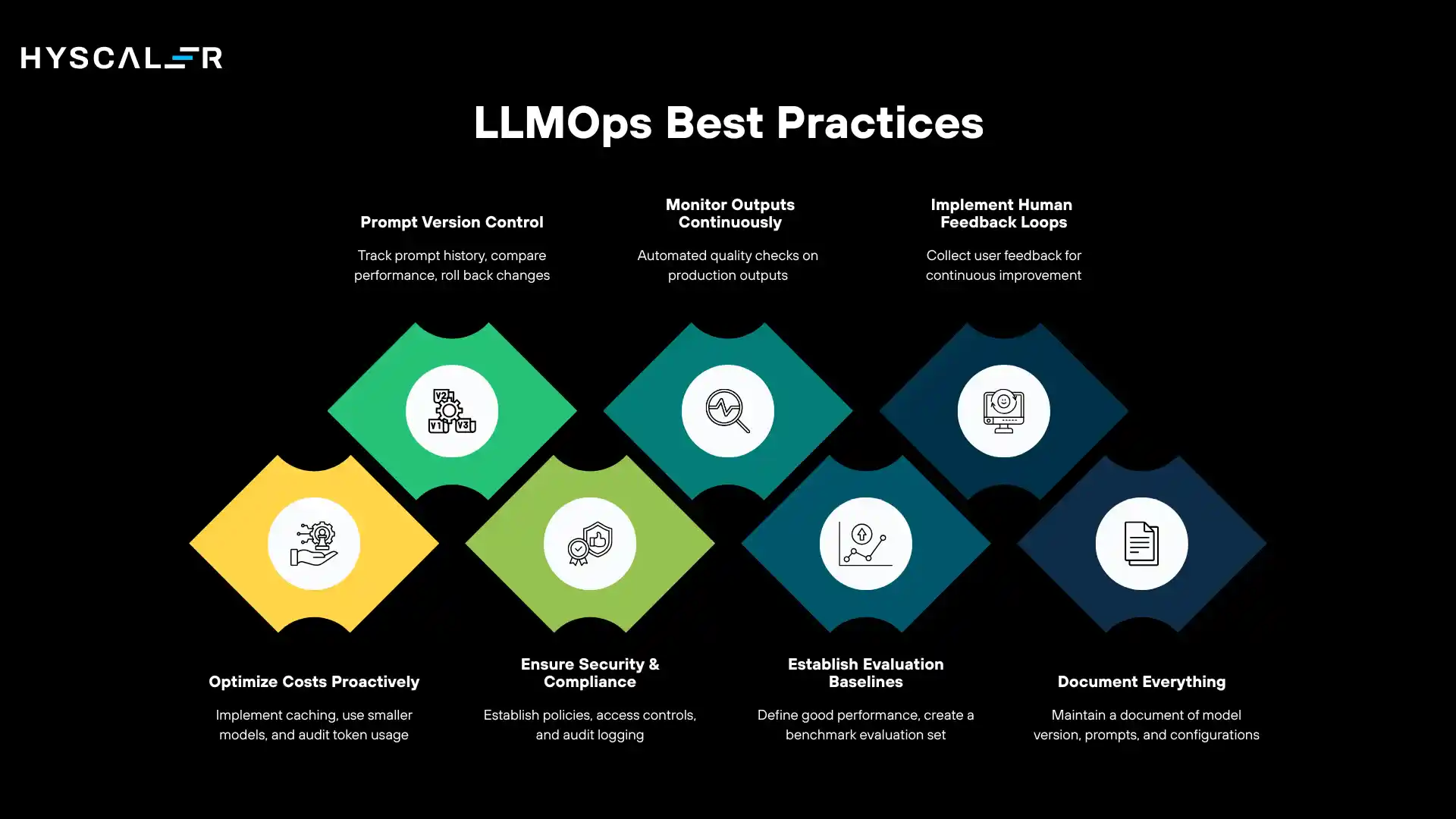
- Use Prompt Version Control: Treat every prompt change as a code change. Use version control systems to track prompt history, compare performance across versions, and roll back when new prompts underperform.
- Monitor Outputs Continuously: Never assume a working system will remain operational. Implement automated quality checks that run daily on a sample of real production output and alert your team when quality drops.
- Implement Human Feedback Loops: Automated metrics are imperfect. Build structured mechanisms for collecting user feedback and human expert evaluations, and use these signals to drive continuous improvement.
- Optimize Costs Proactively: Implement response caching for common queries, use smaller models for simpler tasks, and regularly audit your token usage to identify optimization opportunities before costs spiral.
- Ensure Security and Compliance from Day One: Retrofitting security and compliance into an existing LLM system is exponentially more difficult than building it in from the start. Establish data handling policies, access controls, and audit logging before your first production deployment.
- Establish Evaluation Baselines: Before deploying any system, define what good looks like. Create a benchmark evaluation set and run every major change against it to detect regressions.
- Document Everything: LLM systems evolve rapidly. Maintain clear documentation of model versions, prompt rationale, configuration decisions, and operational runbooks; our future team will thank you.
LLMOps Challenges
LLMOps is a maturing discipline, and organizations face significant challenges as they scale LLM applications.
Understanding these challenges is the first step to addressing them.
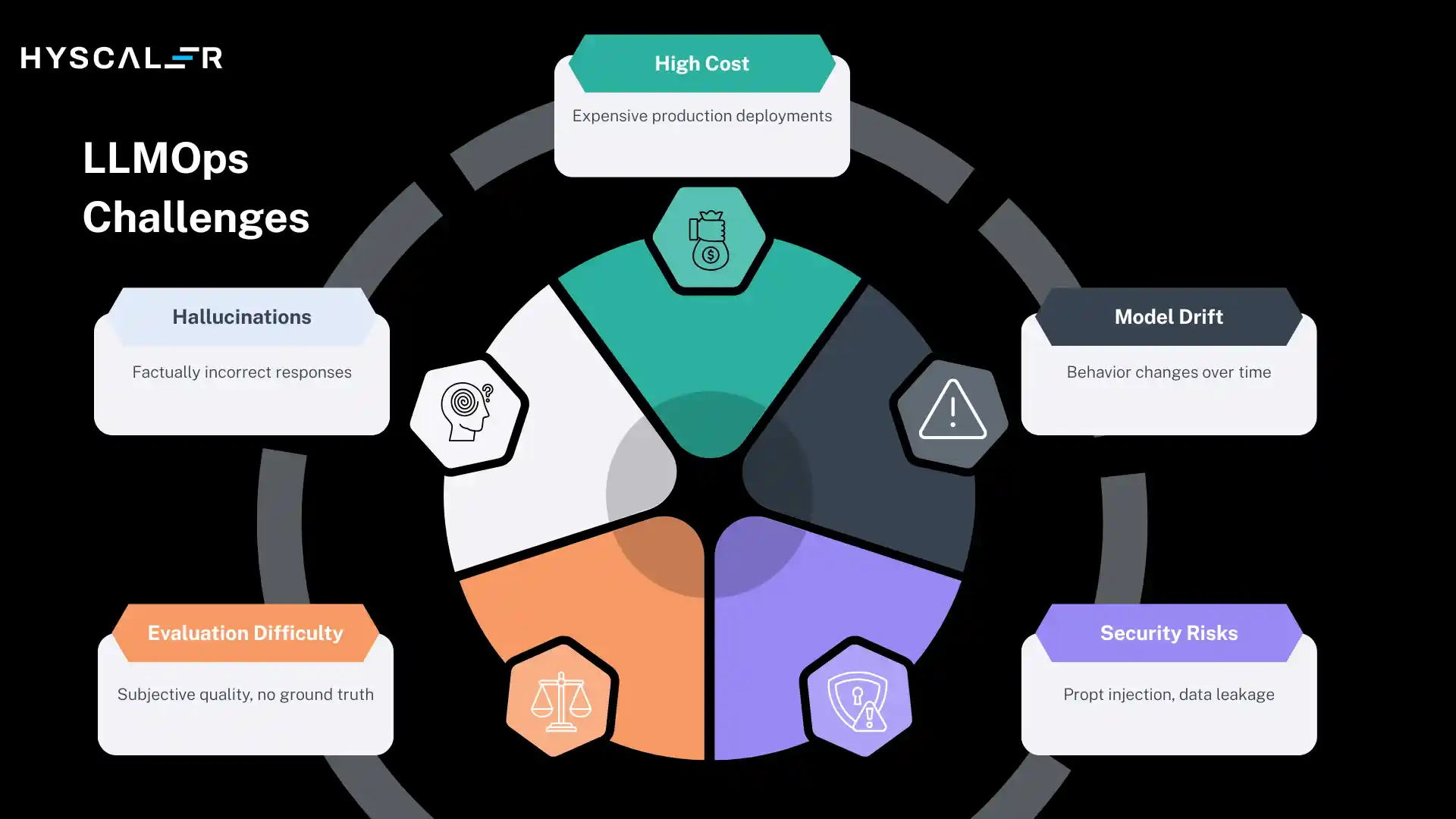
Hallucinations
Large language models sometimes generate confident, fluent, but factually incorrect responses, a phenomenon known as hallucination.
Detecting and mitigating hallucinations at scale remains one of the hardest unsolved problems in LLMOps, requiring a combination of retrieval augmentation, output verification, and human review.
High Cost
Running LLMs in production can be extremely expensive.
Enterprise-scale deployments can incur millions of dollars annually in inference costs.
Managing these costs requires careful model selection, caching, batching, and continuous optimization.
Model Drift
LLM behavior can change when model providers update their models, when retrieval databases change, or when the distribution of user inputs shifts over time.
Detecting and responding to model drift requires robust monitoring infrastructure and clear processes for revalidation.
Security Risks
LLMs introduce novel security vulnerabilities, including prompt injection attacks (where malicious user inputs hijack the model’s behavior), data leakage through model outputs, and jailbreaking attempts that bypass safety filters.
Defending against these risks requires specialized security tooling and ongoing vigilance.
Evaluation Difficulty
Evaluating the quality of LLM outputs is inherently subjective.
Unlike traditional ML, there is rarely a single ground-truth answer.
Developing reliable evaluation frameworks that correlate with real-world user satisfaction is an active area of research and a practical challenge for every LLMOps team.
Real-World Examples of LLMOps
LLMOps is not theoretical; it is the operational foundation behind many of the AI applications that millions of people use every day.
- AI Chatbots: Consumer and enterprise chatbots like customer service bots and virtual assistants rely on LLMOps to maintain consistent response quality, manage conversation history, and handle thousands of concurrent users reliably.
- AI Customer Support: Companies deploy LLMs to handle tier-1 support tickets, reducing human agent workload while maintaining quality standards. LLMOps ensures that these systems stay accurate as products evolve and escalate correctly when they cannot help.
- AI Copilots: Code assistants, writing assistants, and research copilots are among the most complex LLM deployments, requiring tight integration with development environments, real-time retrieval from large codebases, and careful quality monitoring.
- Content Generation Tools: Marketing platforms, news organizations, and content agencies use LLMs to generate drafts, summaries, and translations at scale. LLMOps governs content quality, brand consistency, and plagiarism risk across millions of generated artifacts.
Future of LLMOps
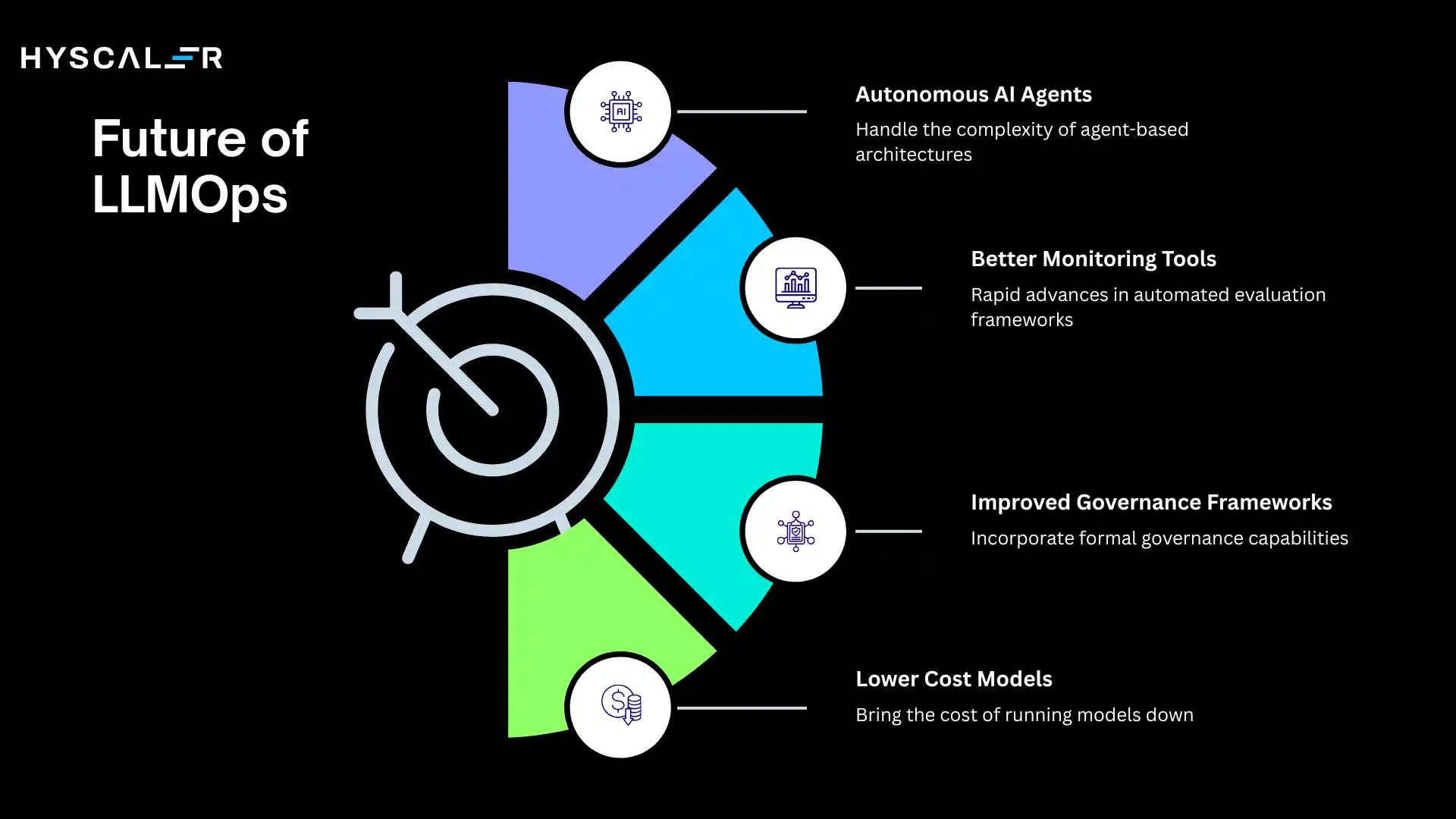
The LLMOps landscape is evolving at a remarkable pace.
Several trends are shaping where the discipline is headed over the next few years.
- Autonomous AI Agents: As LLMs become capable of taking multi-step actions across tools and systems, LLMOps must evolve to handle the operational complexity of agent-based architectures, including action logging, safety guardrails, and human-in-the-loop approval workflows.
- Better Monitoring Tools: The monitoring tooling ecosystem for LLMs is still immature compared to traditional software observability. Expect rapid advances in automated evaluation frameworks, behavioral testing, and real-time anomaly detection purpose-built for language model workloads.
- Improved Governance Frameworks: As AI regulation advances globally, LLMOps will increasingly incorporate formal governance capabilities, including model cards, audit logs, bias testing, and compliance reporting as standard components rather than afterthoughts.
- Lower Cost Models: Continued advances in model compression, quantization, and efficient architectures will bring the cost of running high-capability language models down significantly, making production LLM applications economically viable for a much wider range of use cases.
Conclusion
LLMOps is the discipline that makes the difference between a promising AI demo and a reliable, scalable, production-grade AI application.
As large language models move from research labs into the heart of business operations, the teams that invest in strong operational foundations will outperform those that treat deployment as an afterthought.
By building robust systems for model management, prompt engineering, data management, deployment, monitoring, and governance, and following the best practices refined through real-world deployments, organizations can unlock the full potential of large language models while managing the risks and costs that come with them.
The future of AI in production runs through LLMOps.
The time to build that foundation is now.
FAQs
What is LLMOps?
LLMOps is the practice of deploying, managing, monitoring, and optimizing large language models in production environments to ensure reliability, performance, and governance.
What is the difference between LLMOps and MLOps?
LLMOps focuses specifically on managing large language models with unstructured text data, prompt engineering, and hallucination monitoring, while MLOps manages traditional ML models with structured data and accuracy metrics.
What tools are used in LLMOps?
Commonly used tools include LangChain and LlamaIndex (frameworks), Pinecone and Weaviate (vector databases), OpenAI and Hugging Face (model platforms), and LangSmith and Arize AI (monitoring).
Why is LLMOps important?
LLMOps ensures that AI applications built on large language models are reliable, secure, cost-efficient, and continuously improved, making the difference between a prototype and a production-grade AI system.