Table of Contents
The AI systems powering today’s enterprises are no longer simple prediction engines.
They’re complex, autonomous networks of models, data pipelines, and intelligent agents making real-time decisions that directly impact business outcomes.
Yet most organizations are still monitoring them with tools designed for traditional software, and paying the price in production failures, compliance gaps, and eroded trust.
Why AI Observability Needs a Layered Approach
Traditional monitoring wasn’t built for AI.
When a microservice crashes, you get a stack trace.
When an AI model silently degrades, you might not know until customers complain or regulators come knocking.
The rise of complex AI systems has fundamentally changed the observability landscape.
Large language models process millions of unpredictable prompts daily.
Agentic AI systems make autonomous decisions across interconnected tools and databases.
Real-time inference engines operate at millisecond latency with zero tolerance for downtime.
These systems don’t just run code because they learn, adapt, and evolve.
This is why AI observability requires a layered approach.
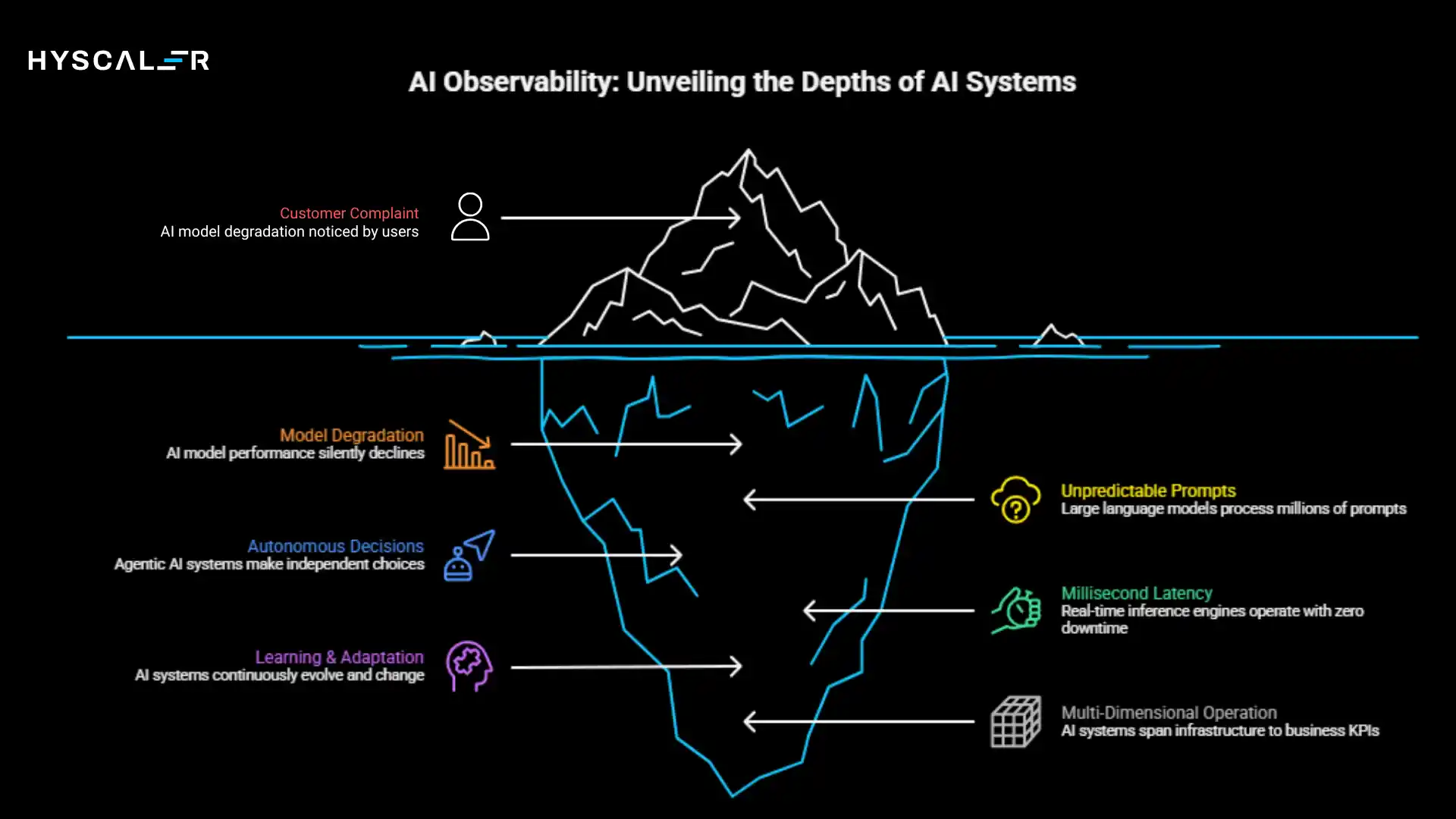
Just as AI systems operate across multiple dimensions, from GPU clusters to business KPIs, effective monitoring must span infrastructure, data quality, model behavior, security threats, and business impact simultaneously.
Observability has become the foundation for reliable AI at scale, and in 2026, it’s no longer optional; it’s the difference between AI that drives value and AI that creates risk.
What Are the Layers of Observability in AI?
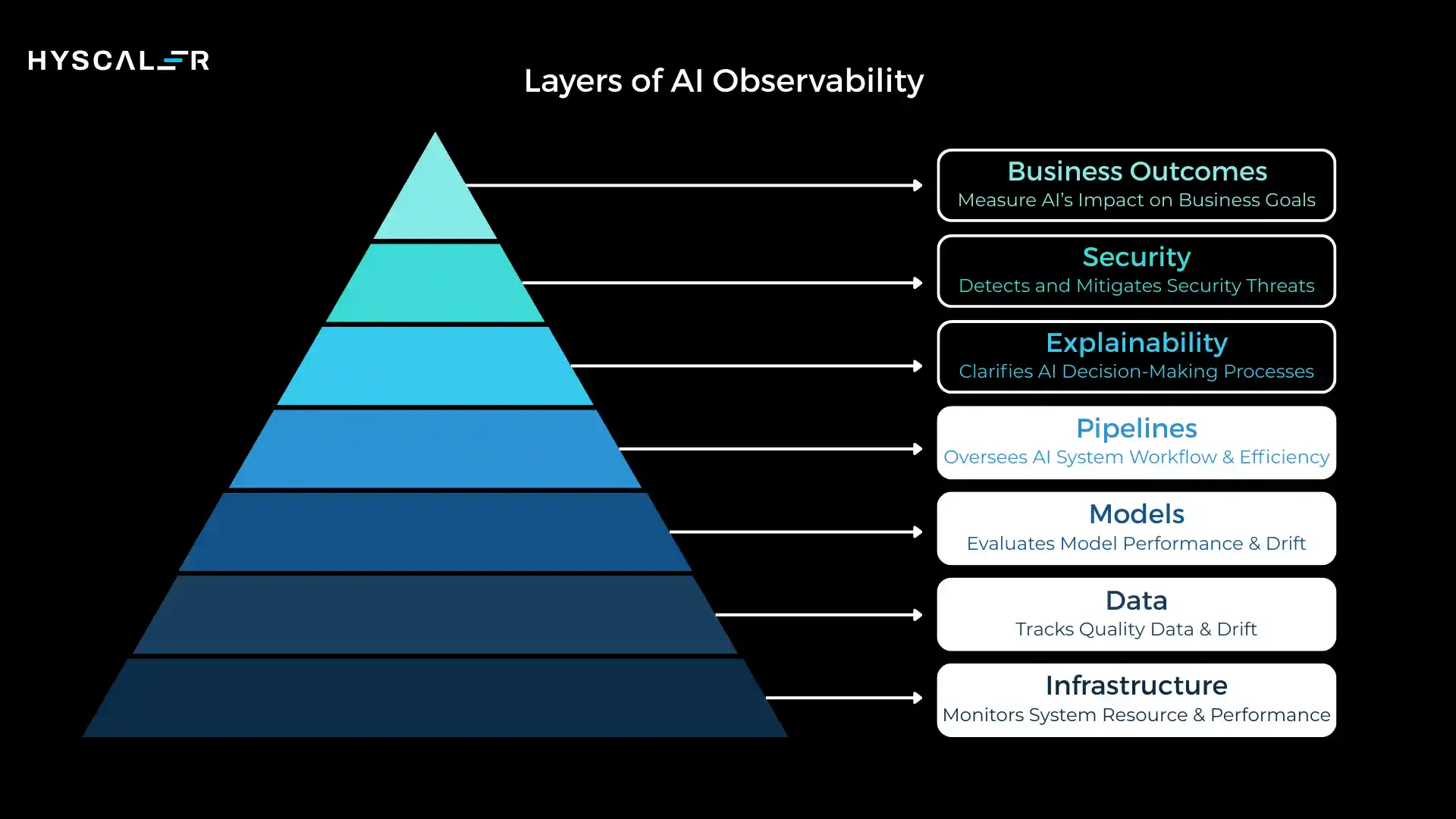
Layers of AI observability form a structured framework that monitors and explains AI systems across seven critical dimensions: infrastructure, data, models, pipelines, explainability, security, and business outcomes.
Each layer answers a specific question about system health, and together they provide complete visibility into the AI lifecycle from development through production.
These layers aren’t siloed, but they’re interconnected.
A spike in GPU utilization (infrastructure layer) might trace back to data drift (data layer), triggering more complex model processing (model layer), ultimately impacting response times that violate SLAs (business layer).
Understanding these relationships is what separates reactive troubleshooting from proactive AI operations.
The layered approach works across the entire AI lifecycle: during training, it catches data quality issues before they corrupt models.
During deployment, it validates that the infrastructure can handle production load.
During inference, it monitors for drift, security threats, and business impact in real-time, and during retraining, it provides the signals needed to improve model performance systematically.
Infrastructure Observability Layer
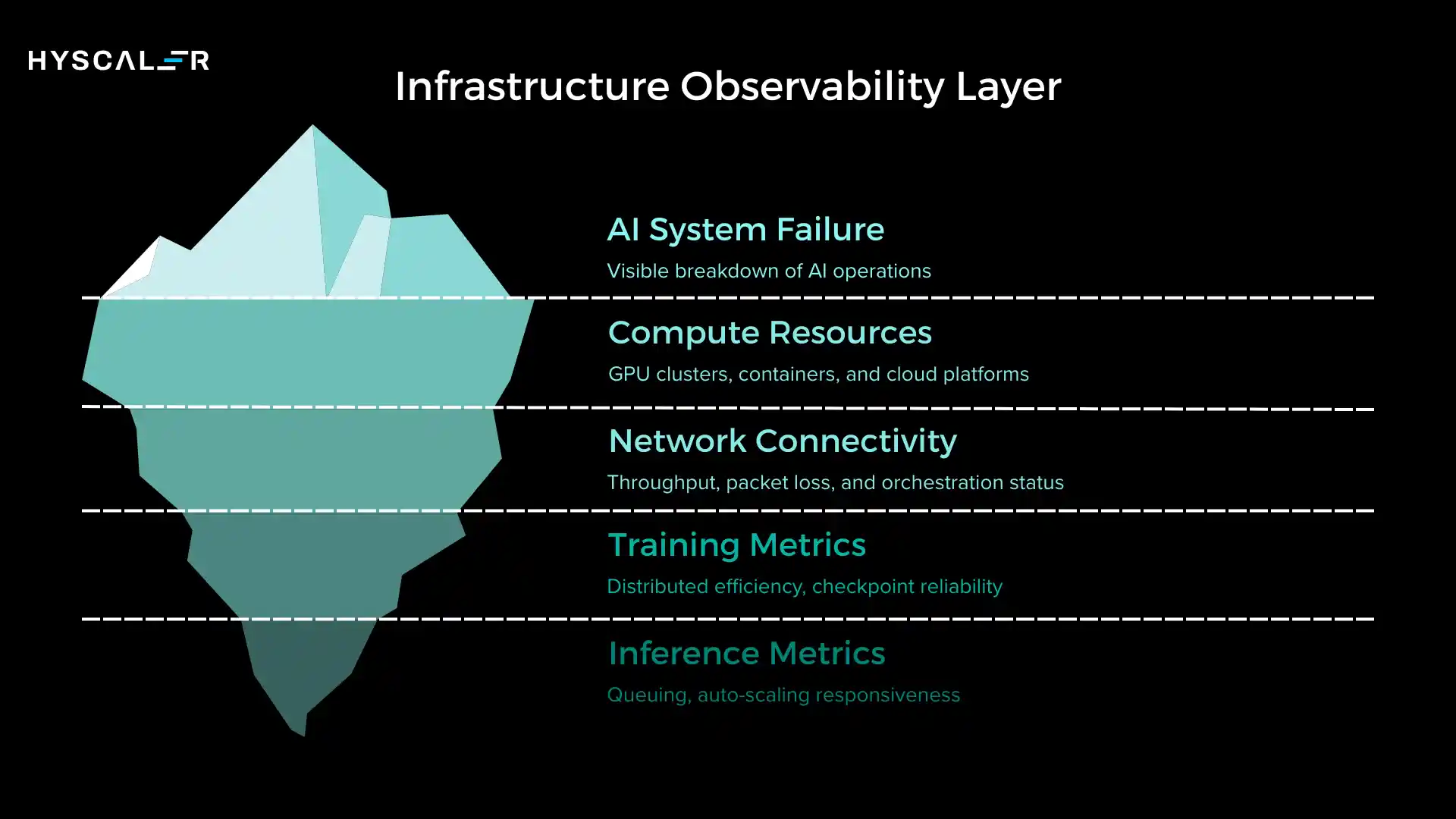
The infrastructure layer is where AI meets physical reality, compute resources, GPU clusters, containers, cloud platforms, and the networks connecting them.
This is the foundation upon which all AI operations depend, and when infrastructure fails, everything fails.
Key metrics at this layer include inference latency, GPU utilization and memory, container health and orchestration status, network throughput and packet loss, and infrastructure failure rates.
For training workloads, you’re tracking distributed training efficiency, checkpoint reliability, and storage I/O performance.
For inference, it requires queuing, auto-scaling responsiveness, and cold start latency.
Why does this matter? Training a large language model can cost millions in compute resources.
A silent GPU memory leak might waste weeks of training time.
An inference endpoint that can’t scale during traffic spikes directly translates to lost revenue and degraded user experience.
Infrastructure observability prevents outages, optimizes costs, and ensures the stability that production AI systems demand.
In 2026, with AI workloads increasingly distributed across edge devices, private clouds, and specialized AI chips, infrastructure observability has become more complex than ever.
Organizations need real-time visibility into heterogeneous compute environments to maintain the performance and reliability their AI systems require.
Data Observability Layer
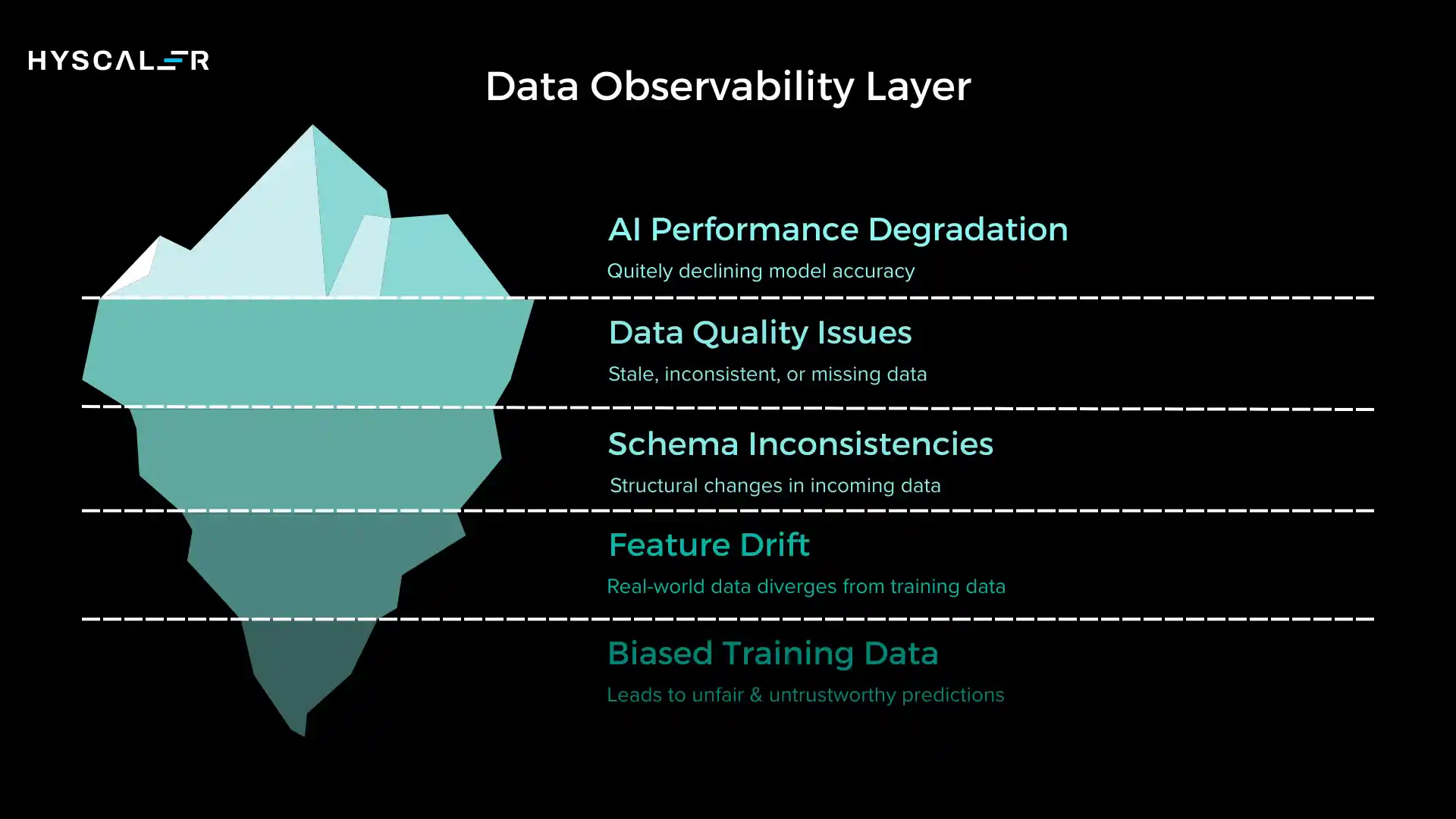
Data is the lifeblood of AI systems, and the data observability layer ensures that the blood remains healthy.
This layer monitors input data quality, freshness, schema consistency, and drift, the silent killers of AI performance.
Core capabilities include schema validation to detect structural changes in incoming data, freshness monitoring to identify stale or delayed data feeds, statistical profiling to detect anomalies in feature distributions, and feature-drift detection to flag when real-world data diverges from training data.
You’re also tracking missing values, outliers, data volume anomalies, and correlation shifts between features.
Why does this matter? Data issues silently break AI systems.
A model trained on summer data will underperform in winter if seasonal drift isn’t detected.
A schema change in an upstream system can cause cascading failures across your ML pipeline.
Biased training data leads to biased predictions, creating compliance and reputational risk.
The insidious nature of data problems is that they rarely cause system crashes, but they cause quiet degradation.
Your models keep running, your APIs keep responding, but the predictions slowly become less accurate, less fair, less trustworthy.
Data observability surfaces these issues before they impact users, enabling proactive intervention instead of reactive damage control.
Model Observability Layer
The model observability layer monitors AI model behavior in production, tracking whether models maintain their predictive quality as the world evolves around them.
This is where you measure whether your AI is still intelligent or if it’s degrading into noise.
Key metrics include prediction accuracy and confidence scores, concept drift (when the relationship between features and outcomes changes), prediction distribution shifts, model bias across demographic groups, and error rate analysis by segment.
You’re also tracking model version performance, A/B test results, champion/challenger comparisons, and retraining trigger signals.
Advanced model observability includes shadow model deployment, where new model versions run alongside production models for comparison without user impact.
You’re monitoring for accuracy decay patterns, identifying which data segments show performance degradation, and detecting when model assumptions no longer match reality.
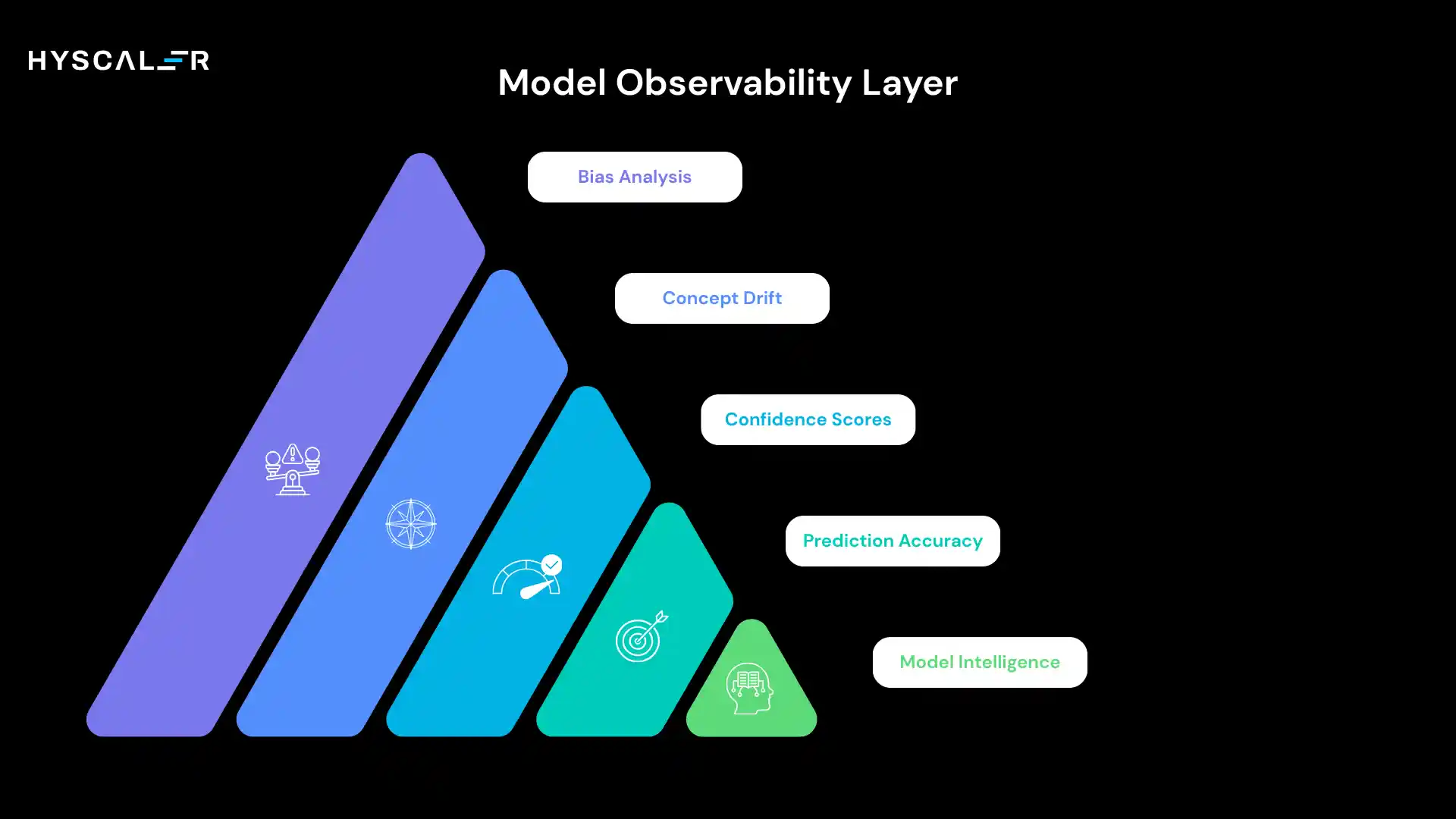
Why it matters: Models trained on historical data don’t automatically stay accurate.
Consumer behavior changes, economic conditions shift, competitors enter markets, and global events disrupt patterns.
A fraud detection model trained before a new scam emerges will miss that fraud.
A recommendation engine trained pre-pandemic won’t understand post-pandemic preferences.
Model observability ensures you know when retraining is needed, which model versions perform best, and whether your AI is delivering the intelligence it promises.
Application & Pipeline Observability Layer
AI doesn’t run in isolation; it runs within complex application architectures and data pipelines.
The application and pipeline observability layer monitors end-to-end AI workflows, from feature extraction through model inference to result delivery.
This layer tracks feature store operations, API gateway performance, inference pipeline health, orchestration workflow status, and dependency chains.
You’re monitoring service-level objectives, request success rates, data transformation failures, caching effectiveness, and integration points with downstream systems.
Critical focus areas include feature engineering pipeline reliability, ensuring features are computed correctly, and delivered on time.
Model serving infrastructure, tracking how models are loaded, versioned, and invoked.
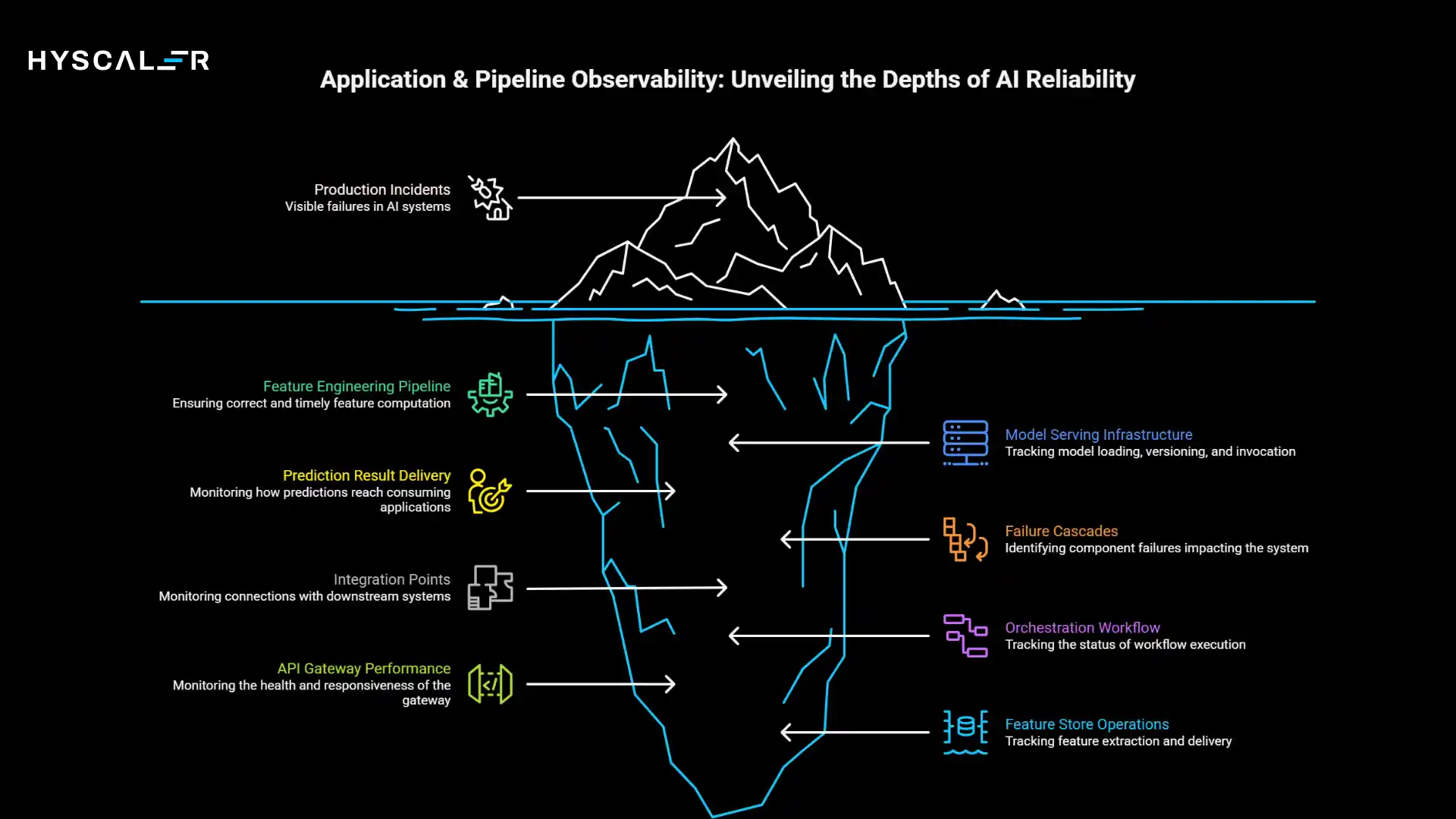
Prediction result delivery, monitoring how predictions reach consuming applications, and failure cascades, identifying when one component’s failure impacts the entire system.
Why does this matter? An AI model is only as reliable as the pipeline that feeds and serves it.
A feature store outage means models receive incomplete data.
An API gateway failure means predictions never reach users.
An orchestration error means pipelines don’t execute when scheduled.
The application and pipeline layer ensures system resilience, catching integration failures, dependency breaks, and workflow errors that would otherwise cause production incidents.
In modern AI systems with microservices architectures, distributed inference, and real-time feature computation, pipeline observability is what prevents death by a thousand cuts, the accumulation of small failures that collectively break the user experience.
Explainability & Transparency Observability Layer
As AI systems make increasingly consequential decisions, the explainability and transparency layer answers the critical question: why did the AI make this decision?
This layer monitors and records the reasoning behind AI outputs, enabling interpretation, debugging, and compliance.
Key capabilities include feature attribution (which inputs drove this prediction), reasoning trace capture (especially for LLMs and agents), decision path logging, confidence scoring with uncertainty quantification, and counterfactual analysis (what would change the decision).
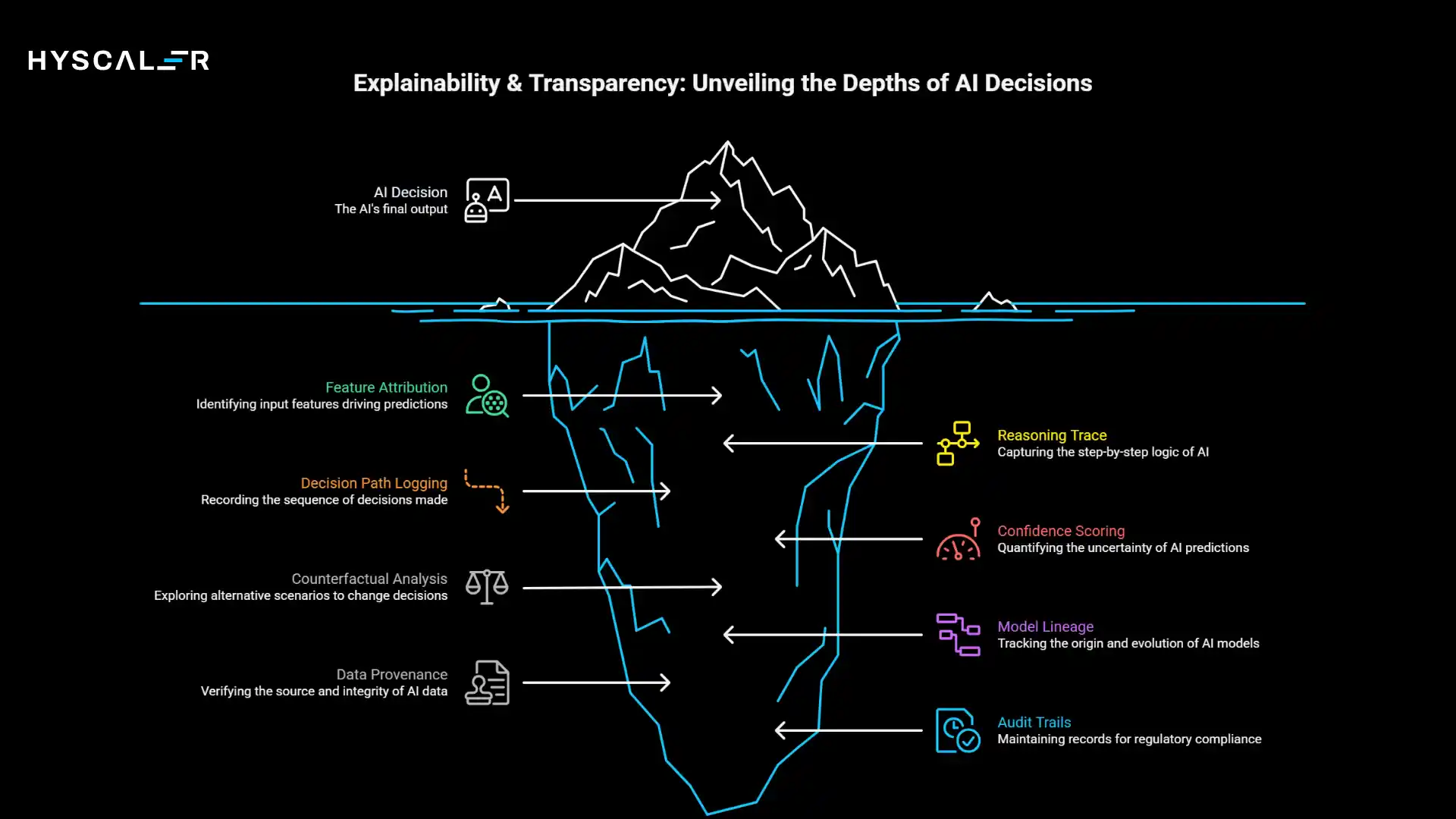
You’re also tracking model lineage, data provenance, and audit trails for regulatory compliance.
For traditional ML models, this means tracking SHAP values, feature importance scores, and decision boundary visualizations.
For large language models, it means capturing prompt inputs, retrieval context, chain-of-thought reasoning, and generated outputs.
For agentic AI, it extends to tool selection rationale, multi-step planning logic, and autonomous action justification.
Why it matters: Compliance and audit readiness are no longer optional in 2026.
The EU AI Act, US state-level AI regulations, and industry-specific frameworks increasingly require explainability for high-risk AI applications.
Financial institutions must explain credit decisions.
Healthcare systems must justify diagnostic recommendations.
Hiring platforms must defend candidate rankings against bias claims.
Beyond compliance, explainability builds trust.
Doctors are more likely to use AI diagnostic tools if they understand the reasoning behind them.
Customers trust recommendations when they see why they were made.
Internal stakeholders approve AI investments when they can validate that systems work as intended.
The explainability layer transforms AI from a black box into a transparent partner.
Security & Trust Observability Layer
AI systems face unique security threats that traditional security tools weren’t designed to detect.
The security and trust observability layer monitors AI-specific attacks, abuse patterns, and trust violations, protecting systems from adversarial manipulation and misuse.
Critical monitoring areas include adversarial attack detection (input perturbations designed to fool models), prompt injection and jailbreak attempts for LLMs, model extraction and theft attempts, data poisoning in training pipelines, and model abuse patterns (using AI for unintended or harmful purposes).
You’re tracking authentication and authorization for model access, API rate limiting and quota enforcement, and sensitive data exposure in model outputs.
For agentic AI systems, security observability extends to autonomous action validation (ensuring agents don’t take harmful actions), tool access control monitoring, and sandbox escape detection.
You’re also monitoring for hallucinations in LLMs, bias amplification, and output safety violations.
Why it matters: AI attacks are increasingly sophisticated and costly.
Adversarial inputs can cause misclassification with significant consequences. Imagine manipulating a self-driving car’s perception or bypassing a security screening model.
Prompt injection attacks trick LLMs into revealing sensitive information or performing unauthorized actions.
Model extraction allows competitors to steal intellectual property worth millions in training costs.
The security layer plays a critical role in Zero Trust AI architectures, where every request is verified, every model invocation is logged, and every anomaly is investigated.
As AI systems gain more autonomy and access to sensitive systems, security observability transitions from a nice-to-have to a business-critical capability.
Business & Outcome Observability Layer
The business and outcome observability layer measures what ultimately matters: is AI delivering value?
This layer bridges the gap between model metrics and business impact, tracking KPIs, ROI, SLA alignment, and the real-world outcomes AI systems are designed to improve.
Key metrics include business KPI impact (revenue, conversion, retention, cost savings), prediction-to-outcome correlation (did accurate predictions lead to better decisions), SLA compliance (latency, availability, throughput guarantees), user engagement with AI features, and cost per prediction or transaction.
You’re also tracking opportunity cost, model value attribution, and competitive advantage metrics.
Advanced organizations monitor leading indicators of business impact, not just lagging outcomes.
For a recommendation engine, you’re tracking not just sales but also click-through rates, add-to-cart actions, and session engagement.
For fraud detection, you’re monitoring not just fraud caught but also false positive rates that frustrate legitimate customers.
Why it matters: Technical excellence is meaningless without business results.
A model with 99% accuracy that generates predictions too slowly to be useful has failed.
An explainable AI system that doesn’t improve decision quality is just overhead.
The business layer aligns AI investments with organizational goals, proves ROI to stakeholders, and identifies where AI creates a competitive advantage versus where it’s a commodity cost center.
In 2026, as AI budgets come under increasing scrutiny, business observability is what separates AI programs that scale from those that get defunded.
It’s the difference between “our AI is accurate” and “our AI increased revenue by 12% this quarter.”
AI Observability Layers Explained in One Table
| Layer | Core Question | Why It Matters |
| Infrastructure | Is AI running reliably? | Prevents outages & cost overruns |
| Data | Is the input data trustworthy? | Avoids silent model failure |
| Model | Is the model still accurate? | Maintains prediction quality |
| Pipeline | Is AI delivery intact? | Ensures system resilience |
| Explainability | Can decisions be explained? | Builds trust & compliance |
| Security | Is AI being attacked? | Protects AI systems |
| Business | Is AI delivering value? | Aligns AI with outcomes |
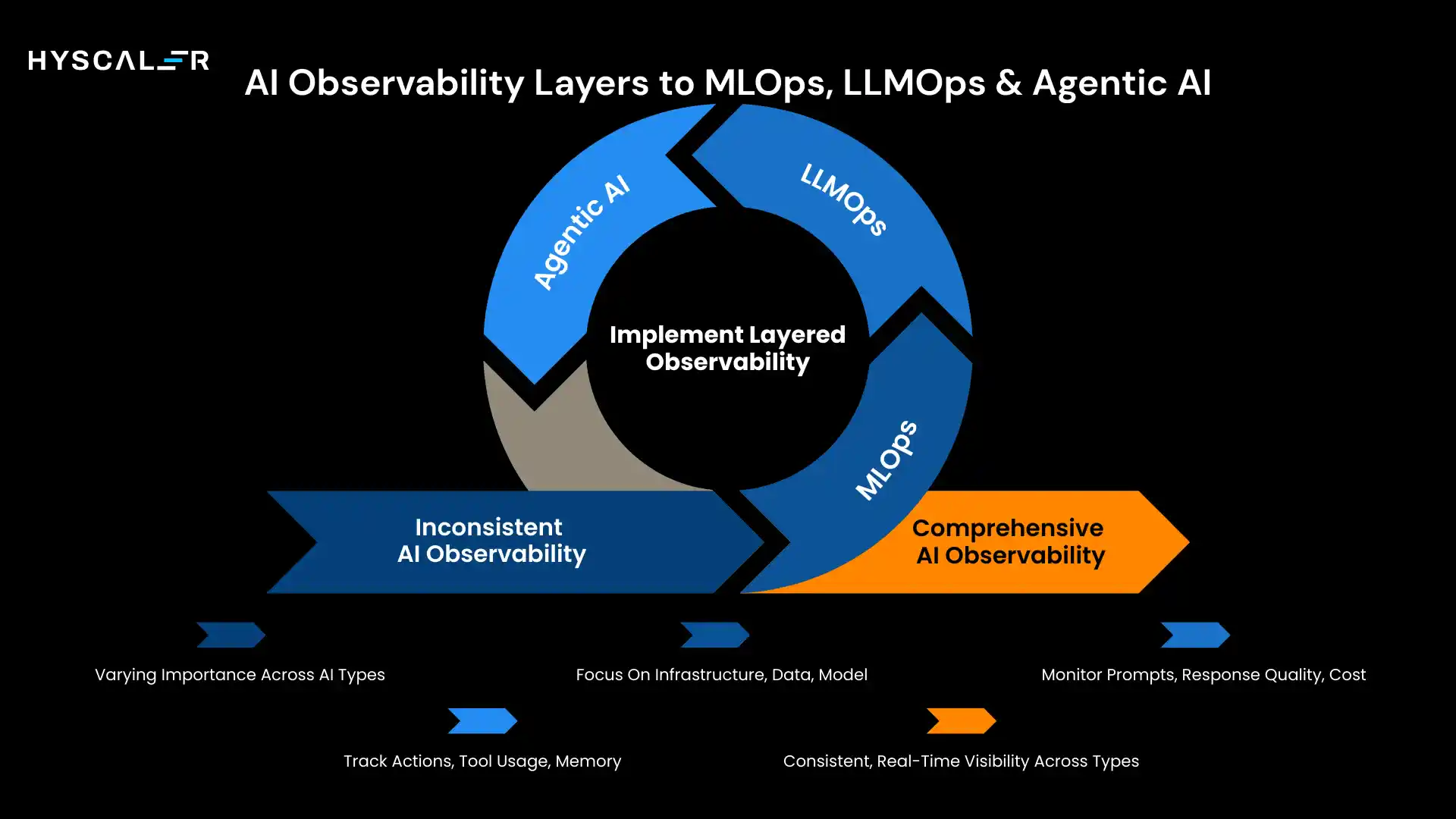
Mapping AI Observability Layers to MLOps, LLMOps & Agentic AI
The seven observability layers apply across all AI paradigms, but their relative importance and implementation vary significantly between traditional MLOps, LLMOps for large language models, and Agentic AI systems.
MLOps Observability Mapping
Traditional machine learning operations place a strong focus on infrastructure, data, model, and pipeline layers.
MLOps workflows involve training models on historical data, validating performance, deploying to production, and monitoring for drift that signals retraining needs.
Infrastructure observability ensures training jobs complete successfully and inference endpoints meet latency requirements.
Data observability catches feature engineering errors and training data quality issues.
Model observability tracks prediction accuracy and detects concept drift.
Pipeline observability ensures orchestration workflows execute reliably.
The primary goal is model reliability and reproducibility.
Can we train the same model again and get consistent results? Does the model maintain performance over time? Are predictions accurate and timely?
MLOps observability is mature and well-understood, with established tools and practices.
LLMOps Observability Mapping
Large language model operations shift emphasis to prompt monitoring, response quality, latency, cost per token, and hallucination detection.
Unlike traditional ML, where input features are structured and predictable, LLMs process free-form natural language with infinite variation.
Security observability becomes critical as prompt injection attacks, jailbreak attempts, and adversarial inputs pose unique threats.
You’re monitoring for attempts to extract training data, manipulate model behavior, or bypass safety guardrails.
Prompt sanitization, output filtering, and abuse detection are essential.
Explainability shifts to response traceability. Instead of feature importance, you’re capturing retrieval-augmented generation context, chain-of-thought reasoning steps, and token probability distributions.
You need to explain not just “why this classification” but “why this entire generated response.”
Cost observability becomes paramount as token usage directly impacts bills.
You’re tracking cost per request, optimizing prompt efficiency, and balancing quality versus expense.
Infrastructure observability extends to GPU memory for large model loading and key-value cache management for faster inference.
Agentic AI Observability Mapping
Agentic AI systems, autonomous agents that plan, reason, use tools, and take actions, require the most comprehensive observability.
Observability extends beyond model outputs to agent actions, tool usage, memory management, multi-step planning, and autonomy boundaries.
You’re monitoring decision path tracing (why did the agent choose this action sequence), intent validation (is the agent pursuing the correct goal), tool invocation logs (which APIs and databases did it access), memory retrieval patterns (what information is it using to make decisions), and action success rates (did the intended actions achieve intended outcomes).
Security observability becomesa very high priority as agents have real-world access and autonomy.
You’re monitoring for unintended actions, privilege escalation attempts, sandbox escape, and drift from intended behavior.
Agent observability must answer: Is this agent safe to run unsupervised?
Business observability becomes continuous and real-time, not batch.
As agents make autonomous decisions, you need instant visibility into business impact.
Is the customer service agent resolving issues effectively? Is the trading agent making profitable decisions? Is the coding agent introducing bugs?
Comparison Table: MLOps vs LLMOps vs Agentic AI Observability
| Observability Area | MLOps | LLMOps | Agentic AI |
| Infrastructure | High | High | High |
| Data Quality | High | Medium | Medium |
| Model Behavior | High | Medium | Medium |
| Prompt / Reasoning | Low | High | Very High |
| Security Risks | Medium | High | Very High |
| Business Impact | Medium | High | Real-time |
Conclusion: Why Layered AI Observability Is Essential in 2026

AI systems in 2026 are autonomous, distributed, and heavily regulated.
They make consequential decisions affecting millions of users, operate across hybrid cloud and edge environments, and face scrutiny from regulators, customers, and internal stakeholders demanding transparency and accountability.
Single-layer monitoring, tracking just infrastructure, or just model accuracy, is no longer sufficient.
The complexity of modern AI requires comprehensive visibility across all seven layers simultaneously.
Infrastructure observability without data quality monitoring misses silent degradation.
Model accuracy without explainability fails compliance.
Security without business impact tracking means you’re protecting systems whose value you can’t measure.
Layered AI observability enables trust by providing evidence that AI systems work as intended, comply with regulations, and are protected from threats.
It enables control by giving operators the visibility needed to intervene before failures cascade.
It enables business alignment by connecting technical metrics to organizational outcomes.
In 2026, observability is no longer a DevOps best practice adapted for AI, and it’s a core enterprise AI capability, as fundamental as the models themselves.
Organizations that master layered observability will build AI systems that are reliable, trustworthy, and business-critical.
Those that don’t will struggle with production failures, compliance violations, and the inability to prove that their AI investments deliver value.
The question is no longer whether to implement AI observability, but how quickly you can build the layered framework that modern AI systems demand.
Frequently Asked Questions (FAQ)
What is the difference between AI monitoring and AI observability?
Monitoring tells you when something is wrong by tracking metrics like latency or errors.
Observability tells you why it’s wrong by using logs, traces, and context to understand system behavior.
AI observability goes further, helping you understand how complex AI systems behave, not just whether they’re running.
Which layer of AI observability should I implement first?
Start with infrastructure and model observability for production stability, then add data observability to prevent silent failures.
LLM teams should prioritize prompt and security observability early, while traditional ML teams should focus on pipeline observability first.
How does AI observability differ from traditional software observability?
Traditional observability tells you if the system is working.
AI observability tells you if the AI is working correctly and why it behaves the way it does.
Is AI observability required for regulatory compliance?
Yes. Regulations like the EU AI Act and emerging US frameworks require explainability, bias monitoring, and audit trails.
AI observability provides this visibility, helping organizations meet compliance through explainability, security, and data tracking.
Can I use my existing observability tools for AI systems?
Partially. Tools like Prometheus, Grafana, and DataDog monitor infrastructure well but lack AI-specific features like drift detection, explainability, and prompt tracking.
Most organizations need specialized AI observability tools alongside traditional monitoring.
How do I measure the ROI of AI observability investments?
Track fewer production incidents, faster detection and resolution, cost savings from early drift detection, and improved audit efficiency.
Business observability shows ROI by linking AI performance to revenue and risk reduction.
What’s the biggest mistake organizations make with AI observability?
Common mistakes: implementing observability too late and focusing too narrowly on infrastructure or model accuracy.
Effective AI observability must cover data, models, security, and business impact from day one.
How does observability change for agentic AI versus traditional ML?
Agentic AI needs real-time observability of decisions, tool use, and multi-step reasoning, not just batch monitoring.
Security, explainability, and continuous business impact tracking are critical because agents act autonomously.