Table of Contents
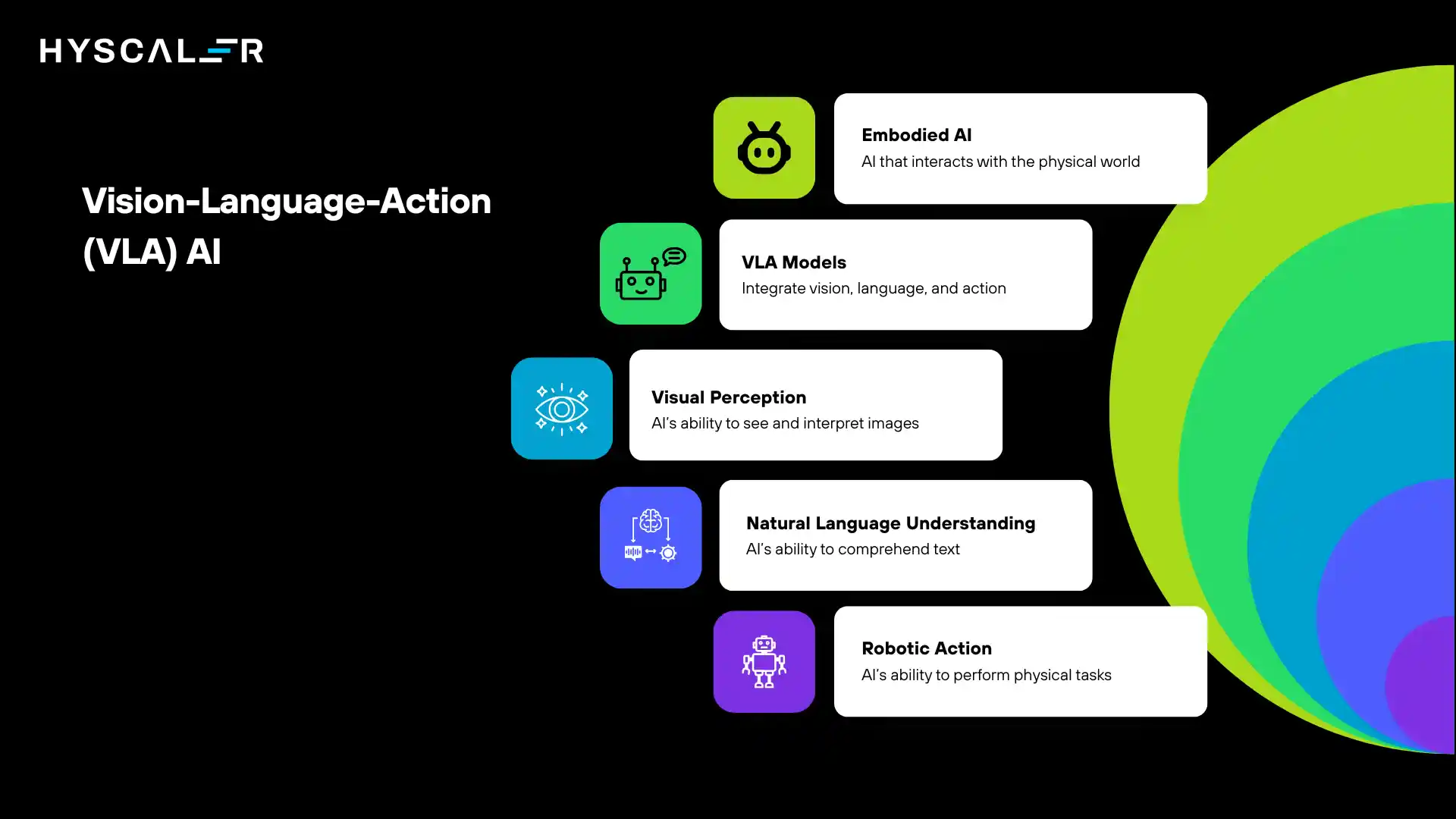
What is Vision-Language-Action (VLA)?
Vision-Language-Action (VLA) models represent a revolutionary leap in artificial intelligence, moving beyond traditional perception-only AI to create AI systems that can see, understand, reason, and physically act in the real world.
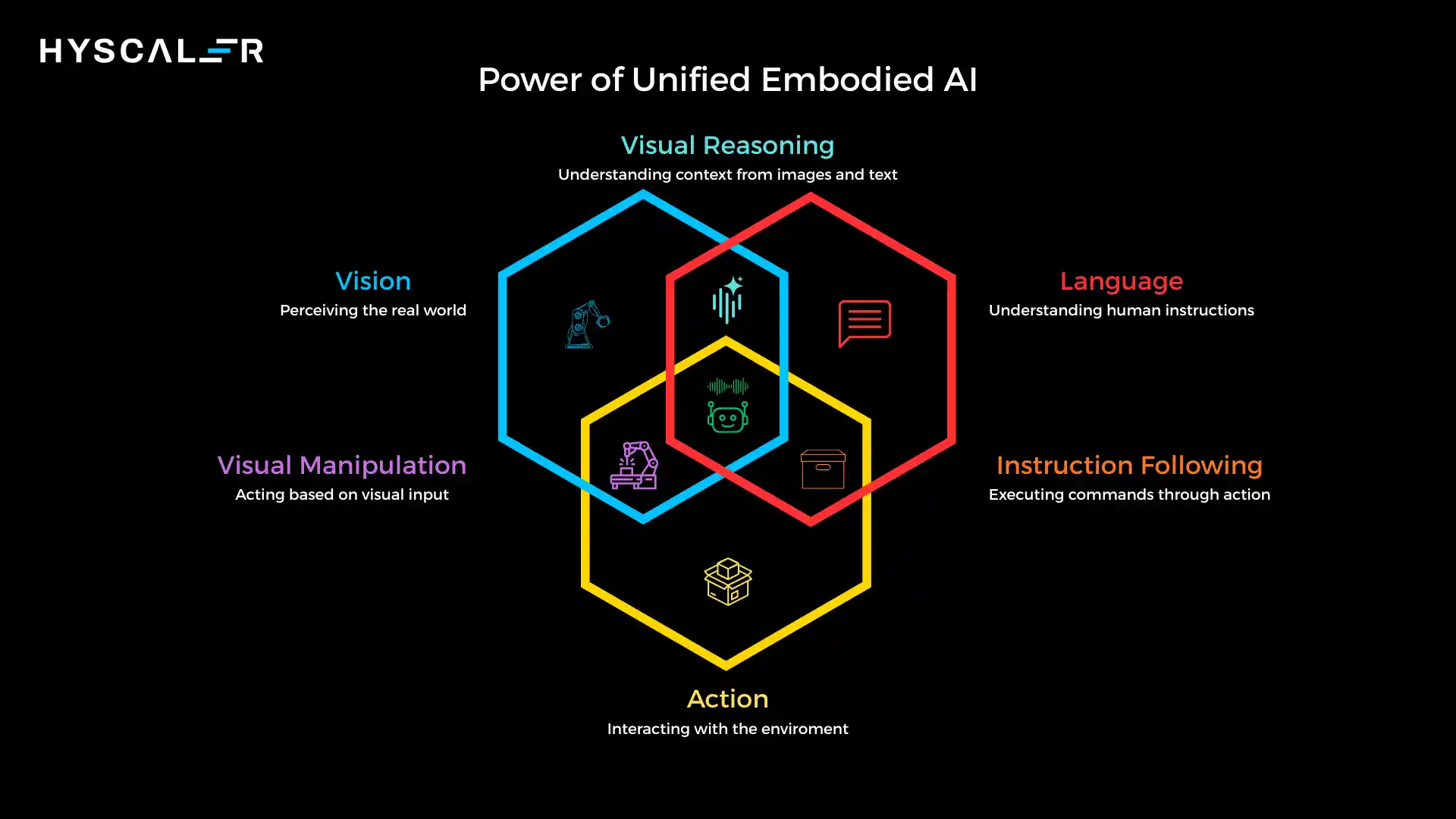
These multimodal foundation models integrate visual perception, natural language understanding, and robotic action into a unified framework, enabling machines to perform complex tasks in dynamic, unstructured environments.
In 2026, VLA models are emerging as the cornerstone of embodied AI, powering everything from warehouse automation to surgical robotics.
Unlike conventional robotic systems that rely on hardcoded rules and task-specific programming, VLA models learn generalizable policies that allow robots to adapt to new situations, understand delicate instructions, and execute multi-step tasks with minimal human intervention.
The shift from perception-only AI to embodied AI represents one of the most significant transitions in the field.
While traditional computer vision models excel at identifying objects in images and large language models can engage in sophisticated reasoning, VLA models bridge the gap between digital intelligence and physical reality.
They don’t just understand the world, they interact with it, translating high-level instructions into precise motor commands that drive real-world outcomes.
Why VLA Is the Next Frontier of Embodied AI
Traditional robotics faces fundamental limitations that VLA models can easily overcome.
Conventional robots operate within tightly controlled parameters, requiring hardcore manual programming for each new task or environment.
When conditions deviate from expected norms, an object moves slightly, lighting changes, or an unexpected obstacle appears, these systems often fail catastrophically.
Multimodal foundation models have changed the equation.
By training on massive datasets that span visual perception, language understanding, and action trajectories, VLA models develop rich internal representations that capture the relationships between what they see, what instructions mean, and how to accomplish goals.
This foundation allows them to generalize across tasks and environments in ways that were previously impossible.
The rise of general-purpose robotic intelligence marks a paradigm shift.
Rather than deploying specialized robots for each application, organizations can now train versatile systems that adapt to diverse challenges.
A single VLA-powered robot might sort packages in the morning, perform quality inspection after lunch, and assist with restocking in the evening, all while continuously learning and improving from experience.
This flexibility dramatically reduces deployment costs and accelerates the practical adoption of robotics across industries.
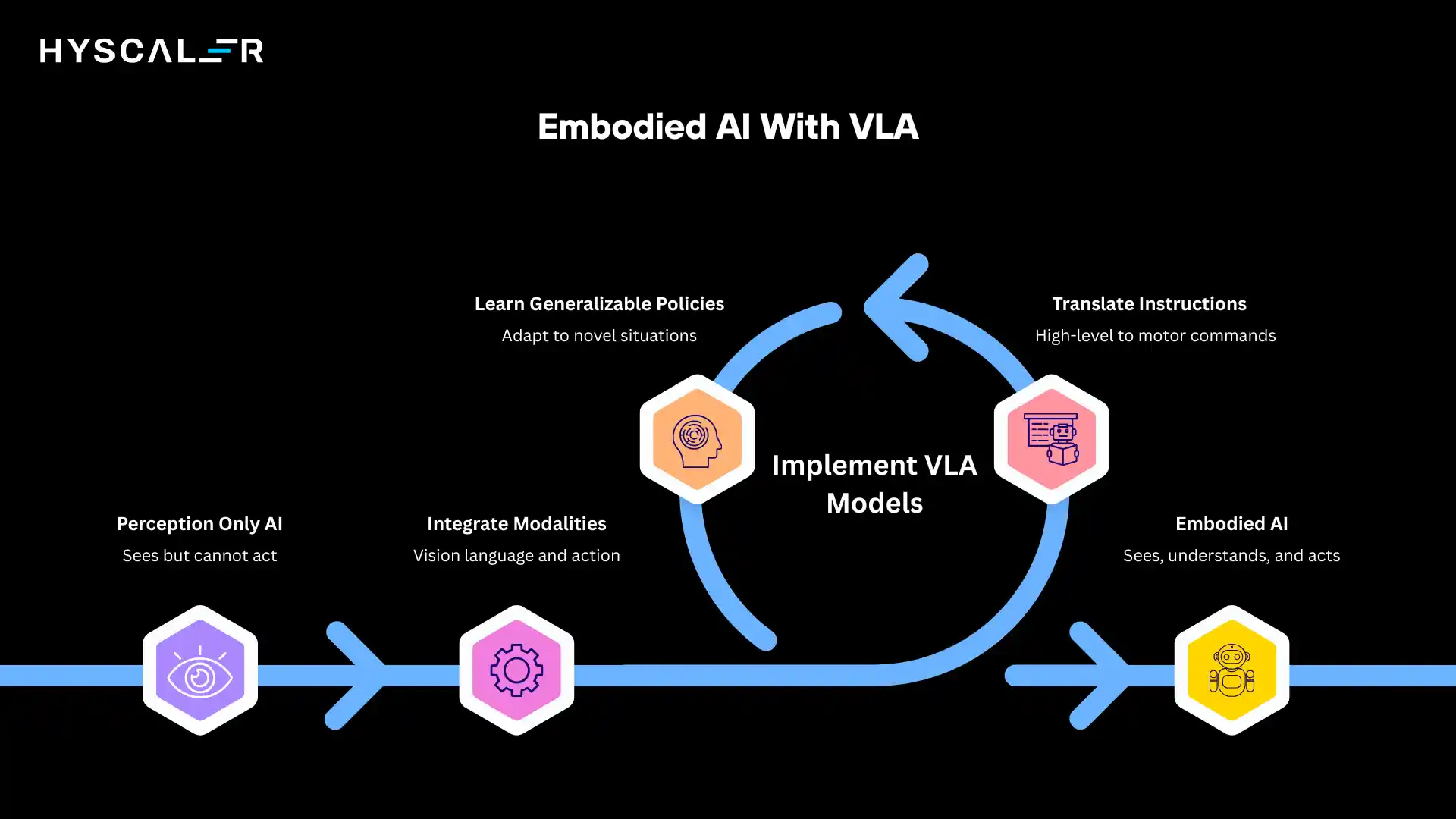
How Vision-Language-Action Models Work
VLA models operate through a sophisticated three-layer architecture that processes sensory inputs, interprets commands, and generates physical actions.
Understanding each component reveals how these systems achieve their remarkable capabilities.
1. Vision Layer (Perception)
The vision layer serves as the eyes of the system, gathering rich environmental data through multiple sensor modalities.
High-resolution cameras capture RGB imagery, providing detailed visual information about objects, textures, and scenes.
LiDAR sensors add precise depth measurements, creating 3D point clouds that enable accurate spatial reasoning.
Some advanced systems also incorporate infrared sensors, radar, or specialized cameras for specific applications.
Object detection algorithms process these inputs to identify and localize items in the environment.
Modern VLA systems use transformer-based architectures rather than traditional convolutional neural networks, allowing them to capture long-range dependencies and contextual relationships.
Spatial reasoning modules compute distances, orientations, and geometric relationships, essential for tasks like grasping objects or navigating through cluttered spaces.
Multimodal encoders fuse information from different sensor types into unified representations.
These encoders learn to align visual features with semantic concepts, creating rich embeddings that bridge the gap between raw pixels and meaningful understanding.
By training on diverse datasets, they develop robust features that generalize across lighting conditions, viewpoints, and environmental variations.
2. Language Layer (Reasoning & Planning)
The language layer interprets human instructions and translates them into actionable plans.
Instruction parsing begins with natural language understanding, where the system analyzes commands to extract intent, objects, spatial relations, and constraints.
Modern VLA models leverage large language model architectures, enabling them to handle cryptic phrasing, implicit context, and complex multi-part instructions.
Task decomposition breaks high-level goals into executable sub-tasks.
When instructed to “prepare the table for dinner,” the system must infer the sequence: retrieve plates from the cabinet, place them on the table, add utensils, arrange napkins, and so forth.
This decomposition requires both world knowledge (what constitutes a dinner setting) and reasoning about action sequences (utensils go beside plates, not under them).
Chain-of-thought planning enables the system to reason through multi-step problems.
Rather than immediately jumping to actions, the model generates intermediate reasoning steps, considering limitations, potential failures, and alternative approaches.
This explicit reasoning improves reliability, makes behavior more interpretable, and allows the system to recover gracefully when initial plans encounter obstacles.
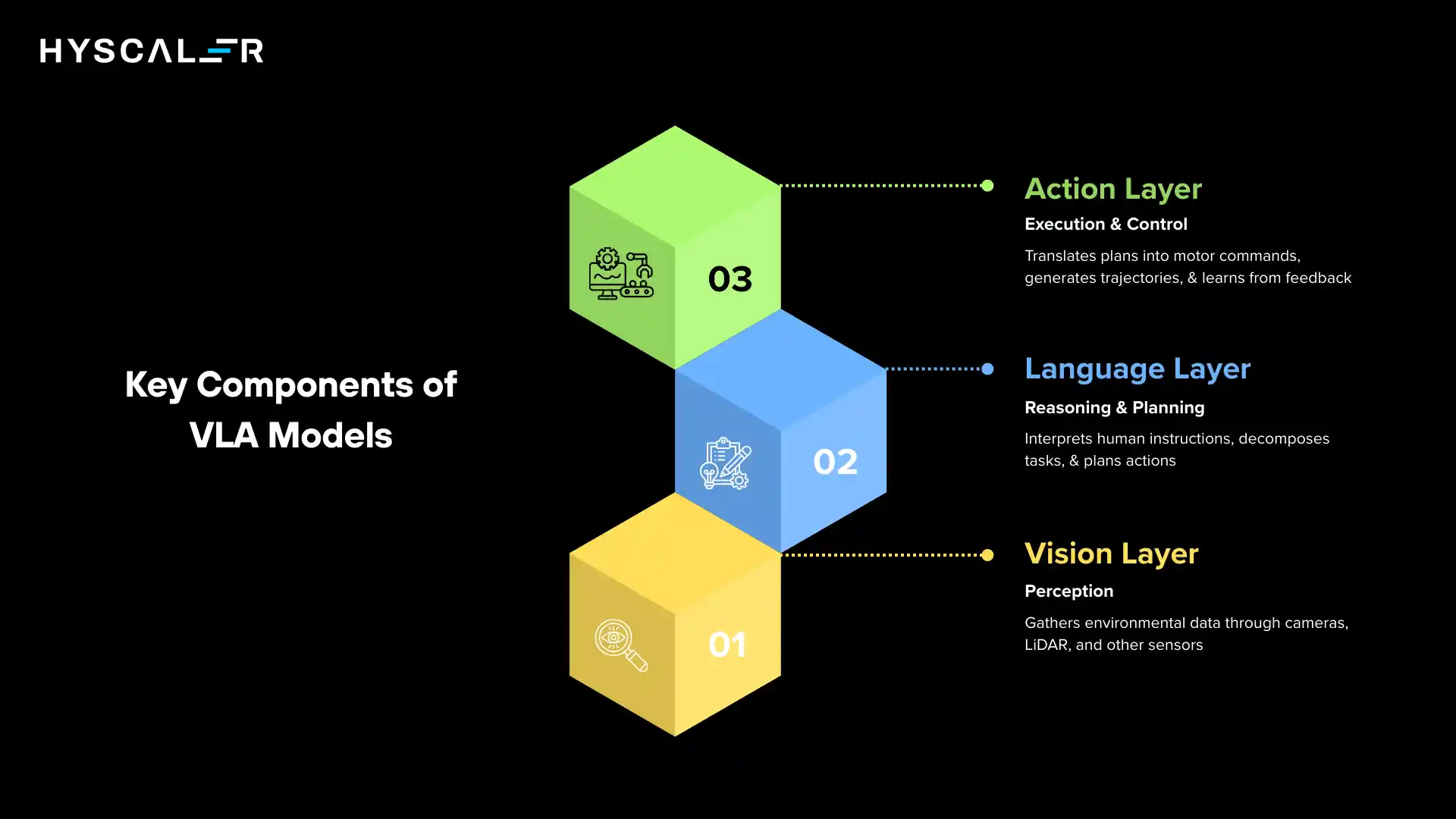
3. Action Layer (Execution & Control)
The action layer translates high-level plans into precise motor commands.
Policy networks learn mappings from observations and goals to control signals, determining joint angles, gripper forces, and movement velocities.
These networks are typically trained using imitation learning on expert demonstrations, then fine-tuned through interaction with the environment.
Motion planning algorithms generate smooth, collision-free trajectories that respect physical constraints and safety requirements.
Modern VLA systems combine learned policies with classical motion planning, leveraging the strengths of both approaches.
The learned component handles complex, high-dimensional decision-making, while traditional planners ensure physical feasibility and safety.
Reinforcement learning feedback loops enable continuous improvement.
As the robot executes tasks, it receives feedback about success or failure, reward signals, and corrections from human operators.
This feedback drives ongoing policy refinement, allowing the system to adapt to new objects, environments, and task variations.
Advanced VLA models can even perform self-supervised learning, generating their own training signals by predicting action outcomes and learning from mismatches.
Vision-Language-Action vs Agentic AI
While VLA models and agentic AI systems both represent advances in autonomous intelligence, they target fundamentally different domains and face distinct challenges.
Understanding the distinction is crucial for organizations evaluating these technologies.
| Feature | Vision-Language-Action (VLA) | Agentic AI |
| Core Domain | Physical world interaction | Digital & cognitive workflows |
| Embodiment | Yes (robots, actuators) | Usually software agents |
| Input | Images + Language | Text, APIs, data streams |
| Output | Physical movement | Decisions, API calls |
| Autonomy | Environmental task execution | Goal-driven task orchestration |
Key Difference:
- VLA = Embodied Intelligence: Systems that perceive and physically manipulate the world
- Agentic AI = Autonomous Decision Intelligence: Systems that reason, plan, and coordinate digital actions
VLA operates in the physical world, managing real-time sensorimotor control and dealing with the complexities of physics, while Agentic AI operates primarily in the digital realm, orchestrating workflows, making decisions, and interfacing with software systems.
The former requires millisecond-level feedback loops and safety-critical control, while the latter emphasizes reasoning over extended time horizons and managing complex dependencies across digital tools.
Enterprise Use Cases of Vision-Language-Action (2026)
VLA models are transforming operations across diverse industries, delivering measurable improvements in efficiency, accuracy, and flexibility.
The following applications represent the current state of enterprise deployment:
Smart warehouses:
VLA-powered robots navigate complex warehouse environments, picking and placing items with precision.
These systems adapt to new SKUs without reprogramming, handle damaged packaging gracefully, and coordinate with human workers in shared spaces.
Leading logistics companies report 40-60% improvements in picking speed and 25% reductions in error rates.
Autonomous quality inspection:
Manufacturing facilities deploy VLA systems for visual inspection tasks that exceed human consistency.
These robots detect subtle defects, measure tolerances, and classify components with superhuman accuracy.
Unlike traditional machine vision, VLA models generalize to new product lines and adapt to changing quality standards through natural language updates.
Healthcare robotics:
Surgical assistance, medication dispensing, and patient monitoring applications leverage VLA capabilities.
Systems interpret physician instructions, manipulate delicate instruments, and adapt procedures to patient-specific anatomy.
Early trials demonstrate reduced procedure times and improved outcomes for complex interventions.
Retail automation:
Inventory management, shelf restocking, and customer service robots operate in public-facing environments.
These systems navigate crowded stores, interact safely with shoppers, and handle a diverse range of products.
VLA models enable these robots to understand context-dependent requests and adapt to seasonal merchandise changes.
Manufacturing cobots:
Collaborative robots work alongside humans on assembly lines, adjusting to different workstations and tasks throughout the day.
VLA enables intuitive programming through demonstration rather than code, dramatically reducing deployment time from weeks to hours.
Defense & field robotics:
Military and emergency response applications deploy VLA systems for reconnaissance, bomb disposal, and disaster recovery.
These robots operate in GPS-denied environments, interpret complex terrain, and execute multi-step missions with minimal human guidance.
Mapping Vision-Language-Action to MLOps, LLMOps & RoboticsOps
Deploying VLA models in production requires integrating best practices from machine learning operations, language model operations, and robotics-specific workflows.
Each operational domain addresses critical aspects of the VLA lifecycle:
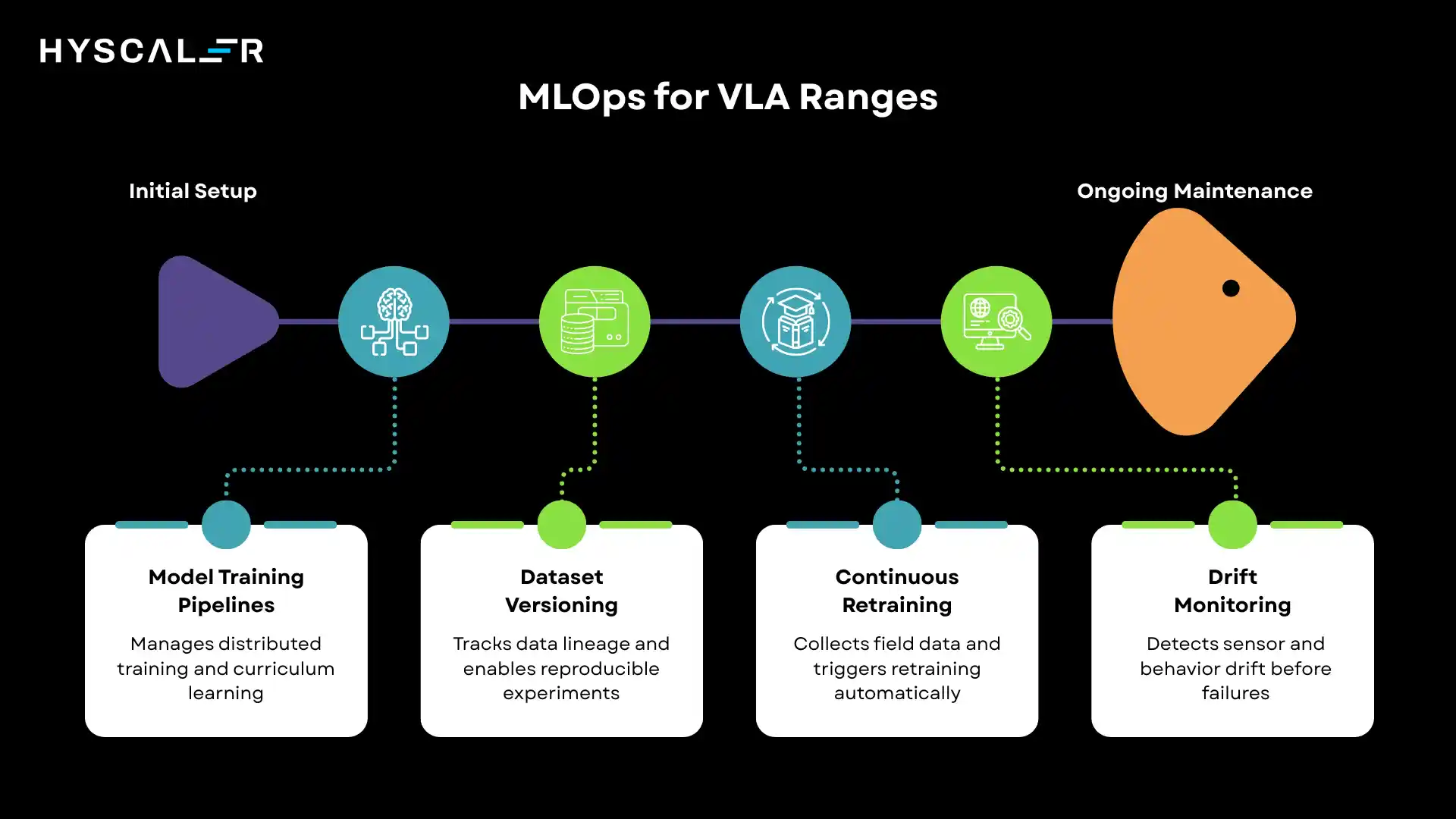
VLA + MLOps
Model training pipelines:
VLA training demands coordination between vision, language, and action components.
MLOps infrastructure manages distributed training across GPU clusters, handles checkpoint synchronization, and orchestrates multi-stage training procedures.
Teams employ techniques such as curriculum learning, in which robots tackle progressively harder tasks as capabilities develop.
Dataset versioning:
VLA datasets include synchronized vision, language, and action trajectories.
Version control systems track data lineage, enable reproducible experiments, and manage privacy-sensitive human demonstration data.
Advanced implementations use data validation pipelines to catch corrupted trajectories or mislabeled demonstrations.
Continuous retraining:
As robots encounter new scenarios, their experiences feed back into training pipelines.
MLOps systems manage the collection, filtering, and incorporation of field data, automatically triggering retraining when performance degrades or new capabilities are needed.
Drift monitoring:
Sensor drift occurs when camera calibration shifts or when actuators wear.
Behavior drift happens when the model’s decision patterns change over time.
MLOps tools detect both forms of drift and alert teams to recalibrate hardware or retrain models before failures occur.
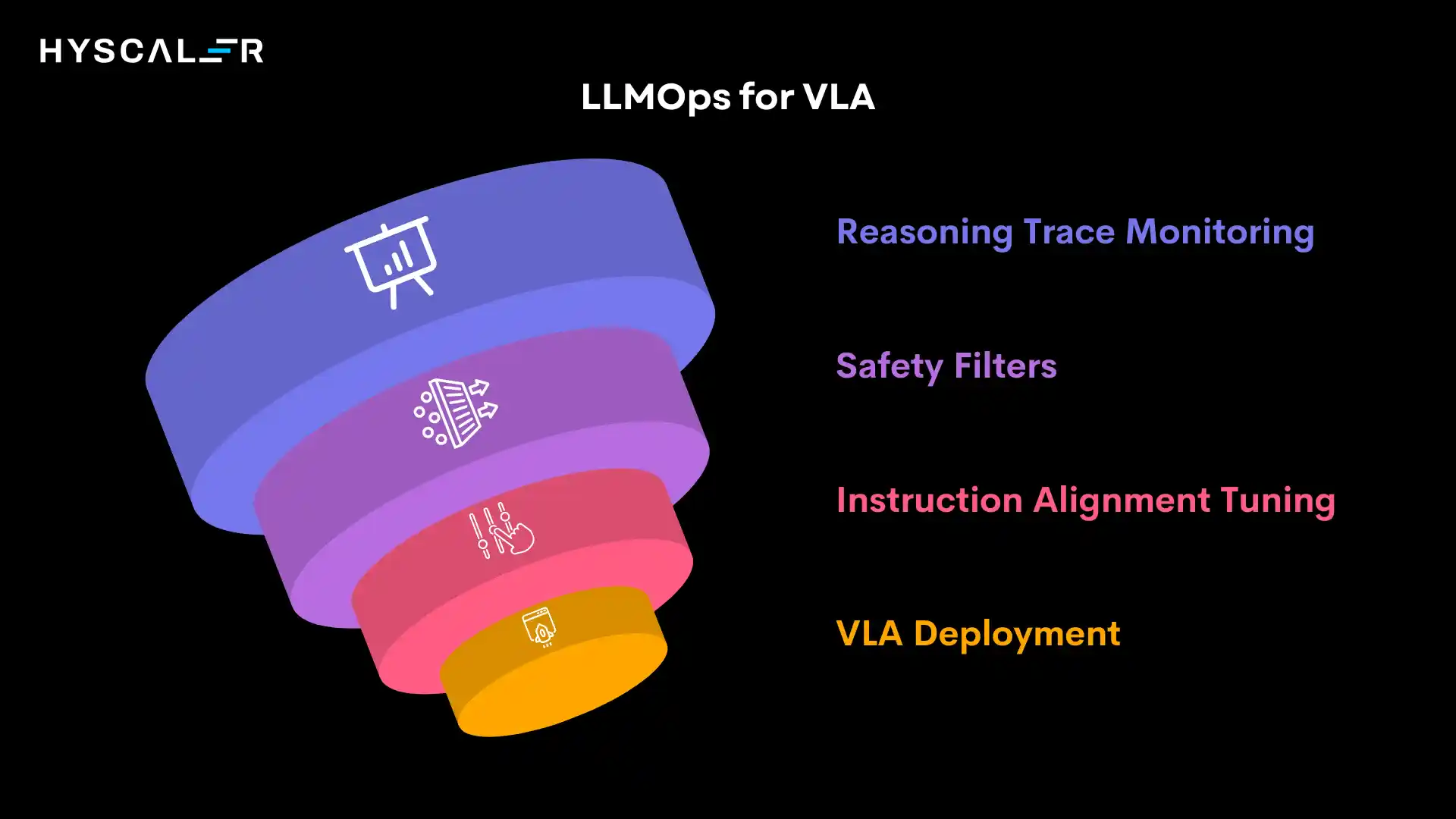
VLA + LLMOps
Prompt engineering for robotic instruction:
Effective VLA deployment requires careful prompt design.
Teams develop instruction templates that specify task constraints, success criteria, and safety boundaries.
LLMOps tools manage prompt libraries, A/B test variations, and track which phrasings yield optimal task completion rates.
Instruction alignment tuning:
VLA models undergo alignment training to ensure they interpret instructions as humans intend.
This involves reinforcement learning from human feedback on task executions, preference modeling over action sequences, and adversarial testing to identify misalignment edge cases.
Safety filters:
LLMOps guardrails prevent VLA systems from executing dangerous actions based on unsafe instructions.
Multi-layer safety mechanisms include semantic filtering of instructions, constraint checking of planned actions, and runtime monitoring of execution trajectories.
Reasoning trace monitoring:
Observability into the model’s reasoning process helps diagnose failures and improve performance.
Teams log chain-of-thought outputs, track attention patterns over visual inputs, and analyze decision pathways to understand why specific actions were chosen.
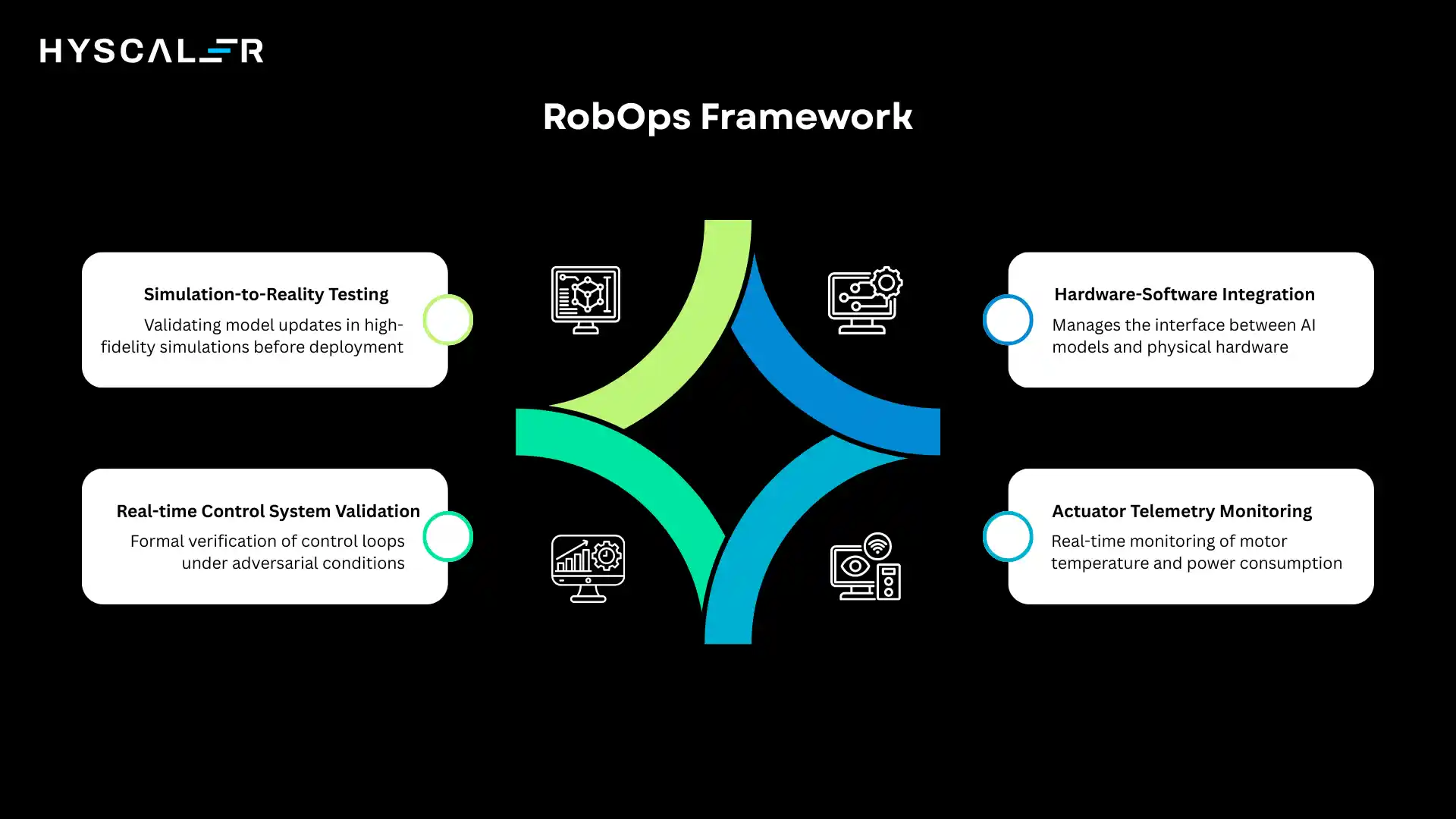
VLA + RoboticsOps (RobOps)
Hardware-software integration:
RobOps manages the interface between AI models and physical hardware.
This includes driver updates, firmware versioning, and compatibility testing across robot platforms.
Teams maintain hardware abstraction layers that allow the same VLA model to control different robot morphologies.
Actuator telemetry monitoring:
Real-time monitoring of motor temperatures, torque levels, and power consumption enables predictive maintenance.
RobOps dashboards surface anomalies that indicate mechanical wear or control instabilities, triggering maintenance before catastrophic failures.
Real-time control system validation:
Safety-critical applications demand formal verification of control loops.
RobOps includes testing frameworks that validate control system behavior under adversarial conditions, ensuring robots remain stable even when AI components produce unexpected outputs.
Simulation-to-reality (Sim2Real) testing:
Before deploying model updates to physical robots, RobOps workflows validate them in high-fidelity simulation.
Automated test suites run thousands of scenarios, identifying edge cases where simulated performance doesn’t transfer to real-world conditions.
In 2026, enterprise VLA deployments require integrated AI observability across perception, reasoning, and action layers.
Organizations that successfully combine MLOps, LLMOps, and RobOps practices achieve higher system reliability, faster iteration cycles, and better safety outcomes than those treating each domain in isolation.
Vision-Language-Action Architecture Diagram (Explained)
The VLA architecture integrates multiple specialized components into a coherent system.
Understanding the information flow through these components clarifies how raw sensory data transforms into coordinated physical actions.
Architecture Flow:
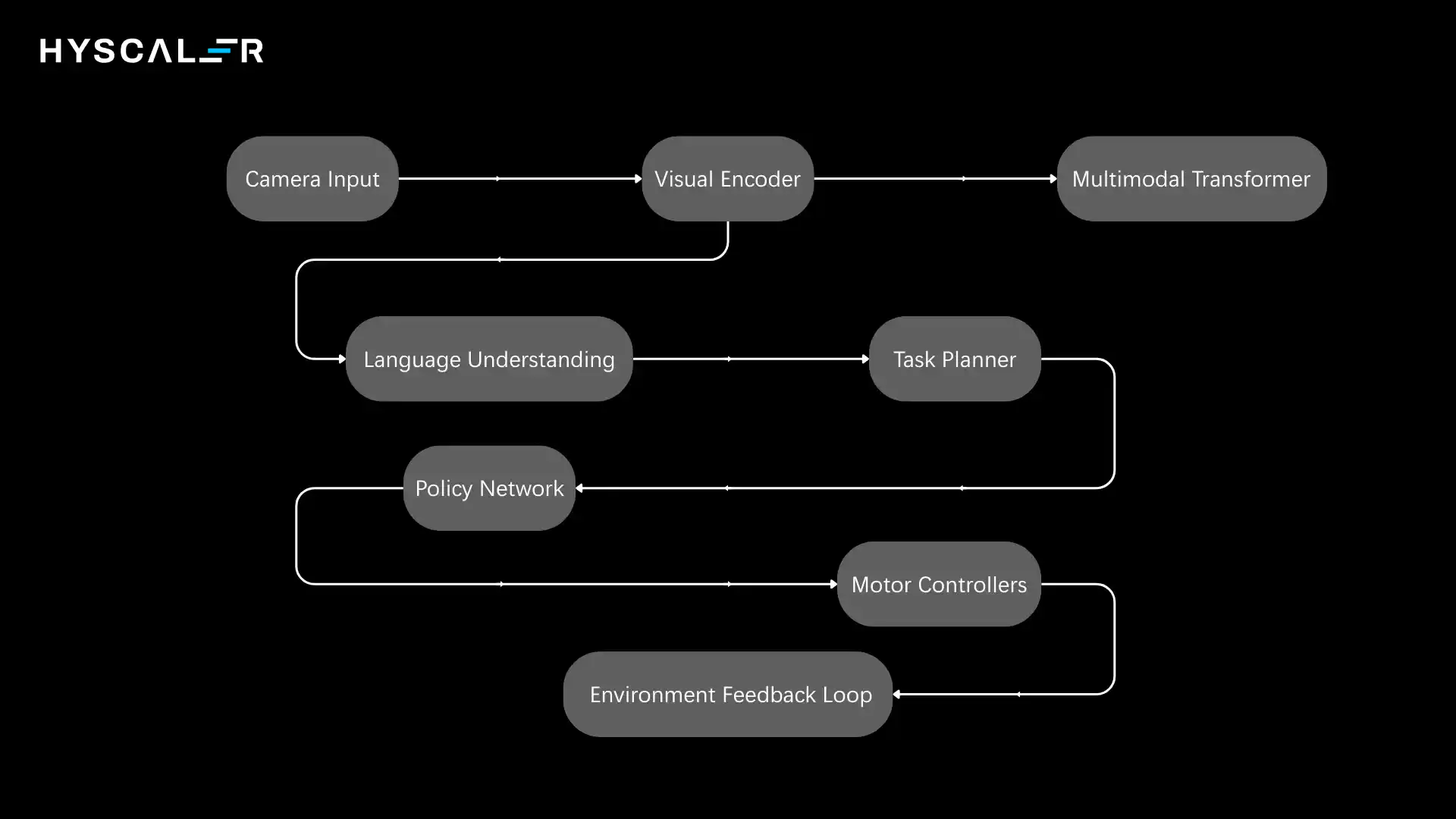
Core Components:
Visual Encoder (CNN / ViT):
Processes raw images into feature representations.
Convolutional neural networks excel at local pattern detection, while vision transformers capture long-range spatial relationships.
Modern VLA systems often use hybrid architectures that combine both approaches.
Language Model (Transformer-based):
Interprets instructions and generates reasoning traces.
Built on architectures like GPT or T5, these models leverage pre-training on massive text corpora before fine-tuning on robotics-specific language.
Cross-Modal Fusion Layer (Language Understanding):
Planning Module:
Decomposes tasks into sub-goals and action sequences.
Uses hierarchical planning to manage complexity, with high-level plans specifying what to accomplish and low-level planners determining how to execute specific motions.
Action Policy Network:
Maps current observations and goals to motor commands.
Trained via behavioral cloning on demonstrations and refined through reinforcement learning, these networks learn control strategies that generalize across situations.
Reinforcement Learning Feedback Loop:
Continuously improve the policy based on task outcomes.
The robot learns from both successes and failures, adjusting its behavior to maximize long-term performance metrics.
Challenges of Vision-Language-Action Models
Despite remarkable progress, VLA models face significant technical and practical hurdles that must be addressed for widespread adoption:
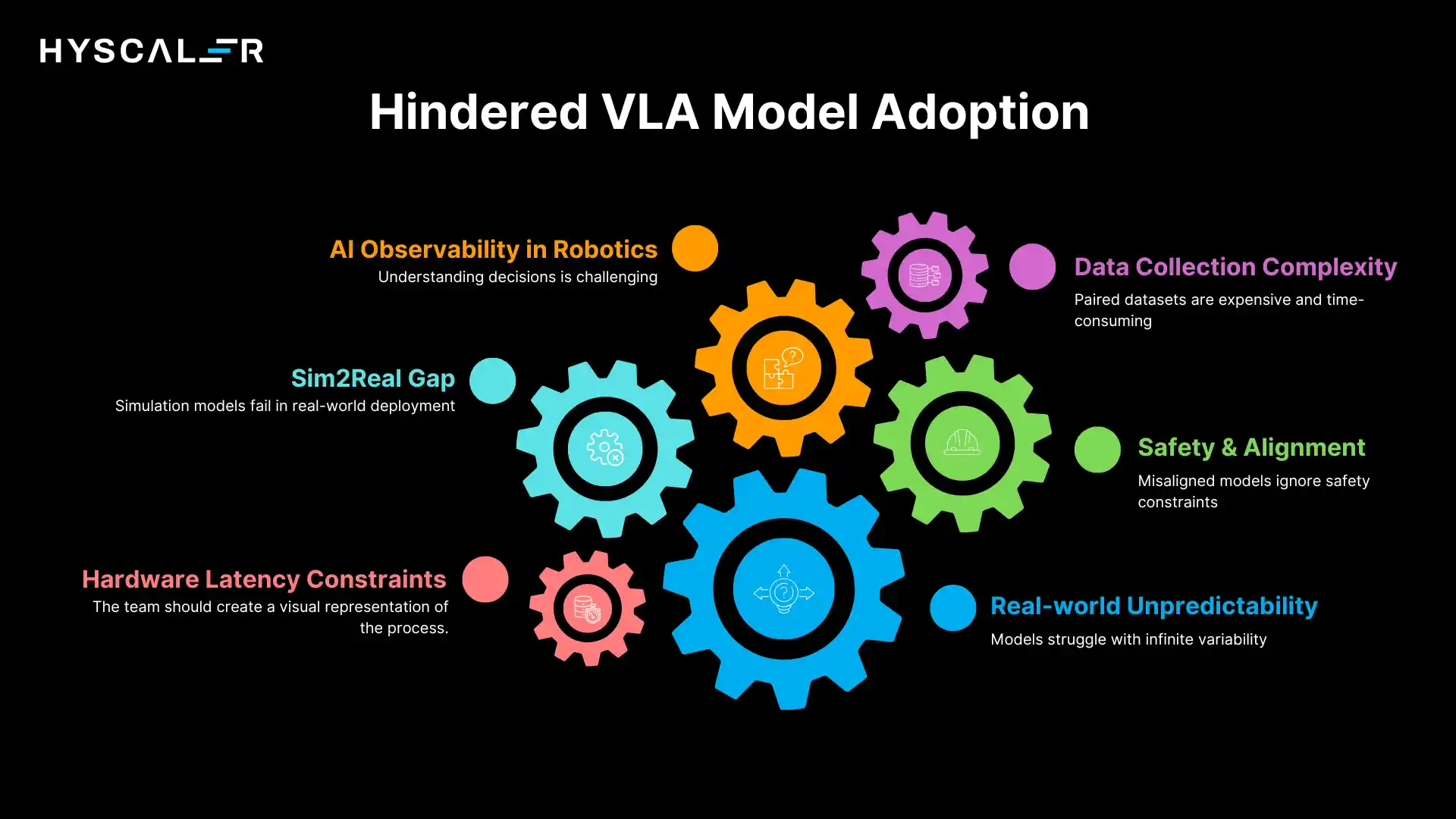
Real-world unpredictability:
Physical environments exhibit infinite variability.
Objects slide unexpectedly, lighting conditions change, humans move unpredictably, and mechanical systems experience random failures.
VLA models must handle this uncertainty gracefully, which requires massive amounts of diverse training data and sophisticated generalization capabilities.
Safety & alignment:
Ensuring VLA systems interpret instructions correctly and act safely is paramount.
Misaligned models might optimize for task completion while ignoring safety constraints, or misinterpret ambiguous instructions in dangerous ways.
Developing robust safety mechanisms that work across diverse scenarios remains an open research problem.
Data collection complexity:
Training VLA models requires paired vision-language-action datasets, which are expensive and time-consuming to collect.
Human demonstrations must be carefully annotated, edge cases deliberately sought, and data quality rigorously validated.
Scaling data collection while maintaining quality presents logistical challenges.
Hardware latency constraints:
Real-time control demands low-latency inference.
VLA models are computationally intensive, processing high-resolution images through deep neural networks at rates of 10-100Hz.
Optimizing these models to run efficiently on robot hardware without sacrificing performance requires careful engineering.
Sim2Real gap:
Models trained in simulation often fail when deployed to real robots.
Simulation cannot perfectly capture physics, sensor noise, or mechanical imperfections.
Bridging this gap requires domain randomization, reality-informed simulation tuning, and careful transfer learning strategies.
AI observability in robotics:
Understanding why a VLA system made specific decisions is challenging.
Unlike software systems, robotic failures have physical consequences, making post-mortem analysis critical.
Developing observability tools that provide actionable insights into multi-modal decision-making remains difficult.
Future of Vision-Language-Action (2026–2030 Outlook)
The trajectory of VLA development points toward increasingly capable, generalizable, and accessible robotic intelligence:
General-purpose home robots:
Within the next few years, we expect VLA-powered robots capable of handling diverse household tasks, cleaning, cooking assistance, elderly care, and maintenance.
These systems will understand natural language instructions, adapt to home environments, and learn family-specific preferences over time.
Autonomous industrial agents:
Manufacturing will see VLA systems that can reconfigure themselves for different products, collaborate with human workers seamlessly, and optimize processes autonomously.
These robots will handle entire production workflows rather than single repetitive tasks.
Real-time adaptive learning systems:
Future VLA models will learn continuously from every interaction, adapting policies in real-time without explicit retraining.
Online learning algorithms will enable robots to handle novel situations by drawing on past experiences and reasoning about analogies.
Foundation robotics models:
Integration with digital twin systems:
VLA models will connect seamlessly with digital twin representations of physical environments.
This integration will enable sophisticated what-if analysis, predictive maintenance, and continuous optimization based on simulated scenarios informed by real-world data.
As these technologies mature, VLA models will transition from specialized research systems to ubiquitous tools that augment human capabilities across virtually every domain involving physical interaction.
The key challenge ahead is ensuring this powerful technology develops safely, equitably, and in alignment with human values.
FAQs
What makes VLA different from traditional computer vision or robotics?
Traditional computer vision focuses on perception, and robotics relies on hardcoded control. VLA combines perception, language, and action into one system, allowing robots to perform new tasks through natural language instructions instead of explicit programming.
Do VLA models require constant internet connectivity?
Not necessarily. Many VLA systems run directly on the robot using edge computing for low latency and offline use. Hybrid setups are also common, with local control and cloud-based processing for complex reasoning when needed.
How much training data does a VLA model need?
Requirements vary by application. Simple tasks need hundreds of demonstrations, while general systems use millions. Foundation models train on large datasets and fine-tune for specific tasks, reducing data needs for new applications.
Can VLA models explain their decisions?
Modern VLA systems use chain-of-thought reasoning to explain their actions in natural language, helping operators understand and debug decisions. However, some low-level control processes remain hard to interpret.
What happens when a VLA model encounters a situation it has never seen before?
Well-designed VLA systems detect uncertainty and unfamiliar situations. They can request human help, use safe fallback actions, or cautiously generalize, ensuring graceful degradation instead of failure.
Are VLA models suitable for small businesses, or only large enterprises?
The VLA ecosystem is becoming more accessible. Pre-trained models and robotics-as-a-service are lowering barriers, and by 2027–2028, VLA robots are expected to be affordable for many SMBs, especially in warehousing, retail, and light manufacturing.
How do VLA models handle safety in human-robot collaboration scenarios?
VLA safety is multi-layered. Hardware sensors and compliant actuators prevent harmful collisions, while software enforces safety-aware actions and constraints. Runtime monitors can emergency-stop robots if needed, though human-robot safety remains an active research area.
What is the environmental impact of deploying VLA models at scale?
VLA deployment has trade-offs. Training uses significant energy, but it’s a one-time cost, and inference can be efficient. VLA automation can reduce waste and improve sustainability, with the overall impact depending on the application.