Table of Contents
It’s really important to understand the key differences between LM Studio vs Ollama, and it lies in knowing their target audience and approach to local AI deployment.
Ollama excels as a production-ready, complete CLI based platform designed for developers who need speed, automation and seamless API integration.
Whereas LM Studio dominates as the user-friendly GUI driven application perfect for business users, junior developers and anyone wanting immediate AI access without technical complexities.
We made this comprehensive analysis that will help tech leaders, developers, and IT decision-makers choose the right tool based on technical requirements, team expertise and business objectives.
Ollama: Developer’s Command Line Interface Powerhouse
Ollama was originally created by Jeffrey Morgan and the team at Ollam Inc. when they saw the need for running LLMs locally. It was built completely from the ground up and is helpful for running LLMs locally wherever you are.
Here’s what the core architecture leverages:
- Go Programming Language for high-performance backend.
- C++ Inference engine (llama.cpp integration)
- REST API architecture
- Model quantization technique for memory optimization
Core Technical Features
1. Production-Ready Architecture
Ollama comes with enterprise grade architectural principles that is designed for reliability and scalability. The production ready architecture means the system is built with fault tolerance, automatic recovery and horizontal scale in mind. Unlike other development tools, production ready systems handle lots of unexpected failures gracefully.
2. API-First Design
The API first approach means ollama was designed from the ground zero to making it highly accessible. Instead of focusing on ollama ui interface first approach they wanted the machines to talk to eachother first with the API first design. Because of this architecture it becomes easier to integrate with existing business systems and automated workflows.
3. Advanced Model Management
- Advanced model versioning and updates.
- Memory-mapped file loading for faster startup
- Multi-model concurrent serving
What’s New In Ollama 2025?
Ollama came up with some new enhanced features, and here is the list of them:
1. Function calling support: LLMs can now interact with external tools and APIs
2. Structured Output Control: Force JSON responses for consistent API integration
3. Extended Model Library: It now supports for Gemma 3, DeepSeek-R1, Phi-4
4. Hardware Optimisation: Improved Apple Silicon and AMD GPU performance
5. OpenAI API Compatibility: Now it’s easier to connect CHATGPT API endpoints.
| Aspect | Details |
| Programming Language | Go (Backend), C++ (Inference) |
| Memory Requirements | 4GB (minimum), 8GB+ Recommended |
| GPU Support | CUDA, ROCm, Apple Metal |
| API Protocol | Rest APL With Streaming Support |
| Model Formats | GGUF, GGML |
LM Studio: GUI Champion For Businesses
LM Studio was developed by Lmnr AI and it was started as a desktop application focused on accessibility and user experience. That’s why you may call it as a GUI champion
Here is the list of technical foundations:
- Electron Framework for cross-platform GUI.
- Python backend with optimised inference design.
- React-based frontend for modern UI/UX.
- Integrated model discovery and management system.
LM Studio Features
1. User-Centric Design
- Easy drag-and-drop model installation.
- Visual performance monitoring.
- Integrated chat interface.
- Real-time token usage tracking
2. Privacy First Architecture
- Complete offline operation facility.
- Local model storage and execution.
- No telemetry or data collection.
3. Business Intelligence Features
- Built-in usage analytics make it easier to track.
- Model performance comparisons.
- Provide team collaboration tools
New Features Of LM Studio In 2025
In 2025 LM Studio came up with major updates, and you must know about it.
- Enhanced Model Library: Gives access to 1000+ pre-configured models.
- Team collaboration: Multi-user workplace management.
- Advanced monitoring: Detailed performance metrics and reporting.
- Plugin Ecosystem: Easy third-party integrations and extensions.
- Mobile Companion: iOS/Android for remote model management.
Technical Specifications
| Aspect | Details |
| Framework | Electron (GUI), Python (inference) |
| Memory Requirements | 8GB minimum, 16GB+ recommended |
| GPU Support | CUDA, OpenCL, Apple Metal |
| Interface | Native desktop application |
| Model Formats | GGUF, GGML, Safetensors |
| Platform Support | Windows, macOS, Linux (beta) |
Comparing Architecture Of LM Studio and Ollama
Let’s understand the technical architecture of both the tools precisely.
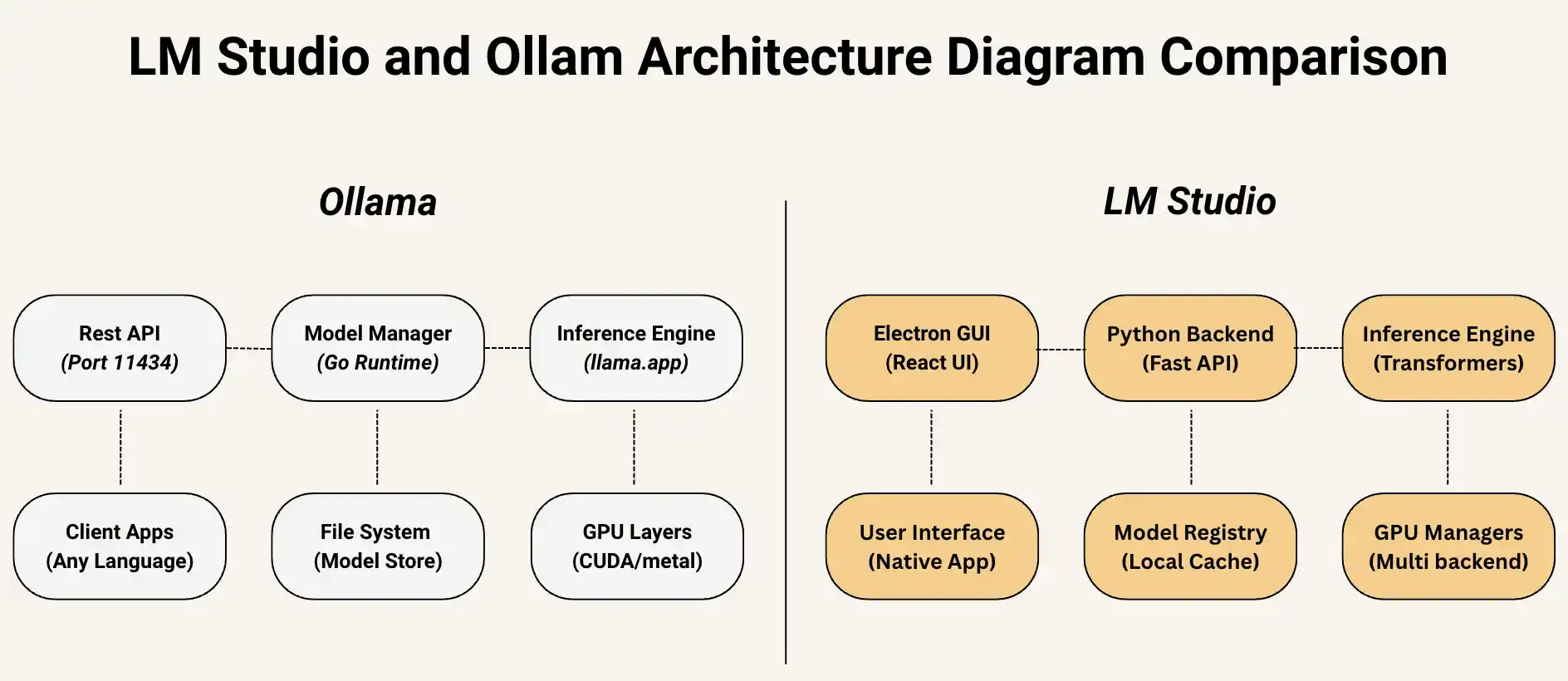
Architecture Comparison Of Both Ollama vs LM Studio
| Component Layer | Ollama | LM Studio | Key Difference |
| Entry point | Rest API (Port 1134) | Electron GUI (React UI) | API-first vs GUI-first approach |
| Core logic | Model Manager (Go Runtime) | Python Backend (FastAPI) | Performance vs flexibility tradeoff |
| AI Processing | Inference Engine (llama.cpp) | Inference Engine (Transformers) | Speed vs compatibility focus |
| Client Access | Client Apps (Any Language) | User Native (Native App) | Developer vs End user targeting |
| Storage | File System (Model Store) | Model Registry (Local Cache) | Simple vs managed approach |
| Hardware | GPU Layers (CUDA/metal) | GPU Managers (multi-backend) | Direct vs abstract control |
How Do People Compare Them In GitHub & Other Communities?
Let’s understand what people say about both LM Studio vs Ollama in GitHub and in different communities.
Ollama GitHub Statistics
| Metric | Values |
| GitHub Stars | 140,000+ |
| Forks | 11,500+ |
| Contributors | 400+ |
| Issues (Open) | 850+ |
| Releases | 50+ |
| Programming Languages | Go (75%), C++ (15%), Python (10%) |
Community Growth
Ollama grew by 180% year over year and that is huge.
- 2023: 5,000 stars
- 2024: 80,000 stars
- 2025: 140,000+ stars
- Growth Rate: 180% year-over-year
LM Studio Community Presence
As LM Studio is a proprietary software, that’s why GitHub metrics are limited to community tools and integrations.
| Metric | Community Projects |
| Related Repositories | 200+ |
| Integration Projects | 50+ |
| Community Tools | 30+ |
| Documentation Projects | 15+ |
| API Wrappers | 25+ |
LM Studio vs Ollama Performance Benchmarks
Hardware Test Configuration
Here are the test system specifications
- CPU – Apple M3 Max (16-Core)
- RAM: 64GB Unified Memory
- GPU: Apple M3 Max GPU (40-core)
- Storage: 2TB NVMe SSD
- Models Tested: Llama 3.2 3B, Phi-4 14B, Mistral 7B
Real-time Benchmark Results
| Test Category | Ollama | LM Studio |
| Cold Start Time | 3.2 seconds | 8.7 Seconds |
| Model Loading | 2.1 Seconds | 5.4 Seconds |
| First Token Latency | 145 ms | 280 ms |
| Tokens/Second | 85.2 t/s | 72.8 t/s |
| Tokens/Second | 42.1 t/s | 35.6 t/s |
| Memory Usage | 4.2GB | 5.8GB |
| CPU Usage (Idle) | 0.8% | 2.4% |
| GPU Utilisation | 95% | 87% |
Real World LM Studio vs Ollama Performance Test
Code Generation Benchmark (1000 lines Python):
- Ollama: 42 seconds
- LM Studio: 58 seconds
Document Summarisation (10,000 words):
- Ollama: 28 seconds
- LM Studio: 35 seconds
LM Studio vs Ollama: Comparison 2025
| Features & Aspects | Ollama | LM Studio |
| Interface Type | CLI + REST API | Desktop GUI |
| Setup Complexity | Moderate (CLI knowledge required) | Simple (Drag & Drop) |
| Model Installation | Command Line (ollama pull) | GUI model browser |
| API access | Native REST API | Local server mode |
| Multi-modal support | Concurrent serving | Model switching |
| Function calling | 2025 Update | None |
| Structured output | JSON enforcement | None |
| Custom Models | Via modelfile | Via import |
| Team Collaboration | None | Updated in 2025 |
| Usage Analytics | Basic lags | Provides advanced metrics |
| Mobile Access | API only | Have companion apps |
| Enterprise SSO | None | Updated in 2025 |
| Plugin system | None | Updated in 2025 |
| Cost | Free, Open Source | (Limited in free plan), Paid tiers |
| Offline Operation | Can be done | Can be done |
Ollama vs LM Studio Reddit Reviews
LM Studio vs Ollama is gaining upvotes quickly then ever.
r/LocalLLaMA Community Feedback
- Top Ollama Reviews (600+ Upvotes)
LM Studio Community Feedback
- Top LM Studio Reviews (300+ Upvotes)
LM Studio vs Ollama: Which One Should You Choose In 2025?
When it come to choosing LM Studio vs Ollama you need to choose any one of them by knowing the right factors
Choose Ollama If You Want:
- Quick production-ready deployment
- Open source and quick solutions
- You need cost-effective scaling
- Enterprise-grade performance
- Maximum customization control
- Ollama UI has improved a lot
Choose LM Studio If You Want:
- You need immediate AI access without coding
- Want intuitive model management
- Require team collaboration features
- You want rapid prototyping capabilities
- User-friendly interface
Final Thoughts
The LM Studio vs Ollama debate often misses the point—these tools excel in different phases of AI development, with LM Studio dominating rapid prototyping while Ollama leads in production deployment.
Both Ollama and LM Studio serve a different purpose but they solve some real-life problems. LM Studio becomes really helpful when it comes to rapid prototyping and model evaluation. And, Ollama becomes useful for deployment and serving business users.
Based on your needs you can choose any one of it.
FAQ
1. Which AI Tools Do You Currently Use And For What Exactly?
There are lot of AI productivity tools you can use that will help you to complete certain tasks faster. But you need to know your goals and requirements to find the right tool and start using them in the right way.
2. Which Is Better Ollama or LM Studio?
Ollama is better for developers and production environments due to its superior performance (20% faster inference), lower memory usage, and API-first design. LM Studio is better for business users and beginners who need a GUI interface, team collaboration features, and visual model management. That will also help you in prototyping.
Choose Ollama if: You’re building applications, need API integration, or prioritise performance and resource efficiency.
Choose LM Studio if: You want drag-and-drop simplicity, team workspace features, or prefer visual interfaces over command-line tools.
3. What Is The Difference Between LLM & LM Studio?
LLM (Large Language Model) refers to the AI models themselves (like Llama 3.2, GPT, or Mistral) – these are the actual artificial intelligence systems that generate text.
LM Studio is a desktop application that helps you run and manage LLMs locally on your computer. Think of it this way: LLMs are like movies, and LM Studio is like a media player that lets you watch them.
LM Studio provides a user-friendly interface to download, configure, and chat with various LLMs without needing technical expertise.
4. How Much RAM Does LM Studio Need?
LM Studio requires a minimum of 8GB RAM, but 16GB+ is recommended for optimal performance.
5. Is Ollama LLM Free?
Yes, Ollama is completely free and open-source under the MIT license. There are no usage limits, subscription fees, or hidden costs.
6. What Are The Benefits Of Using LM Studio?
Top 5 LM Studio benefits:
– User-Friendly GUI: Drag-and-drop model installation, no command-line knowledge required
– Model Discovery: Browse 1000+ preconfigured models with built-in search and filtering
– Team Collaboration: Shared workspaces, usage analytics, and team model management (2025 features)
– Visual Monitoring: Real-time performance metrics, token usage tracking, and resource monitoring
– Enterprise Features: SSO integration, mobile companion apps, and professional support options.
7. Is LM Studio Free?
LM Studio offers both free and paid tiers:
Free Version Includes:
– Unlimited personal use
– Access to all open-source models
– Basic chat interface and model management
– Local processing (no cloud costs)
Paid Enterprise Includes:
– Team collaboration workspaces
– Advanced usage analytics
– Enterprise SSO integration
– Priority technical support
– Mobile companion apps
8. LM Studio vs Ollama: Are They Competing?
Not directly, but there’s growing overlap. LM Studio and Ollama started in different markets but are increasingly competing for the same users as their features converge. With this terminology LM Studio vs Ollama people think they are a direct competitor.
9. Can My PC Run LM Studio?
Yes, it can run if your PC has these specifications RAM 8 GB minimum, storage 10GB+ Free space and CPU should be modern 64-bit processor (Intel/AMD from last 5-7 years). If you have apple with new chips like M1 or M2 or M3 it will give an amazing performance.
10. Is LM Studio Good For Developers?
LM Studio is excellent for developers who want rapid prototyping without CLI setup. It also gives visual comparison of different models and it is helpful for someone who wants ease of access over performance.