Table of Content
Introduction
This Stable Diffusion XL Setup Guide provides a concise, step-by-step instructions for setting up the advanced Stable Diffusion XL AI model, tailored for both beginners and experienced developers in the realm of AI-driven image generation.
What is Stable Diffusion XL?
Stable Diffusion XL is a cutting-edge AI model that generates high-resolution images from textual descriptions. This model, developed by Stability AI, leverages the power of deep learning to transform text prompts into vivid and detailed images, offering new horizons in the field of digital art and design.
Setup Requirements
For a successful Stable Diffusion XL setup, it’s crucial to prepare your environment as follows:
-
Python Installation
Ensure you have Python version 3.10 installed. Python is essential for running the Stable Diffusion XL model.
-
Development Environment Setup
To effectively code and execute Stable Diffusion XL scripts, it\’s crucial to establish a proper development environment. This involves setting up a Python virtual environment, which is key for managing project-specific dependencies and ensuring that your Stable Diffusion XL project remains separate from other Python projects, thus avoiding conflicts. Additionally, using a robust Integrated Development Environment (IDE) like Visual Studio Code or PyCharm is advisable. These IDEs offer valuable features such as syntax highlighting, intelligent code completion, and debugging tools, which are immensely helpful in dealing with the complexities of advanced models like Stable Diffusion XL.
Step-by-Step Guide for Stable Diffusion XL Setup
1. Setup Python and Pip
Begin by confirming the installation of Python, as Python is the backbone of this project then, install or update Pip, the essential package manager for Python, to ensure all dependencies for Stable Diffusion XL can be managed effectively.
python3 -m pip install --user --upgrade pip
This command ensures you have the latest version of Pip installed.
2. Creating a Virtual Environment
Create a Python virtual environment. This isolated environment is crucial for managing the Stable Diffusion XL project’s dependencies without affecting other Python projects. Now create and activate a virtual environment with:
python3 -m venv .venv
source .venv/bin/activate
3. Creating a Hugging Face Account
To access pre-trained models, including Stable Diffusion XL, sign up for a Hugging Face account. This platform hosts various machine learning models and offers community and professional support.
4. Installing Required Packages
Install Diffusers and Gradio using Pip. Diffusers is a Hugging Face library offering pre-trained diffusion models for various tasks. Gradio is an open-source library for creating user-friendly web interfaces for machine learning models.
pip install diffusers gradio torch transformers accelerate
5. Initial Code Setup
Write the following code in a file named main.py. This script sets up a basic Gradio interface to interact with the Stable Diffusion XL model. In this, we are using Stable Diffusion XL Base model stabilityai/stable-diffusion-xl-base-1.0 which is provided by Stability AI. The source code is available at Stability Official Github page. To use the model we are using StableDiffusionXLPipeline from diffusers for text-to-image generation.
import gradio as gr
from diffusers import StableDiffusionXLPipeline
import torch
# Load the model with specified parameters
base = StableDiffusionXLPipeline.from_pretrained(
stabilityai/stable-diffusion-xl-base-1.0, torch_dtype=torch.float16, variant=fp16, use_safetensors=True,
)
base.to(cuda)
def query(payload):
# Generate image based on the text prompt
image = base(prompt=payload).images[0]
return image
# Setup Gradio interface
demo = gr.Interface(fn=query, inputs=text, outputs=image)
if __name__ == __main__:
demo.launch(show_api=False)
To run this script, use:
python3 main.py
This will provide you with a URL. When you open that URL, it will take you to the Gradio interface where you can input your prompts.
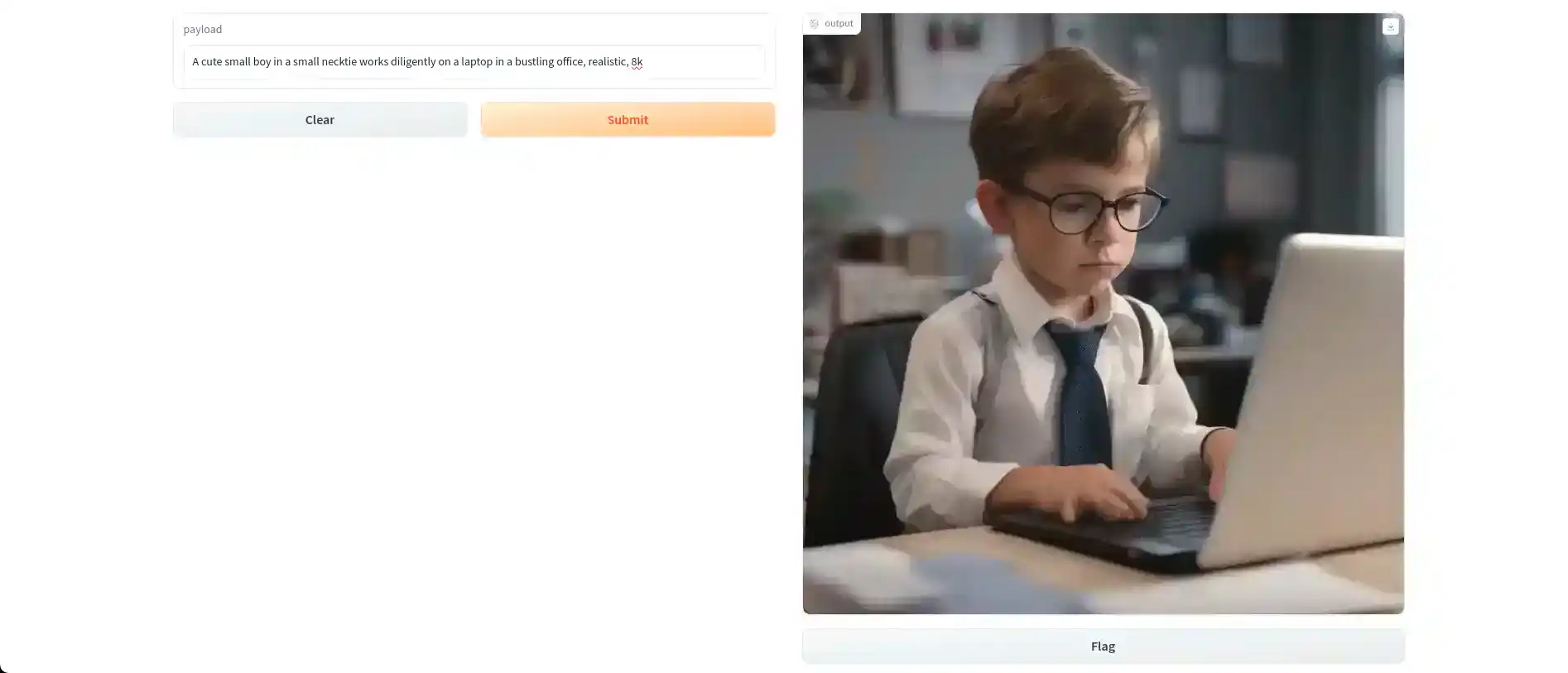
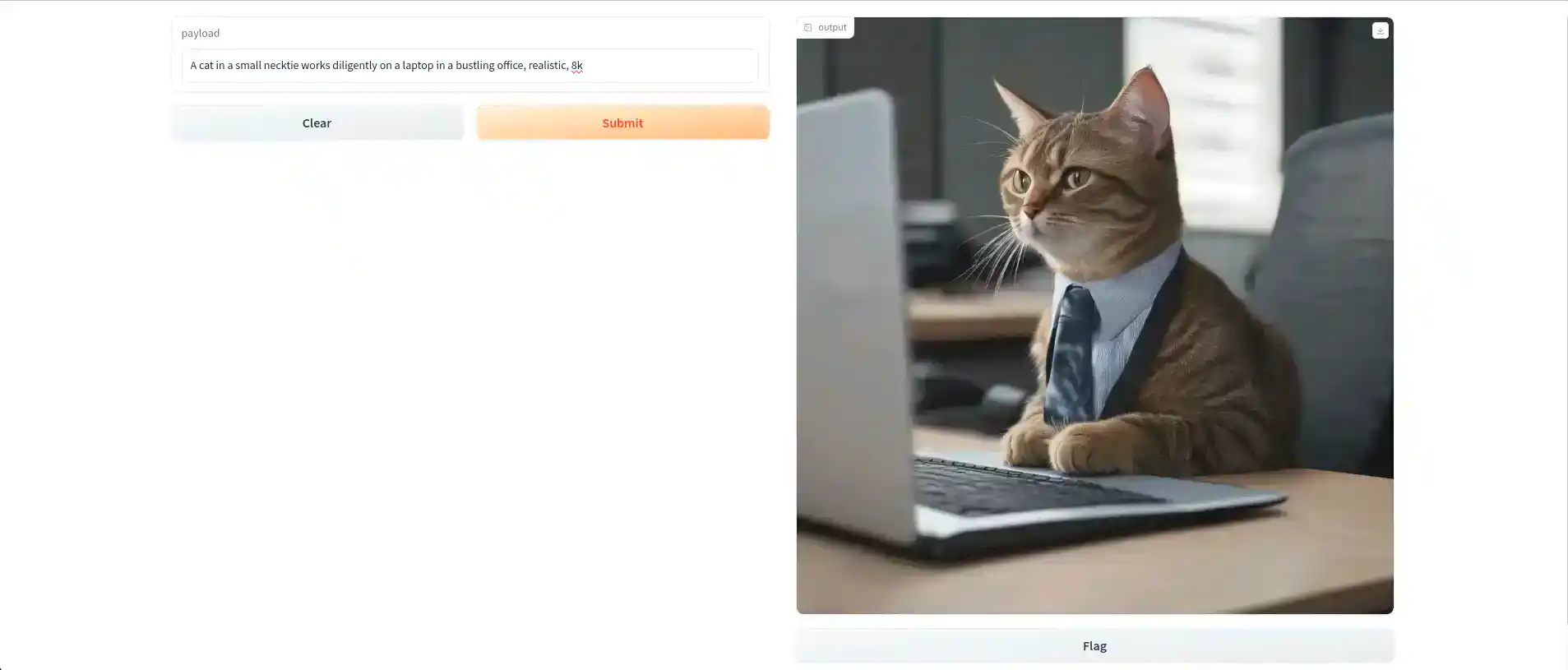
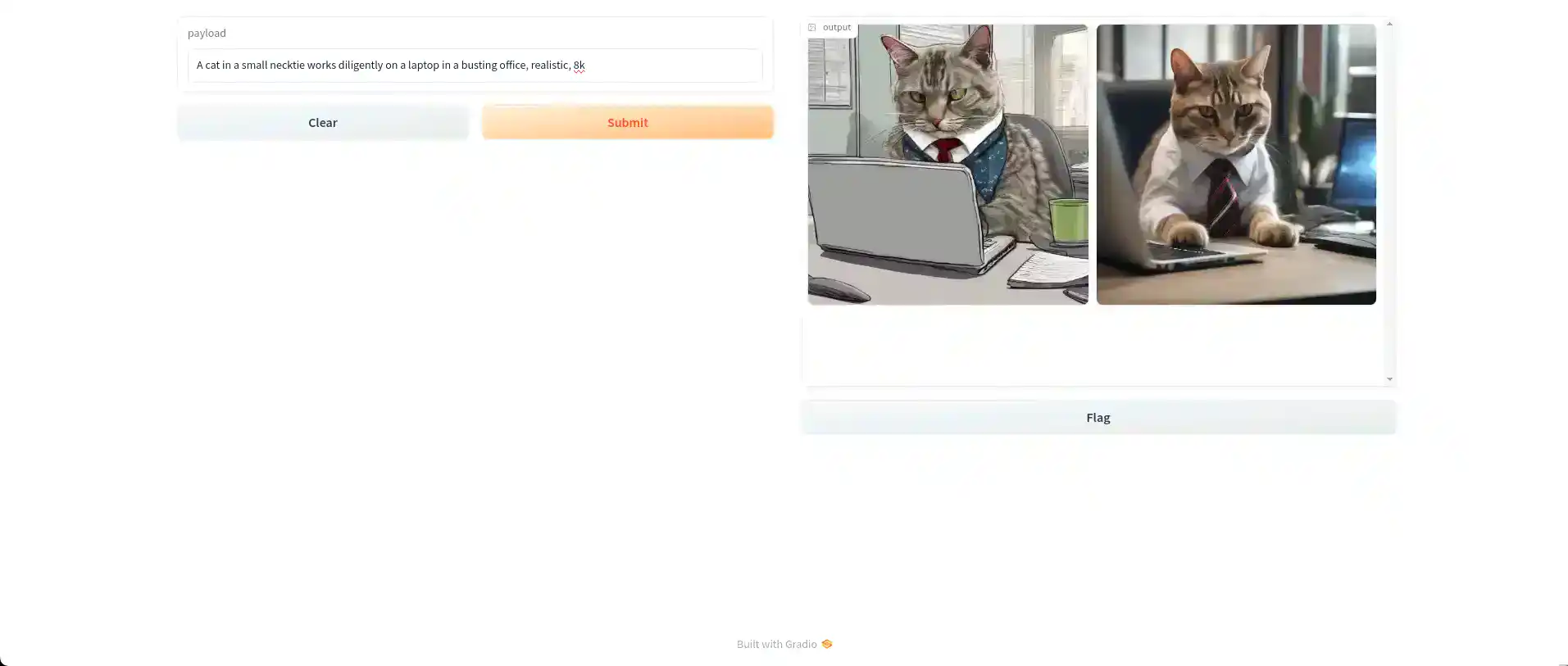
6. Generating Multiple Images
For generating multiple images by using Stable Diffusion XL, we need to modify the script as follows.
import gradio as gr
from diffusers import StableDiffusionXLPipeline
import torch
# Load the model
base = StableDiffusionXLPipeline.from_pretrained(
stabilityai/stable-diffusion-xl-base-1.0, torch_dtype=torch.float16, variant=fp16, use_safetensors=True,
)
base.to(cuda)
def query(payload):
# Generate multiple images based on the text prompt
image = base(prompt=payload, num_images_per_prompt=2).images
return image
# Setup Gradio interface for multiple images
demo = gr.Interface(fn=query, inputs=text, outputs=gallery)
if __name__ == __main__:
demo.launch(show_api=False)
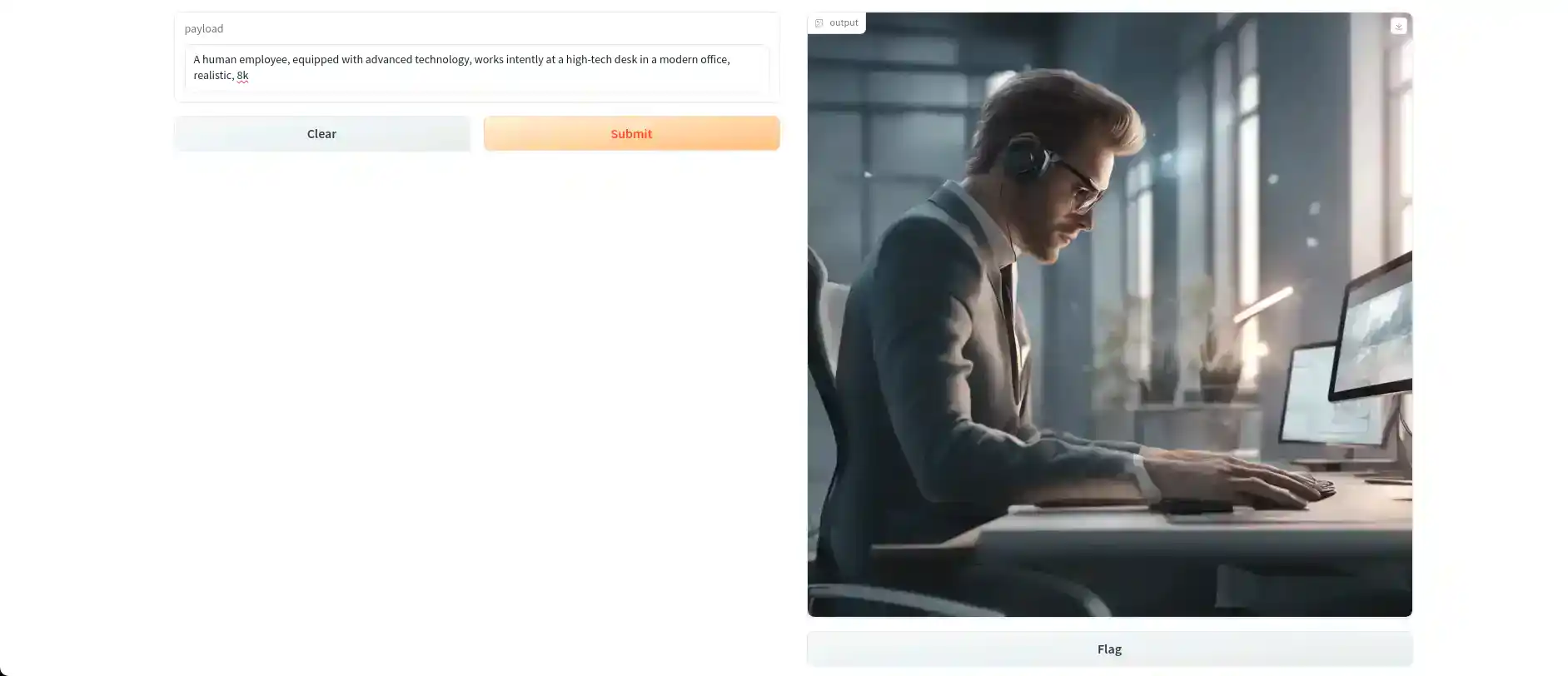
7. Using Base and Refiner Models
For generating refined images in Stable Diffusion XL, modify your script to include the base stabilityai/stable-diffusion-xl-base-1.0 and refiner stabilityai/stable-diffusion-xl-refiner-1.0 models. As we now using two models at a time we need to use DiffusionPipeline. which supports the bundling of multiple independently-trained models, schedulers, and processors into a single end-to-end class.
import gradio as gr
from diffusers import DiffusionPipeline
import torch
# Load base and refiner models with specified parameters
base = DiffusionPipeline.from_pretrained(
stabilityai/stable-diffusion-xl-base-1.0,
torch_dtype=torch.float16,
variant=fp16,
use_safetensors=True
)
base.to(cuda)
refiner = DiffusionPipeline.from_pretrained(
stabilityai/stable-diffusion-xl-refiner-1.0,
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant=fp16,
)
refiner.to(cuda)
# Define processing steps
n_steps = 40
high_noise_frac = 0.8
def query(payload):
# Generate and refine image based on the text prompt
image = base(prompt=payload,num_inference_steps=n_steps, denoising_end=high_noise_frac, output_type=latent).images
image = refiner(prompt=payload, num_inference_steps=n_steps, denoising_start=high_noise_frac, image=image).images[0]
return image
# Setup Gradio interface for refined images
demo = gr.Interface(fn=query, inputs=text, outputs=image)
if __name__ == __main__:
demo.launch(show_api=False)
Summary and Further Resources on YouTube
In summary, our journey through Stable Diffusion XL’s capabilities highlights the exciting potential of AI in image generation. For a more in-depth understanding, we encourage you to watch our tutorial on YouTube, where we cover each step comprehensively. Don’t forget to follow and subscribe to our channel for the latest insights in AI technology. Join us in exploring the forefront of AI innovations! 🚀 🎨