Table of Contents
Every business faces unexpected technical failures. A server crashes, an application stops responding, or a security vulnerability appears. These events, known as incidents, threaten business operations and customer trust. The coordinated process used to identify, respond to, and resolve these issues is incident management.
Incident management functions as a guardian against service failures. Its sole goal is to restore normal service operations as quickly as possible. When a major service fails, the speed of your incident response directly affects your company’s reputation and bottom line. An event that causes a disturbance in the workflow or reduces service quality demands immediate, structured action. This guide details how modern incident management software transforms operational chaos into coordinated success.
What is Incident Management?
Incident management is the set of processes used to contain and resolve unexpected service disruptions. An incident is any unplanned event that causes a disturbance in the workflow or reduces the service quality, such as a server failure or an outage.
The importance of effective incident management is clear from the financial risks involved. Downtime costs organizations an average of $5,600 per minute. Outside of financial protection, a company’s response during a crisis builds customer trust; 90% of customers judge a company’s overall trustworthiness by its crisis handling.
It is important to differentiate incident management from problem management. Incident management is reactive and focuses on speed to restore normal service. Problem management is proactive and focuses on the root causes to eliminate underlying issues permanently.
Why Use Incident Management?
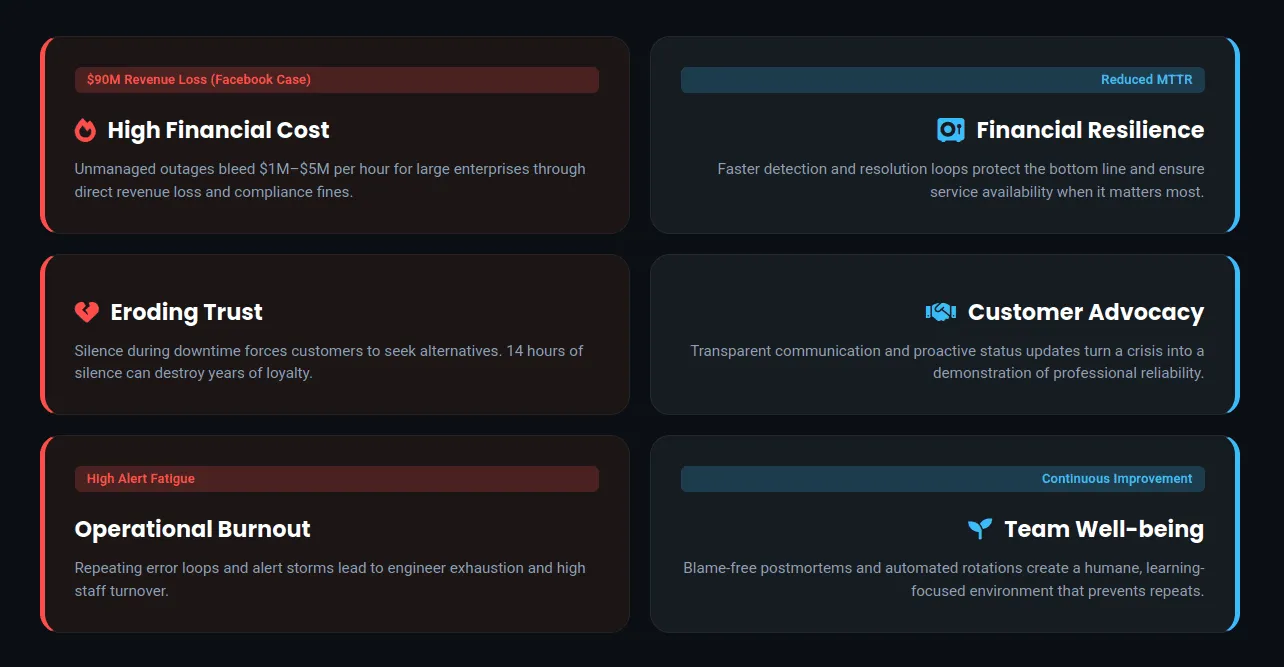
Organizations use incident management as a strategic necessity, not a luxury. It mitigates financial losses, protects reputation, and improves overall operational efficiency.
1. Mitigate High Financial Costs
Downtime is incredibly expensive. A single hour of outage for large enterprises can cost between $1 million and $5 million. Structured incident management reduces detection time and speeds up incident resolution, allowing organizations to resolve issues before they become major financial liabilities. For example, a 14-hour Facebook outage resulted in a $90 million loss. Proper incident management is the best defense against such losses.
2. Preserve Customer Trust
A company’s handling of an outage is a primary indicator of its reliability. Incident management ensures issues are handled swiftly and communication maintains transparency. Proactive status page updates reassure customers that operations teams are working hard to solve the issue, helping to build long-term trust.
3. Improve Operational Efficiency and Team Well-being
Modern IT environments overwhelm operations teams with thousands of alerts. Incident management helps streamline the chaos by filtering noise and reducing “alert fatigue,” preventing engineer burnout. By using automated alerting and clear on-call rotations, the process ensures a humane workload for team members.
4. Drive Continuous Improvement
Every incident offers a chance to learn. Incident management requires a formal root cause analysis (RCA) and postmortem. This process identifies where systems or processes failed, captures “lessons learned,” and implements preventive measures, ensuring the organization does not repeat the same mistake.
The Incident Management Process Lifecycle

The incident management process is a systematic framework designed to move quickly from chaos to recovery. The lifecycle typically follows these structured stages:
1. Preparation
This stage occurs before any disruption. Organizations establish response policies, define roles (like the Incident Response Team), and set up automated monitoring tools for detection.
2. Detection and Logging
The incident management system detects an issue either through automated monitoring tools or a user report to the service desk. The system records the incident with details like time of occurrence, symptoms, and affected systems.
3. Categorization and Prioritization
Incidents are grouped by type (e.g., hardware or security) and assigned a severity level. The system must prioritize issues based on the potential business impact and the urgency needed to restore normal service. This step determines if an incident is a major incident requiring immediate attention.
4. Investigation and Diagnosis
Responders analyze the incident to diagnose its true cause. They develop a plan to resolve the incident.
5. Containment and Resolution
Teams take immediate action to mitigate the spread of the disruption (containment). Then, they implement a fix to restore normal service operations. The goal is to resolve incidents quickly.
6. Post-Incident Activity
Once the incident is resolved, teams conduct a formal root cause analysis to identify the root causes and update processes to prevent recurrence. This results in an incident report that guides future actions.
Types of Incident Management

Organizations tailor their approach to incident management based on the severity and nature of the failure.
Processes Categorized by Impact and Severity
- Desktop Sprint: For low-impact incidents affecting a single user, such as a service request for a password reset. These follow a high-speed resolution model.
- Big Bang: Reserved for a major incident that causes a large-scale outage, like a network failure. This requires high urgency and intensive collaboration between all operations teams.
- CyberSec (Showstoppers): Handles critical security threats like ransomware or data breaches. The focus is on forensic investigation and containment to minimize data loss.
Framework-Specific Processes
- ITIL Incident Management: A reactive process focused solely on restoring normal service as quickly as possible. This approach is distinct from problem management, which aims to find and resolve the root causes.
- NIST SP 800-61 Process: A four-stage approach, Preparation, Detection and Analysis, Containment and Eradication, and Post-Incident Activity, that offers a detailed roadmap for incident response.
What is Incident Management Software? (IMS)
Incident management software is a specialized IT tool that serves as a centralized hub to automate the entire incident management lifecycle. It transforms system failures into coordinated actions by connecting systems and operations teams across the organization.
The incident management system manages incidents from detection to final documentation, ensuring issues are addressed systematically to restore normal service operations as fast as possible. This is a core component of modern ITSM (IT Service Management).
How Does an Incident Management System Work?

An incident management system operates on a structured management workflow to manage the full incident resolution lifecycle.
1. Detection and Logging
The system detects an anomaly via integrations with monitoring tools or a manual user report. It logs essential details, including time, severity, and affected systems. The system uses AI to correlate thousands of alerts into a single actionable incident, preventing “alert fatigue.”
2. Categorization and Prioritization
The software automatically categorizes the incident and assigns prioritization. This is determined by weighing the impact (who is affected) against the urgency (how quickly the service must restore normal to prevent loss). This helps prioritize the work.
3. Alerting and Escalation
The system identifies the correct team members based on their skills and on-call schedule. It uses multi-channel notifications (SMS, phone, chat) for real-time alerts. If the responder does not acknowledge the alert, the software automatically triggers escalation policies to notify senior staff. The ability to escalate quickly saves valuable time during a major outage.
4. Collaboration and Investigation
During incident resolution, the software streamlines teamwork through ChatOps integration. It can instantly create dedicated chat “war rooms” (in Slack or Teams), inviting necessary experts and logging the conversation timelines automatically. This helps teams diagnose the problem quickly.
5. Resolution and Post-Incident Activity
Once the team implements a fix, the incident is resolved. The incident management system manages the final stages:
- Automated Remediation: Simple fixes, like restarting a service, can be done without human input.
- Root Cause Analysis: The software helps draft root cause analysis documents and the final incident report, guiding teams to prevent recurrence.
- Stakeholder Communication: Status pages update automatically, and templated notifications are sent to maintain transparency.
Key Features to Look For in Incident Management Software
When selecting an incident management system, several key features are essential for effective incident management:
- Real-Time Alerting: Provides immediate, multi-channel notifications with context about the affected systems and business operations impact.
- On-Call Management: Includes flexible scheduling, automated rotations, and clear escalation policies to ensure the right team members are available.
- ChatOps Integration: Allows for incident resolution directly within collaboration tools, streamlineing the management workflow.
- AI and Machine Learning: Helps to automate noise reduction, summarize incident payloads, and suggest resolution steps based on historical patterns.
- Reporting and Analytics: Tracks metrics like Mean Time to Repair (MTTR) to help teams improve response times and identify systemic issues.
- Knowledge Base Integration: Links to past incident reports and solutions, allowing responders to resolve incidents faster.
The Role of Incident Management for DevOps
In the DevOps environment, incident management has shifted from a manual, siloed process to a highly automated, collaborative framework. DevOps teams focus on speed, AIOps, and continuous feedback loops.
The incident management system for DevOps integrates directly into the development workflow:
- Noise Reduction: AI-driven correlation filters out non-actionable alerts, helping DevOps operations teams focus on signals that impact users.
- Blameless Culture: The emphasis is on the “blameless” postmortem to identify system or process failures, not individual mistakes. This is critical for collecting honest information needed for a good root cause analysis.
- Toolchain Integration: The system syncs with CI/CD tools, monitoring tools, and observability platforms to diagnose the issue with deep technical context, helping to resolve problems faster.
Incident Management vs. Service Request
While both are managed within ITSM or service management platforms, an incident is an unplanned disruption, while a service request is a routine request for assistance.
| Aspect | Incident Management | Service Request |
| Nature | Unplanned disruption or loss of service quality. | Formal request for something to be provided. |
| Goal | Speed to restore normal service operations. | Fulfilling the user’s specific request. |
| Examples | Server failure, application outage. | Password resets, requesting access to a system. |
A robust incident management system helps route items correctly. What starts as a simple service request to the service desk can become an incident if it stems from an underlying failure.
Incident Management vs. Problem Management
Incident management and problem management are distinct parts of service management. They function like cause and effect.
Incident management focuses on short-term fixes to restore normal operations quickly. It is reactive. Problem management is proactive. It focuses on finding the root causes of one or more incidents and implementing a permanent fix. For example, the outage is the incident; the poor code that caused the outage is the problem.
ITIL Incident Management stresses the immediate restoration of service, while problem management focuses on structured root cause analysis to prevent the issue from recurring.
Best Practices for Incident Management

Effective incident management requires a set of standards to ensure a coordinated incident response.
1. Standardize and Prepare
- Follow Established Frameworks: Use guidelines like NIST or ITIL incident management to ensure a consistent roadmap.
- Define Major Incidents: Set clear criteria for when an outage is a major incident based on its impact on business operations.
- Regular Drills: Test your incident management process with mock scenarios to ensure team members are prepared.
2. Optimize Detection and Triage
- Centralize Logging: Use a single incident management system for all tickets to maintain a complete view.
- Use a Prioritization Matrix: Prioritize by weighing impact against urgency to resolve the most critical issues first.
- Filter Noise: Use AI to correlate thousands of alerts, allowing your operations teams to focus on signals that require incident response.
3. Improve Communication and Transparency
- Adopt ChatOps: Manage the management workflow directly in chat platforms for real-time collaboration.
- Proactive Updates: Use automated status pages and notifications to provide transparency to customers and executives.
- Automated Escalation: Configure clear escalation paths to notify senior personnel if response times fall outside agreed-upon limits.
4. Drive Continuous Improvement
- Conduct Root Cause Analysis: Use systematic tools like the “5 Whys” to identify underlying root causes.
- Accountability and Follow-up: Track corrective actions with clear ownership to ensure permanent fixes are implemented.
- Build a Knowledge Base: Document all resolutions and lessons learned to speed up future incident resolution and reduce the time needed to resolve incidents.
Benefits of Using an Incident Management System (IMS)
Adopting an incident management system provides multiple benefits that streamline operations and protect the business.
- Faster Response Times: Automated workflows and real-time alerts cut the time to resolve an issue, significantly reducing downtime costs.
- Improved Collaboration: The IMS acts as a central hub, connecting team members and providing transparency across the organization.
- Accountability and Compliance: The system maintains audit-ready records and timestamped logs, which are essential for meeting regulatory requirements like HIPAA or GDPR, while ensuring accountability for every step.
- Continuous Improvement: By facilitating root cause analysis, the IMS turns every disruption into an opportunity to implement preventive measures.
Next Steps for Your Incident Management Strategy
Implementing a strong incident management approach moves an organization beyond reactive incident response to proactive reliability.
- Audit Your Processes: Check if your current incident management process relies on manual spreadsheets or fragmented chat channels, which creates unclear ownership.
- Define Requirements: Determine your specific needs, such as depth of integration with existing DevOps tools (Jira, Slack, AWS), or requirements for ITSM compliance.
- Test Software Solutions: Try top incident management tools with real-time traffic to see how they fit your culture and help resolve incidents before committing to a long-term purchase.
By investing in an incident management system today, your organization ensures it is prepared to handle any disruption and restore normal operations with speed and precision.