Table of Contents
Bigger isn’t always better, especially in enterprise AI.
While the AI industry spent 2023 and 2024 in an arms race to build larger and more powerful language models, a quiet revolution has been taking shape in enterprise boardrooms.
Companies are discovering that the path to AI ROI doesn’t necessarily run through billion-parameter behemoths requiring data center-scale infrastructure.
Instead, they’re turning to Small Language Models (SLMs), compact, specialized AI systems that deliver targeted performance at a fraction of the cost.
This shift represents more than just a technical pivot.
It’s a fundamental rethinking of how enterprises deploy AI at scale, balancing capability with practicality, and innovation with governance.
As we move through 2026, the enterprises that master SLM strategy won’t just save money; they’ll gain a decisive competitive advantage in speed, security, and specialization.
The Shift from LLMs to SLMs
The Explosion of Large Language Models
The release of GPT-3 in 2020 ignited an AI revolution that fundamentally changed how we think about machine intelligence.
By 2024, we will have witnessed an unprecedented proliferation of Large Language Models, each pushing the boundaries of scale and capability.
Models with hundreds of billions of parameters became commonplace, demonstrating remarkable abilities in reasoning, creativity, and general knowledge.
This explosion created genuine excitement and genuine challenges.
Enterprise Challenges: Cost, Latency, Privacy, Control
Despite their impressive capabilities, LLMs introduced significant friction in enterprise environments:
Cost barriers: Running inference on large models can cost thousands of dollars per day, even for modest usage. Training or fine-tuning these models requires budgets that only the largest enterprises can afford.
Latency issues: When milliseconds matter, as they do in customer service, trading systems, or manufacturing automation, the computational overhead of LLMs creates unacceptable delays.
Privacy concerns: Sending proprietary data to third-party LLM providers raises red flags for legal, compliance, and competitive intelligence teams. Many industries cannot risk exposing external data.
Limited control: Dependence on external providers leads to vendor lock-in, unpredictable pricing changes, and limited customization to specific business needs.
Emergence of Small Language Models
Enter Small Language Models: purpose-built AI systems typically ranging from hundreds of millions to a few billion parameters, designed to excel at specific domains rather than attempting universal knowledge.
These models represent a pragmatic evolution in enterprise AI strategy.
SLMs aren’t simply “LLMs lite.” They’re architected, trained, and deployed differently, optimized for real-world enterprise constraints rather than benchmark leaderboards.
Thesis: Why SLM Strategy Will Define the Future of Enterprise AI
The thesis is straightforward: enterprises that develop sophisticated SLM strategies will operationalize AI faster, cheaper, and more securely than competitors relying solely on large models.
They’ll deploy AI where it matters most, embedded in business processes, running at the edge, protecting sensitive data, while maintaining the flexibility to leverage LLMs when truly needed.
This isn’t about choosing sides in an LLM vs SLM debate.
It’s about recognizing that different enterprise needs demand different AI architectures, and that strategic deployment of smaller models unlocks AI value at scale.
What is an SLM (Small Language Model)?
A Small Language Model is a neural network-based language system typically containing between 100 million and 10 billion parameters, designed to perform specific language understanding or generation tasks efficiently.
Unlike their larger counterparts that aim for broad general intelligence, SLMs are optimized for targeted performance within defined domains or task categories.
What Qualifies as an SLM
The boundaries aren’t rigid, but several characteristics typically define an SLM:
Parameter count: Generally between 100M to 10B parameters (compared to 100B+ for LLMs)
Specialized training: Focused on specific domains, tasks, or knowledge areas rather than attempting universal competence
Deployment footprint: Designed to run on enterprise-grade servers, edge devices, or even high-end mobile hardware
Inference efficiency: Optimized for fast response times and lower computational overhead
Parameter Size Comparison
To contextualize scale:
- Tiny models: 100M-500M parameters (edge devices, mobile applications)
- Small models: 500M-3B parameters (on-premise servers, specialized tasks)
- Medium models: 3B-10B parameters (enterprise servers, complex domain tasks)
- Large models: 10B-100B+ parameters (cloud infrastructure, general intelligence)
For reference, GPT-4 is estimated to have over 1 trillion parameters, while effective enterprise SLMs like Microsoft’s Phi-3 operate at 3.8 billion parameters with remarkable task-specific performance.
Key Characteristics
Smaller size: Reduced model footprint enables deployment flexibility and faster iteration cycles.
Domain specialization: Deep expertise in specific areas, legal document analysis, medical coding, and financial compliance, rather than shallow knowledge across everything.
Lower compute requirements: Can run on commodity hardware, reducing infrastructure costs dramatically.
Faster inference: Response times are measured in milliseconds rather than seconds, enabling real-time applications.
Examples of SLMs
Distilled models: Models like DistilBERT or smaller versions of Llama, created by compressing knowledge from larger models while retaining task-specific performance.
Edge-optimized models: Purpose-built for deployment on devices with limited compute, such as factory floor equipment or point-of-sale systems.
Domain-specific enterprise models: Custom models trained on proprietary datasets for narrow applications, a legal contract analyzer, a medical diagnostic assistant, or a customer service specialist for a specific product line.
Why Enterprises Are Moving Toward SLM Strategy
Cost Efficiency
The economics are compelling and impossible to ignore.
Lower training cost: Training an SLM from scratch or fine-tuning an existing one costs thousands to tens of thousands of dollars, not millions. This democratizes AI development, allowing mid-sized enterprises to build custom models.
Lower inference cost: Running inference on an SLM can be 10-100x cheaper than equivalent LLM queries. For an enterprise processing millions of requests daily, this translates to hundreds of thousands or millions in annual savings.
Reduced infrastructure requirements: SLMs run efficiently on standard enterprise servers or even CPU-based infrastructure, eliminating the need for expensive GPU clusters for many use cases.
A real-world example: A financial services firm reduced its AI operations costs by 70% by replacing a general-purpose LLM with domain-specific SLMs for fraud detection and customer service routing, while maintaining equivalent accuracy.
Performance for Specific Tasks
Counterintuitively, smaller can mean better when properly focused.
Better performance in narrow domains: An SLM trained exclusively on medical literature and clinical notes will typically outperform a general LLM on healthcare tasks, despite having far fewer parameters. The focused training creates deeper, more reliable domain expertise.
Reduced hallucinations in specialized contexts: Because SLMs work within bounded knowledge domains, they’re less likely to generate plausible-sounding but incorrect information. When an SLM doesn’t know something, it’s more likely to acknowledge uncertainty rather than fabricate an answer.
Benchmark studies in 2025 consistently showed that well-tuned 3B parameter domain-specific models outperformed 70B+ parameter general models on specialized enterprise tasks, with hallucination rates 60-80% lower.
Data Privacy and Security
For regulated industries, this may be the most critical factor.
Easier to deploy on-premise: SLMs can run entirely within enterprise data centers, ensuring sensitive information never leaves the organization’s control. This is non-negotiable for healthcare providers handling patient data, financial institutions managing trading information, and government agencies handling classified materials.
Better compliance with regulations: GDPR, HIPAA, SOC 2, and industry-specific regulations become dramatically simpler to navigate when data processing happens locally rather than through third-party API calls.
One European bank reported that its on-premise SLM deployment reduced compliance review time from six months to three weeks, specifically because data governance could be proven through infrastructure control rather than contractual guarantees.
Speed and Latency Advantages
In many enterprise contexts, speed isn’t just convenience; it’s a requirement.
Faster responses: SLMs typically generate responses in 50-500 milliseconds, compared to 1-5 seconds for large models. This difference is transformative for user experience.
Real-time applications: Manufacturing quality control systems analyzing images on production lines, trading systems making split-second decisions, or customer service systems routing calls, all require response times that only SLMs can reliably deliver.
Edge and On-Device Deployment
The future of enterprise AI isn’t just in the cloud; it’s everywhere.
Supports edge AI: SLMs enable AI capabilities in retail stores, hospital emergency rooms, manufacturing facilities, and field service locations without requiring constant cloud connectivity.
Enables offline AI use cases: Critical applications can continue functioning even when network connections fail. A diagnostic tool in a rural clinic, an inspection system in a remote mining operation, or a translation device in an aircraft all benefit from local AI execution.
This edge capability is driving explosive growth.
Analysts project that by 2027, over 60% of enterprise AI inference will happen outside centralized data centers, with SLMs powering this distributed intelligence.
SLM vs LLM: Enterprise Comparison
Understanding the tradeoffs helps enterprises make strategic deployment decisions:
| Factor | SLM | LLM |
|---|---|---|
| Cost | Low ($0.001-0.01 per 1K tokens) | High ($0.01-0.10+ per 1K tokens) |
| Latency | Fast (50-500ms) | Slower (1-5+ seconds) |
| Customization | Easy (fine-tune in days/weeks) | Complex (expensive, time-consuming) |
| Privacy | High (on-premise capable) | Moderate (depends on provider) |
| Infrastructure | Lightweight (CPUs often sufficient) | Heavyweight (requires GPUs) |
| General Knowledge | Moderate (domain-focused) | Very High (broad capabilities) |
| Hallucination Risk | Lower (in domain) | Higher (broader uncertainty) |
| Edge Deployment | Excellent | Poor to Impossible |
| Training Data Needs | Focused datasets (10K-1M examples) | Massive datasets (billions of tokens) |
| Model Updates | Rapid iteration possible | Slow, expensive updates |
The pattern is clear: SLMs excel at focused, high-volume, latency-sensitive, privacy-critical applications.
LLMs excel at complex reasoning, broad knowledge tasks, and situations where generalization matters more than specialization.
Core Components of an Enterprise SLM Strategy
Building an effective SLM strategy requires systematic thinking across five key dimensions.
Use Case Identification
Success starts with ruthless prioritization.
Task-specific AI: Identify discrete, well-defined tasks where AI can deliver measurable value. Examples include document classification, information extraction, basic question answering, content generation for standardized formats, and anomaly detection.
High-ROI opportunities: Focus on use cases with clear business metrics, reduced customer service handle time, faster contract review, improved quality control accuracy, or automated report generation. The narrower and more measurable the use case, the better suited it is for an SLM.
Avoid the trap of trying to solve everything at once. The most successful enterprise SLM deployments start with 2-3 high-value use cases, prove ROI, then expand systematically.
Domain Data Strategy
SLMs are only as good as the data they learn from.
Curated datasets: Quality trumps quantity. A carefully curated dataset of 50,000 domain-specific examples often outperforms a generic dataset of 5 million examples. This means investing in data labeling, cleaning, and validation.
Proprietary enterprise knowledge: The real competitive advantage comes from training on data competitors don’t have, your support tickets, your product documentation, your process guidelines, and your successful sales conversations. This proprietary training data creates defensible AI capabilities.
One manufacturing company built an SLM trained on 20 years of equipment maintenance logs, creating an AI system that could predict failures with 85% accuracy, something no off-the-shelf model could match because no one else had that data.
Model Selection or Development
Enterprises have three primary paths:
Fine-tuning existing models: Start with open-source base models (Llama, Mistral, Phi) and fine-tune on domain data. This is often the fastest path to value, requiring weeks rather than months.
Distillation from LLMs: Use a large model as a “teacher” to create labeled datasets, then train a smaller “student” model to replicate specific capabilities. This captures some of the LLM’s reasoning while delivering SLM efficiency.
Training custom SLMs: For truly unique domains or stringent requirements, training from scratch provides maximum control. This is the most resource-intensive option but can deliver the best results for specialized needs.
The choice depends on data availability, timeline, budget, and how closely existing models align with your use case.
Deployment Architecture
Where and how you run your models matters as much as the models themselves.
Cloud deployment: Leverage cloud GPU instances for centralized inference, with auto-scaling for variable demand. Best for applications with unpredictable load or when managing infrastructure isn’t core to your business.
On-premise deployment: Run models within your data center for maximum control, security, and compliance. Critical for regulated industries, and when data cannot leave your network.
Edge deployment: Deploy models to local devices, stores, factories, or field equipment. Essential for offline capability, low-latency requirements, or distributed operations.
Leading enterprises increasingly adopt a hybrid approach, edge SLMs for real-time processing, on-premise SLMs for sensitive operations, and strategic cloud LLM usage for complex reasoning tasks.
Governance and Security
AI governance can’t be an afterthought.
Model monitoring: Continuously track performance metrics, drift detection, and usage patterns. An SLM that starts hallucinating or degrading in accuracy needs immediate attention.
Compliance: Document training data sources, model behavior, decision logic, and maintain audit trails. Regulations are evolving rapidly, and compliance frameworks need to be built in from the start.
Risk management: Implement safeguards against adversarial inputs, establish human-in-the-loop protocols for high-stakes decisions, and create rollback procedures when models underperform.
SLM Architecture in Enterprise AI Stack
Understanding how SLMs fit into the broader enterprise AI infrastructure is crucial for successful implementation.
The Five-Layer Architecture
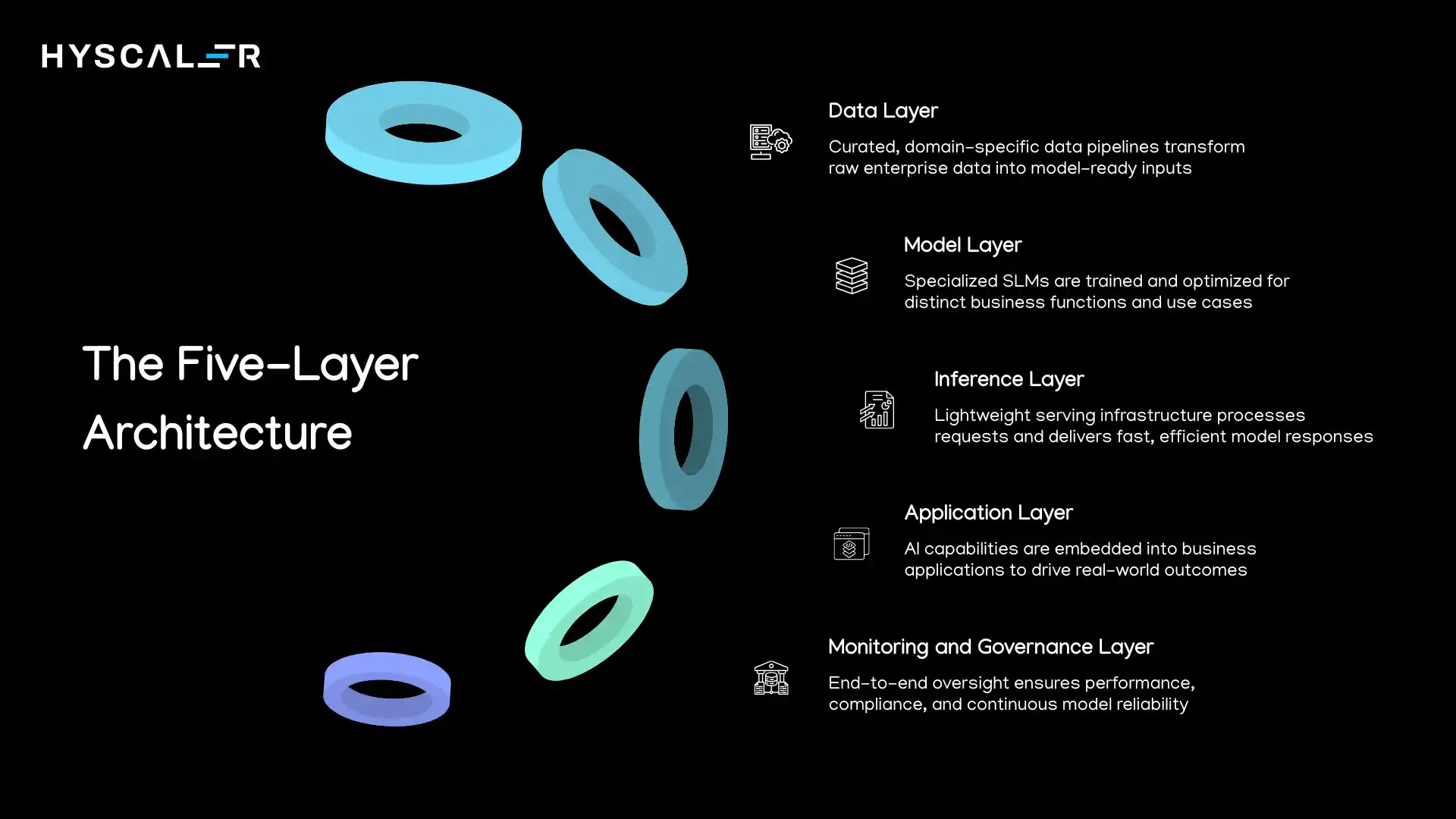
Data Layer:
This foundation includes data warehouses, lakes, and real-time streams feeding the AI system.
For SLMs, this layer emphasizes curated, domain-specific datasets rather than massive general corpora.
Key components include data pipelines, preprocessing systems, and feature stores that transform raw enterprise data into model-ready formats.
Model Layer:
This is where the SLMs themselves live, the trained neural networks with their parameters, architectures, and configurations.
In a mature enterprise deployment, this layer contains multiple SLMs serving different functions: a customer service model, a document analysis model, and a coding assistant model, each optimized for its specific domain.
Inference Layer:
The runtime environment where models process requests and generate responses.
This includes serving infrastructure (APIs, load balancers), caching systems for common queries, and orchestration logic that routes requests to appropriate models.
For SLMs, this layer is dramatically simpler than LLM equivalents, often running on standard application servers rather than specialized GPU infrastructure.
Application Layer:
Where AI capabilities surface to end users through applications, integrations, and workflows.
This includes chatbots, document processing systems, analytics dashboards, and API integrations with existing enterprise software.
The application layer translates model outputs into business value.
Monitoring and Governance Layer:
The oversight system spans all other layers, tracking performance, ensuring compliance, detecting drift, and managing model lifecycle.
This includes logging systems, performance dashboards, alert mechanisms, and audit trails.
How SLM Fits Into Modern AI Architecture
The key insight is that SLMs don’t replace the existing AI stack; they make it more efficient and distributed.
A modern enterprise AI architecture might look like:
- Edge locations: Small SLMs handling real-time, latency-sensitive tasks locally
- On-premise servers: Medium SLMs processing sensitive data within corporate networks
- Cloud infrastructure: Orchestration layer managing model routing, with occasional LLM calls for complex reasoning
- Central governance: Unified monitoring and management across all deployment locations
This distributed architecture enables enterprises to optimize for cost, latency, privacy, and capability simultaneously, something impossible with a purely centralized LLM approach.
Real-World Enterprise Use Cases
Theory meets practice.
Here’s where SLMs are delivering measurable business value today.
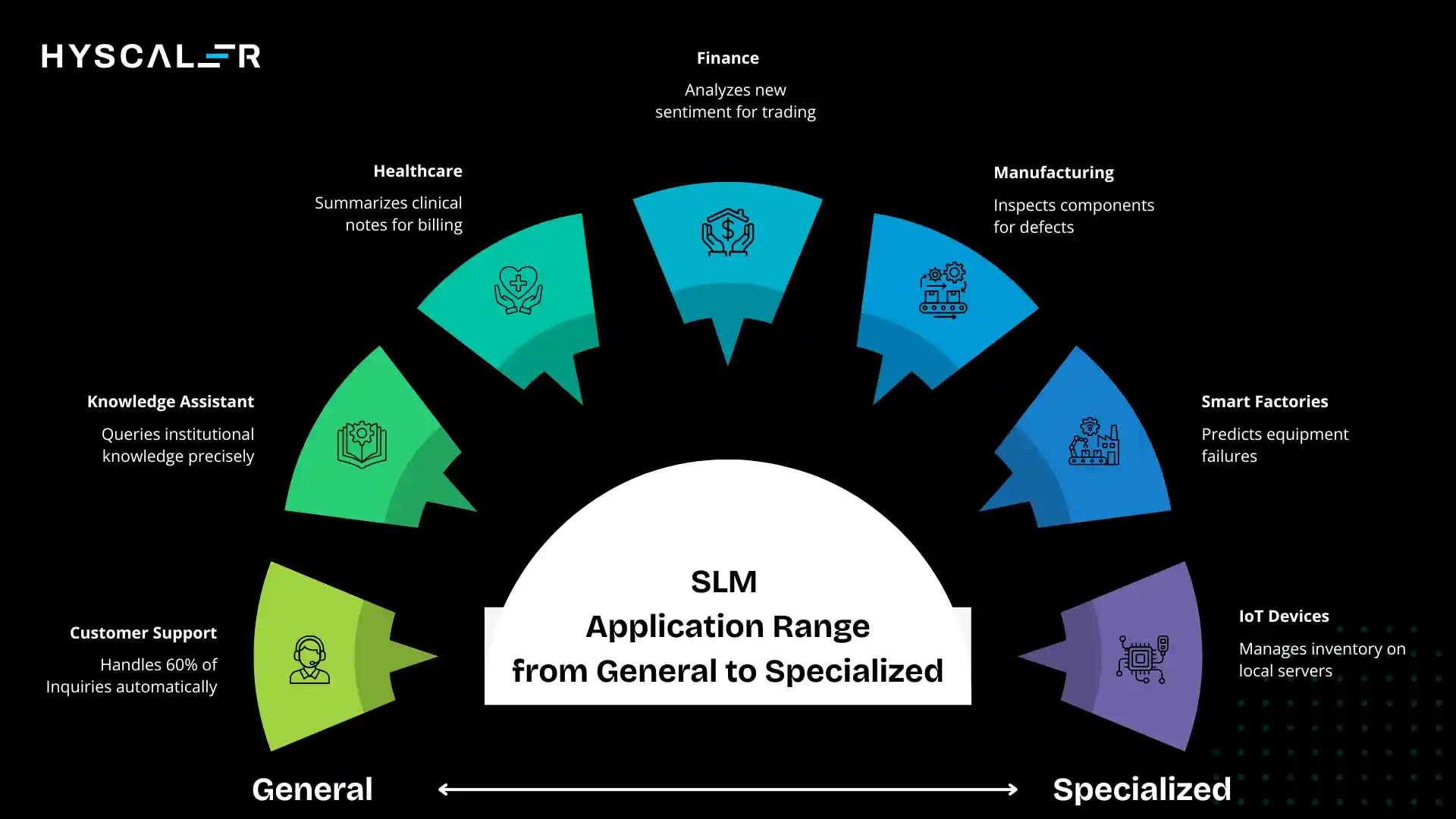
Customer Support Automation
Internal chatbots: An insurance company deployed an SLM trained on its policy documents and historical customer interactions. The model handles 60% of tier-1 support inquiries automatically, with 92% customer satisfaction. Average resolution time dropped from 8 minutes to 45 seconds. The SLM runs on their existing application servers at a cost of $200/month versus the $8,000/month they were spending on an LLM-based solution.
The key success factor: narrow scope. The SLM doesn’t try to answer every possible question; it knows insurance policies for this specific company and gracefully hands off to humans when queries fall outside its expertise.
Enterprise Knowledge Assistants
Internal document search: A pharmaceutical company built an SLM trained on their research papers, clinical trial data, and regulatory submissions. Scientists can now query decades of institutional knowledge in natural language, getting precise answers with source citations. The system processes 50,000 queries monthly, with 85% of users reporting that it saves them at least 2 hours per week.
The privacy advantage proved critical; all data remains on-premise, satisfying regulatory requirements that would have blocked any cloud-based solution.
Industry-Specific AI
Healthcare:
A hospital network deployed SLMs for clinical note summarization, extracting key information from lengthy physician narratives for billing and coding purposes.
Accuracy matches human coders at 94%, processing 10x faster.
The system handles 50,000 notes daily, saving an estimated $2.3M annually in coding labor while improving submission speed.
Finance:
A trading firm uses SLMs for real-time news sentiment analysis, processing thousands of articles and social media posts per minute.
The ultra-low latency (under 100ms) enables split-second trading decisions that wouldn’t be possible with larger models.
Manufacturing:
An automotive manufacturer deployed edge SLMs for visual quality inspection on assembly lines.
The models run on industrial PCs at each station, inspecting 500+ components per minute with 99.2% defect detection accuracy.
Because processing happens locally, the system operates reliably even during network outages.
Edge AI Applications
Smart factories: Factory floor equipment running SLMs for predictive maintenance, analyzing vibration patterns, temperature fluctuations, and performance metrics in real-time. One facility reduced unplanned downtime by 40% through early failure detection.
IoT devices: Retail stores using SLMs on local servers for inventory management, analyzing shelf images to detect out-of-stock conditions and pricing errors. The system processes camera feeds from 200+ stores, operating continuously without sending video data to the cloud, a crucial privacy consideration.
SLM + LLM: The Hybrid AI Strategy
This represents the cutting edge of enterprise AI architecture in 2026, and the highest-ROI approach.
The Strategic Framework
The most sophisticated enterprises aren’t choosing between SLMs and LLMs.
They’re orchestrating both, leveraging each model type for its strengths.
When to Use SLM
Deploy SLMs for:
- High-volume, repetitive tasks where consistency and speed matter more than creativity
- Well-defined domains with clear boundaries and available training data
- Latency-critical applications requiring sub-second response times
- Privacy-sensitive processing where data cannot leave your infrastructure
- Cost-sensitive operations with thin margins or massive scale
- Edge deployments without reliable connectivity
When to Use LLM
Reserve LLMs for:
- Complex reasoning tasks requiring multi-step logic or deep analysis
- Novel situations outside the scope of any specialized model
- Creative generation where originality and variety are paramount
- Broad knowledge synthesis drawing on diverse domains
- Ambiguous queries that need interpretation and clarification
- Low-frequency, high-stakes decisions where the cost per query is less critical
Orchestration Strategy
The magic happens in intelligent routing.
A well-designed orchestration layer:
- Classifies incoming requests by complexity, domain, and requirements
- Routes to appropriate models based on classification
- Implements fallback logic when SLMs exceed confidence thresholds or encounter unfamiliar territory
- Aggregates results from multiple models when needed
- Learns from patterns to improve routing over time
Cost Optimization Approach: SLM-First, LLM-Fallback
This architecture delivers 70-90% cost reduction while maintaining capability:
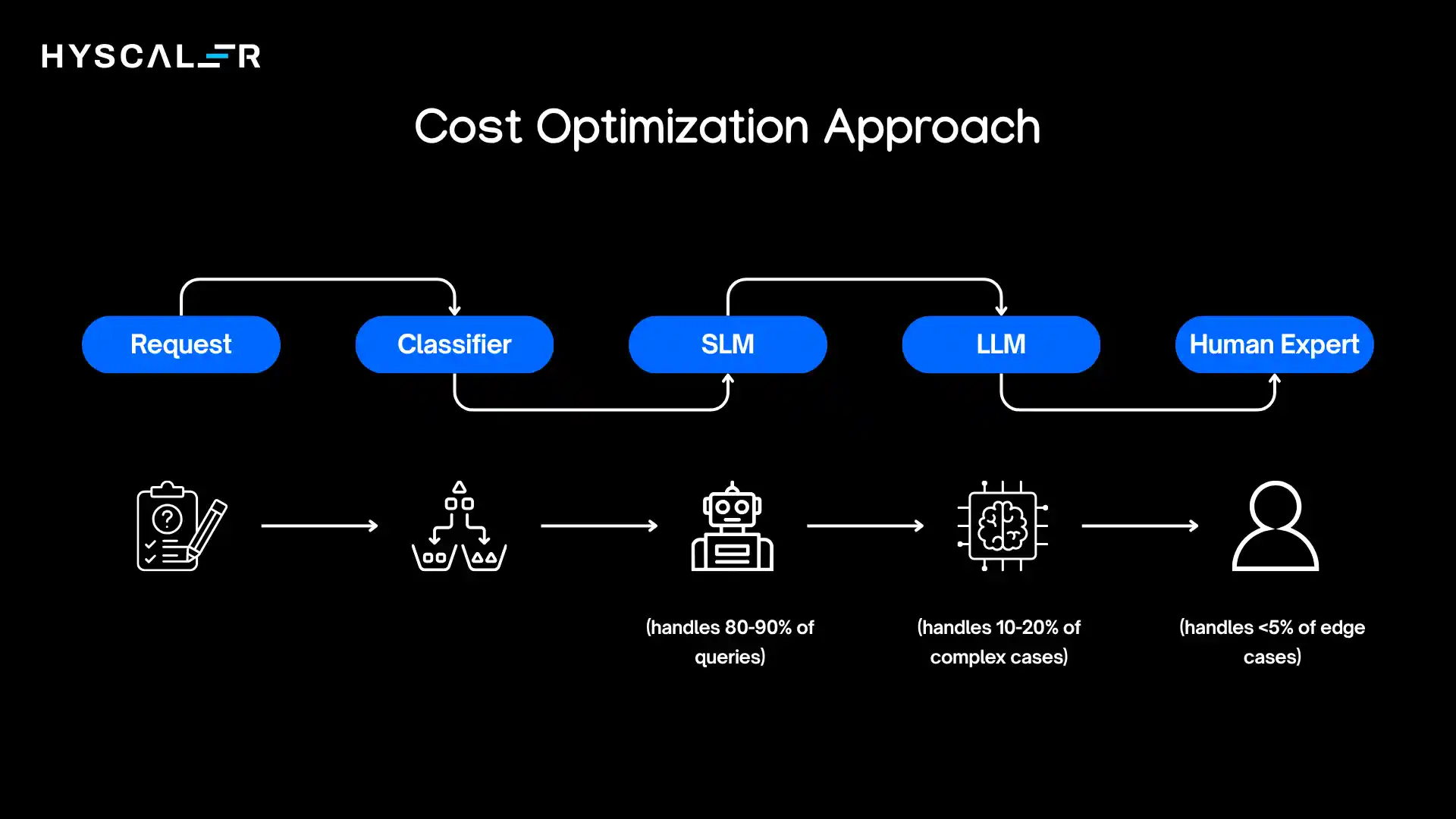
A financial services company implemented this exact architecture for its customer service. Results after six months:
- 87% of queries handled by SLM ($0.002 per query)
- 11% escalated to LLM ($0.08 per query)
- 2% routed to humans ($6.00 per query)
- Overall cost per query: $0.015 (versus $0.08 previously with LLM-only)
- 82% cost reduction with no decrease in quality metrics
The key insight: most customer service queries are variations on common themes.
An SLM trained on historical interactions handles these efficiently.
Only genuinely novel or complex situations require the LLM’s broader capabilities.
Benefits of SLM Strategy for Enterprises
Let’s consolidate the value proposition with concrete impact metrics.
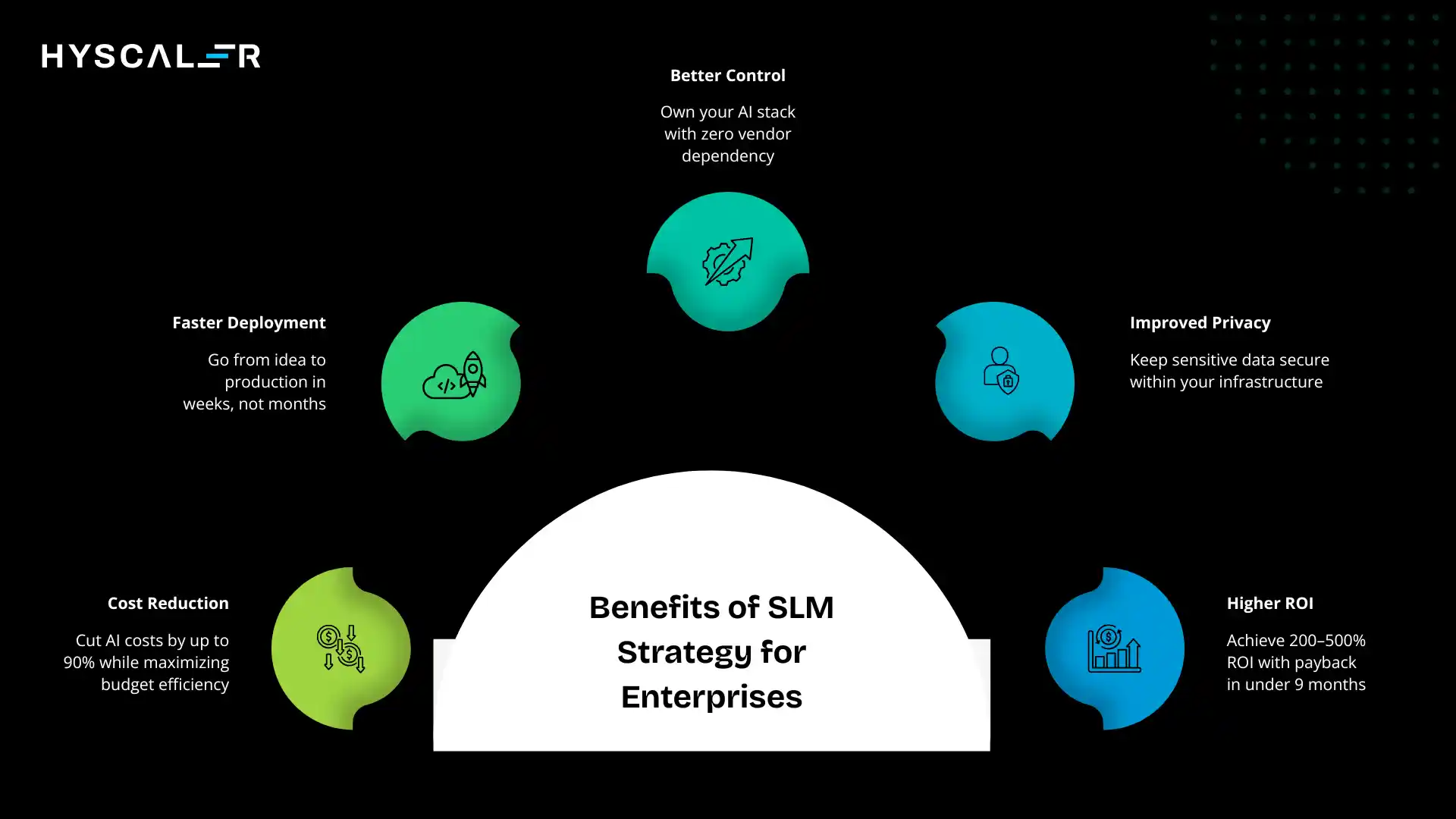
Cost Reduction
Beyond the obvious inference savings, consider the total cost of ownership:
- 60-90% reduction in AI infrastructure costs
- 70-85% reduction in AI operations costs
- 50-75% reduction in energy consumption
- Lower licensing costs (many excellent SLM bases are open-source)
One enterprise reported that shifting 75% of their AI workload from LLMs to SLMs reduced their annual AI budget from $4.2M to $1.1M, a $3.1M savings that funded expansion into five new AI use cases.
Faster Deployment
SLMs compress AI project timelines dramatically:
- Days to fine-tune versus months for LLM customization
- Weeks for end-to-end deployment versus quarters
- Rapid iteration cycles enable faster experimentation and learning
This speed advantage compounds.
While competitors are still negotiating enterprise LLM contracts and customization processes, SLM-first organizations are already in market, gathering usage data, and iterating toward product-market fit.
Better Control
Full ownership of the AI stack eliminates dependencies:
- No vendor lock-in or pricing surprises
- Complete model customization and behavior control
- Rapid response to new requirements or market changes
- Independence from external service reliability
Improved Privacy
In regulated industries, this isn’t just a benefit, it’s a business enabler:
- Data never leaves corporate infrastructure
- Simplified compliance and audit processes
- Reduced regulatory risk
- Customer confidence in data handling
One healthcare provider noted that their SLM deployment cleared privacy review in three weeks versus nine months for their previous cloud LLM evaluation, accelerating time-to-market by over six months.
Higher ROI
When you combine lower costs, faster deployment, and better fit to specific use cases, ROI metrics are compelling:
- Typical payback period: 3-9 months
- Annual ROI: 200-500% for well-executed implementations
- Faster path to scaling across multiple use cases
Challenges and Limitations of SLMs
Honesty about limitations is crucial for setting realistic expectations and designing around constraints.

Limited General Intelligence
SLMs excel in their domains but struggle outside them.
A customer service SLM trained on your product catalog won’t suddenly be able to write poetry or explain quantum physics.
This is by design, but it means:
- You need a clear scope definition for each SLM
- Edge cases outside training domains require fallback strategies
- Multiple SLMs may be needed for diverse use cases
Requires Domain Data
You can’t build effective SLMs without quality training data. This means:
- Significant upfront investment in data curation
- Potential delays if the domain data is scarce or scattered
- Ongoing data maintenance as domains evolve
- Potential cold-start problems for entirely new use cases
Enterprises without robust data practices will struggle to realize SLM benefits.
Data strategy must precede or accompany SLM strategy.
Needs Careful Optimization
SLMs don’t automatically work well out of the box.
Success requires:
- Thoughtful architecture selection
- Careful hyperparameter tuning
- Iterative evaluation and refinement
- Domain expertise to validate model behavior
This isn’t plug-and-play.
It requires skilled ML engineering and domain experts working together.
May Require Orchestration with LLMs
For comprehensive AI capabilities, you’ll likely need both SLMs and LLMs, which introduces:
- Architectural complexity in routing and coordination
- Multiple systems to monitor and maintain
- Potential inconsistencies in behavior across models
- More sophisticated MLOps requirements
The hybrid approach delivers better results but demands more sophisticated implementation.
How to Build an Enterprise SLM Strategy (Step-by-Step Roadmap)
A practical guide to moving from concept to production, the essence of SLM strategy.
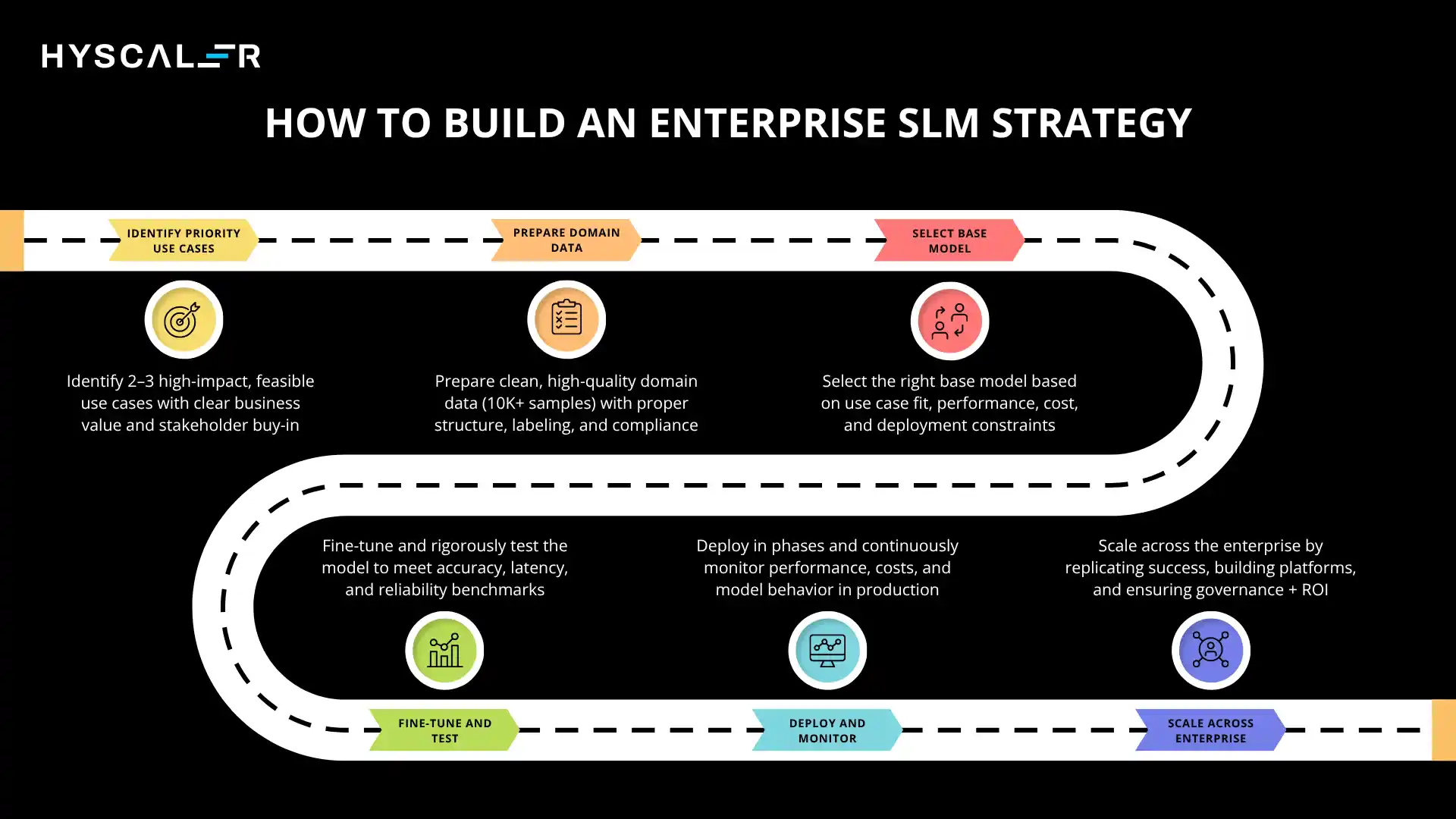
Step 1: Identify Priority Use Cases
Begin with discovery and prioritization:
Assessment criteria:
- Clear business value with measurable metrics
- Well-defined scope and boundaries
- Available or obtainable training data
- Stakeholder buy-in and executive support
- Reasonable complexity for initial success
Activities:
- Interview business stakeholders across departments
- Map existing AI-suitable workflows
- Assess data availability for each potential use case
- Create a prioritization matrix balancing impact and feasibility
- Select 2-3 initial use cases for pilot programs
Duration: 2-4 weeks
Success metric: Clear consensus on 2-3 high-value, achievable initial use cases with executive sponsorship
Step 2: Prepare Domain Data
Data preparation often takes longer than model training itself.
Activities:
- Inventory existing relevant datasets
- Assess data quality, completeness, and representativeness
- Design a data labeling strategy if supervised learning is needed
- Implement data cleaning and preprocessing pipelines
- Create training/validation/test splits
- Document data provenance for compliance
- Establish data refresh processes for ongoing maintenance
Common challenges:
- Data scattered across systems
- Inconsistent formats and quality
- Insufficient volume for specific scenarios
- Privacy concerns requiring anonymization
- Historical data not representative of current needs
Duration: 4-12 weeks (varies enormously based on data maturity)
Success metric: Curated, cleaned dataset of 10,000+ examples (minimum) with documented quality and compliance
Step 3: Select Base Model
Choose your starting point based on use case requirements.
Options:
- Open-source foundation models: Llama 3, Mistral, Phi-3, Gemma (free, flexible, community support)
- Commercial small models: Domain-specific pre-trained models from vendors (faster time-to-value, support, but cost and dependencies)
- Distillation approach: Create your own SLM by distilling knowledge from a larger model
Selection criteria:
- Model size fits deployment constraints
- Architecture appropriate for task type (classification, generation, etc.)
- Licensing compatible with your use case
- Available documentation and tooling
- Community or vendor support
Activities:
- Benchmark candidate models on sample data
- Evaluate deployment requirements
- Assess customization flexibility
- Review licensing and commercial terms
Duration: 1-2 weeks
Success metric: Selected base model with documented rationale and benchmark results
Step 4: Fine-Tune and Test
Transform the base model into your domain-specific solution.
Fine-tuning process:
- Configure training hyperparameters
- Implement training pipeline
- Monitor training metrics (loss, accuracy, etc.)
- Iterate on training data and parameters
- Evaluate on the held-out test set
- Compare performance to baseline and requirements
Testing dimensions:
- Accuracy on domain tasks
- Latency and throughput
- Resource consumption
- Edge case handling
- Hallucination rates
- Consistency across similar queries
Activities:
- Set up training infrastructure (cloud or on-prem)
- Implement experiment tracking
- Run multiple training experiments with different configurations
- Evaluate systematically against success metrics
- Conduct a human evaluation for qualitative assessment
- Test deployment pipeline
Duration: 2-6 weeks
Success metric: Model meeting defined accuracy, latency, and reliability targets with documented evaluation results
Step 5: Deploy and Monitor
Move from development to production with appropriate safeguards.
Deployment phases:
- Alpha: Internal testing with a small user group
- Beta: Controlled rollout to a subset of users
- General availability: Full production deployment
Monitoring systems:
- Performance metrics (latency, throughput, error rates)
- Accuracy metrics (precision, recall, F1 scores)
- Business metrics (cost per query, user satisfaction)
- Drift detection (distribution shifts in inputs or outputs)
- Resource utilization (compute, memory, cost)
Activities:
- Implement serving infrastructure
- Set up monitoring dashboards and alerts
- Create rollback procedures
- Document operational runbooks
- Train support teams
- Establish feedback collection mechanisms
Duration: 2-4 weeks for initial deployment, ongoing for monitoring
Success metric: Stable production deployment with <0.1% error rate and monitoring coverage for key metrics
Step 6: Scale Across Enterprise
Expand from initial success to enterprise-wide impact.
Scaling strategies:
- Replicate successful use cases in other departments
- Expand model capabilities within existing domains
- Build platform infrastructure for rapid SLM deployment
- Establish centers of excellence for AI capabilities
- Create reusable components and patterns
Organizational enablers:
- Executive communication of successes and ROI
- Training programs for teams across the enterprise
- Governance frameworks for responsible scaling
- Investment in shared infrastructure and tooling
Common pitfalls to avoid:
- Scaling before proving value in initial use cases
- Underinvesting in change management and training
- Creating siloed implementations without knowledge sharing
- Neglecting governance as scale increases
Duration: 6-18 months for enterprise-wide transformation
Success metric: 10+ production SLM deployments with documented ROI and established operational excellence
Future of Enterprise AI: Why SLMs Will Dominate
SLMs will power the next phase of enterprise AI, driven by edge computing, privacy needs, cost pressure, and specialized use cases.
SLM Strategy Key trends:
- Edge AI growth: Most data will be processed outside data centers, requiring lightweight SLMs
- Private AI adoption: On-prem models ensure compliance, security, and control
- Cost optimization: SLMs offer predictable, lower-cost scaling vs. LLMs
- AI agents: Specialized SLM-powered agents will automate workflows at scale
- Hybrid systems: SLMs handle routine tasks, LLMs handle complex reasoning
What to expect:
- By 2026: Widespread SLM adoption and major cost reductions
- By 2028: ~80% of enterprise AI runs on SLM or hybrid setups
Bottom line: SLMs won’t just reduce costs, they’ll enable scalable, specialized AI that creates lasting competitive advantage.
SLM Strategy and Agentic AI
The convergence of SLMs and agentic AI represents one of the most exciting developments in enterprise technology.
What is Agentic AI?
Agentic AI refers to autonomous software systems that can perceive their environment, make decisions, and take actions to achieve goals with minimal human intervention.
Unlike traditional AI that responds to queries, agents proactively execute tasks, learn from outcomes, and adapt behavior.
Think of agents as AI-powered employees: a scheduling agent that manages meeting logistics, a research agent that monitors markets and surfaces insights, or a compliance agent that reviews documents for regulatory issues.
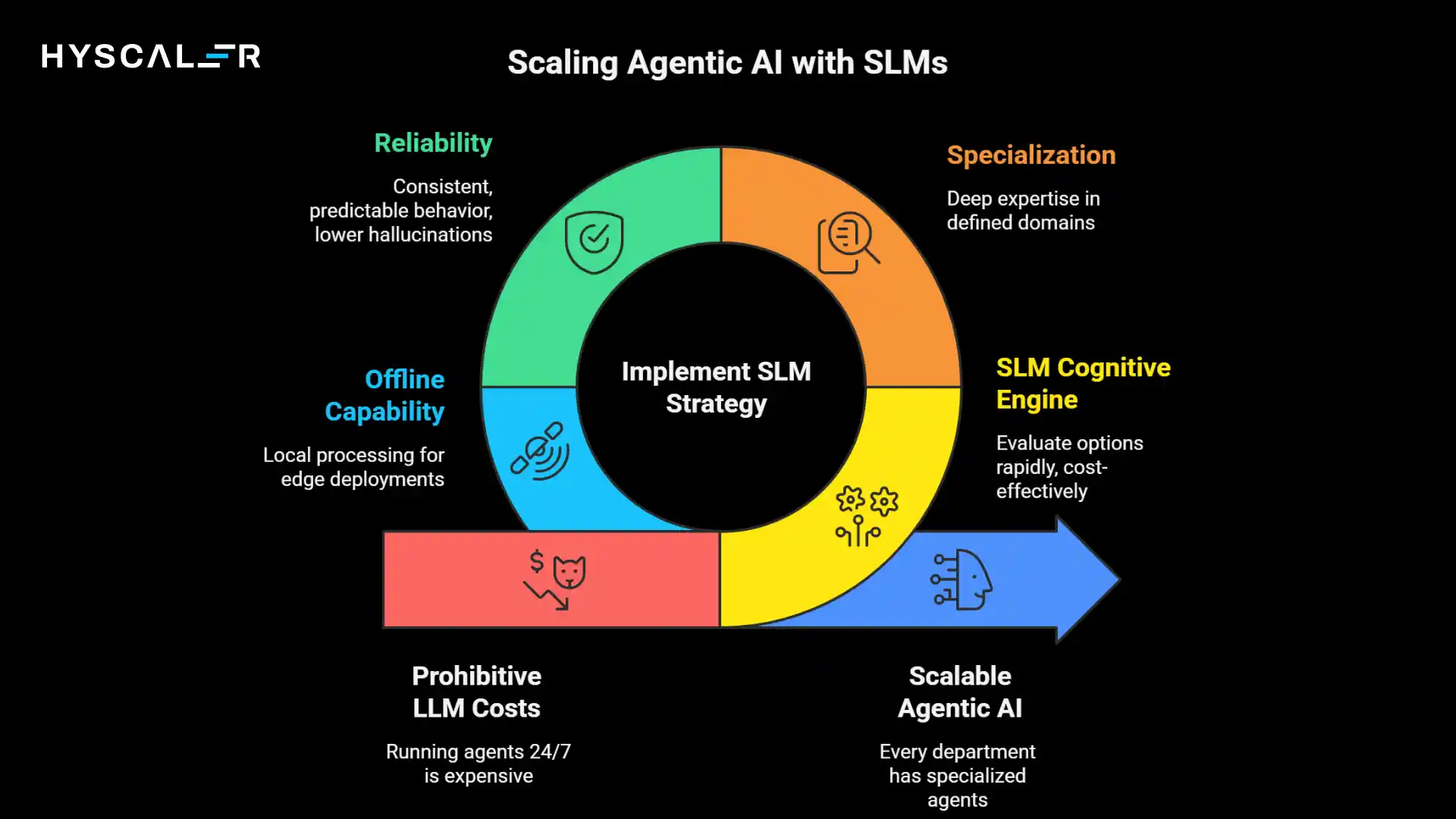
SLM as the Brain of AI Agents
SLMs are becoming the preferred cognitive engine for enterprise agents for several reasons:
Speed: Agents often need to make many small decisions rapidly. An SLM can evaluate options in milliseconds, enabling fluid, responsive agent behavior.
Cost: Running an agent 24/7 with LLM calls becomes prohibitively expensive. SLM-powered agents cost 10-100x less to operate continuously.
Specialization: Agents work within defined domains, exactly where SLMs excel. A procurement agent doesn’t need general world knowledge; they need deep expertise in sourcing, pricing, and vendor management.
Reliability: Agents need consistent, predictable behavior. SLMs’ lower hallucination rates within their domains make them more trustworthy for autonomous operation.
Offline capability: Agents deployed at edge locations or in systems with intermittent connectivity need local processing, which is impossible with cloud LLMs, but natural with SLMs.
Lower Cost Enables Scaling Agents
Here’s where economics transform possibilities.
At LLM pricing, running 100 agents 24/7 might cost $500,000 annually.
At SLM pricing, the same workload costs $50,000, maybe less.
This 10x cost reduction changes what’s feasible:
- Every department can have specialized agents
- Agents can work on lower-value tasks still worth automating
- Experimentation becomes affordable
- Failed agents don’t represent catastrophic waste
One manufacturing company deployed 47 specialized SLM-powered agents across their operations, quality inspectors, inventory monitors, predictive maintenance specialists, and supply chain optimizers.
Total cost: $180,000 annually.
Estimated value: $3.2M in efficiency gains and defect prevention.
Real-Time Enterprise Automation
The combination of SLM speed and agent autonomy enables new automation patterns:
Continuous monitoring agents: Watching dashboards, logs, and metrics 24/7, alerting humans only when intervention is needed
Workflow orchestration agents: Managing complex multi-step processes, coordinating between systems, and handling exceptions
Customer interaction agents: Handling routine inquiries, qualifying leads, and routing complex issues appropriately
Research and analysis agents: Continuously gathering intelligence, synthesizing insights, and updating knowledge bases
Compliance and governance agents: Monitoring activities, flagging risks, and ensuring policy adherence
The Multi-Agent Enterprise
The future enterprise is an ecosystem of humans and agents working together:
- Human workers focus on complex judgment, creativity, strategy, and relationship building
- SLM-powered agents handle routine tasks, monitoring, data processing, and structured workflows
- Orchestration systems coordinate between agents and route work appropriately
- Escalation mechanisms bring humans in when agents encounter uncertainty or high-stakes decisions
This isn’t science fiction; leading enterprises are building these systems today.
The technology exists.
The business case is proven.
The competitive advantage is real.
Conclusion: SLM Strategy as a Competitive Advantage
LLMs proved what AI can do; SLMs make it practical, affordable, fast, and secure for real-world deployment.
Winning enterprises use a hybrid approach: SLMs for high-volume, domain tasks and LLMs for complex reasoning, cutting costs while improving performance.
Success isn’t about bigger models, but smarter strategy:
- Match the right model to the task
- Deploy securely (on-prem/edge)
- Scale efficiently
- Iterate quickly
SLMs turn AI from experimentation into business value, with clear ROI, lower risk, and better outcomes across teams.
There’s a current window of advantage.
Early adopters build data, models, and expertise that create lasting competitive moats.
Bottom line: SLMs aren’t a compromise; they’re how enterprises scale AI effectively, and having an SLM Strategy is a necessity.
FAQ
What’s the difference between SLM and LLM?
SLMs (100M–10B parameters) are faster, cheaper, and specialized for specific tasks, while LLMs (100B+ parameters) are more powerful and versatile but costly and resource-intensive.
Can SLMs replace LLMs entirely in enterprises?
SLMs can handle 70–90% of enterprise tasks, especially repetitive, domain-specific work. LLMs are better for complex reasoning and novel problems. Best approach: use SLMs for most tasks and LLMs for advanced needs.
How much does it cost to implement an SLM strategy?
Initial setup costs $50K–$500K, but ongoing costs are 60–90% lower than LLM-only setups. Most enterprises see ROI in 6–12 months, with pilot projects starting around $25K.
Do I need a data science team to implement SLMs?
SLMs require some ML expertise, but a small team (2–3 people) with domain knowledge can deploy them. Many start with consultants and build in-house skills over time, aided by accessible open-source tools.
What industries benefit most from the SLM strategy?
Industries with high-volume, specialized tasks benefit most – healthcare, finance, manufacturing, retail, and legal. SLMs excel in repetitive, domain-specific work and privacy-sensitive use cases.
How long does it take to deploy a production SLM?
Initial deployment takes 3-6 months, while later use cases take 1–3 months. Pilot projects can be launched in 4–8 weeks to validate value.
Can SLMs run on-premise, or do they need cloud infrastructure?
SLMs can run on-premise on standard servers, edge devices, or even laptops, ensuring data control and lower costs. Cloud use is optional, unlike LLMs.
How do SLMs handle data privacy and compliance?
SLMs enhance privacy by running entirely within your infrastructure, keeping data local. This simplifies compliance (GDPR, HIPAA) and ensures full control over data and model behavior.
What’s the accuracy difference between SLMs and LLMs?
In specialized domains, SLMs can match or outperform LLMs with fewer hallucinations. However, LLMs remain more versatile across diverse tasks.
How do I know if my use case is suitable for SLMs?
Good SLM use cases have a clear scope, domain data, high volume, cost/latency needs, and privacy requirements. Poor fits include creative, broad-knowledge, or one-off complex tasks.
Can I fine-tune open-source models for my specific needs?
Yes, fine-tuning SLMs (e.g., Llama, Mistral, Phi) is common and effective. With ~10K+ examples, you can build a specialized model in days or weeks, using open-source tools for flexibility and low cost.
What happens when an SLM encounters something outside its training?
SLMs should handle uncertainty by qualifying answers, saying “I don’t know,” or escalating to an LLM/human. This avoids hallucinations and is key to reliable deployment.
How do SLMs fit with existing AI investments in LLMs?
SLMs complement LLMs. Use SLMs for high-volume tasks and LLMs for complex needs, cutting costs by 60-80% while maintaining performance.
What’s the typical ROI timeline for SLM implementation?
Most enterprises achieve ROI in 6-12 months, or as fast as 3-4 months for high-volume use cases, with returns improving as they scale.
Do SLMs require constant retraining and maintenance?
SLMs require infrequent updates and can run for months or years. Most teams review performance quarterly or semi-annually, retraining only when needed, with minimal maintenance overhead.