LLM models are improving rapidly with lots of data. But they still have some drawbacks that act as a constraint.
The most effective AI systems can retrieve data in the right format and reason intelligently through it. But they are only fixated on the data they have been trained on the tools they are connected with APIs.
With this, two cutting-edge technologies have emerged that are reshaping how LLMs perform. Those are
- Retrieval Augmented Generation (RAG)
- Model Context Protocol (MCP)
And, RAG vs MCP is a growing topic now.
Lets understand how they are working together because both methods are created to overcome the limits of traditional LLMs.
So, let’s find out how.
What Is RAG?
RAG combines the power of language generation with real-time information retrieval.
Unlike others, RAG fetches data from external sources and feeds it into the model to generate more accurate and better results. So that you don’t have to worry about getting any relevant information.
Traditionally, GPT & BERT-based models are limited to the information that they are trained on.
But RAG overcomes this significantly.
With RAG pipelines, you can improve the overall relevancy and accuracy of LLM responses. With no more retraining, you will get live updated data anytime and anywhere.
Tools & Frameworks Used In RAG
Here’s the list of tools and frameworks used in RAG.
1. Vector Databases (Semantic retrieval)
Vector databases are a special type of database that is designed to store data in the form of vectors. To learn more about vectors, you can check this guide.
Vector databases can give you semantically searchable data.
Here are some examples
- FAISS – Facebook’s open-source vector search engine
- PineCone – Fully Managed, Scalable Vector DB
- Chroma – Really lightweight and completely developer-friendly
2. Framework And Orchestration
There are different types of frameworks, and let’s understand each of them.
- Langchain – It is a popular framework built for building LLM pipelines (retrieval chains)
- LlamaIndex – It is great for document ingestion and retrieval interfaces.
- Haystack – NLP-focused retrieval framework with UI support
3. LLMs (Generators)
Here is the list of LLMs that will be used.
- OpenAI GPT-4/GPT- 4o
- Anthropic Claude 3
- Google Gemini
Let’s Understand The RAG Pipeline
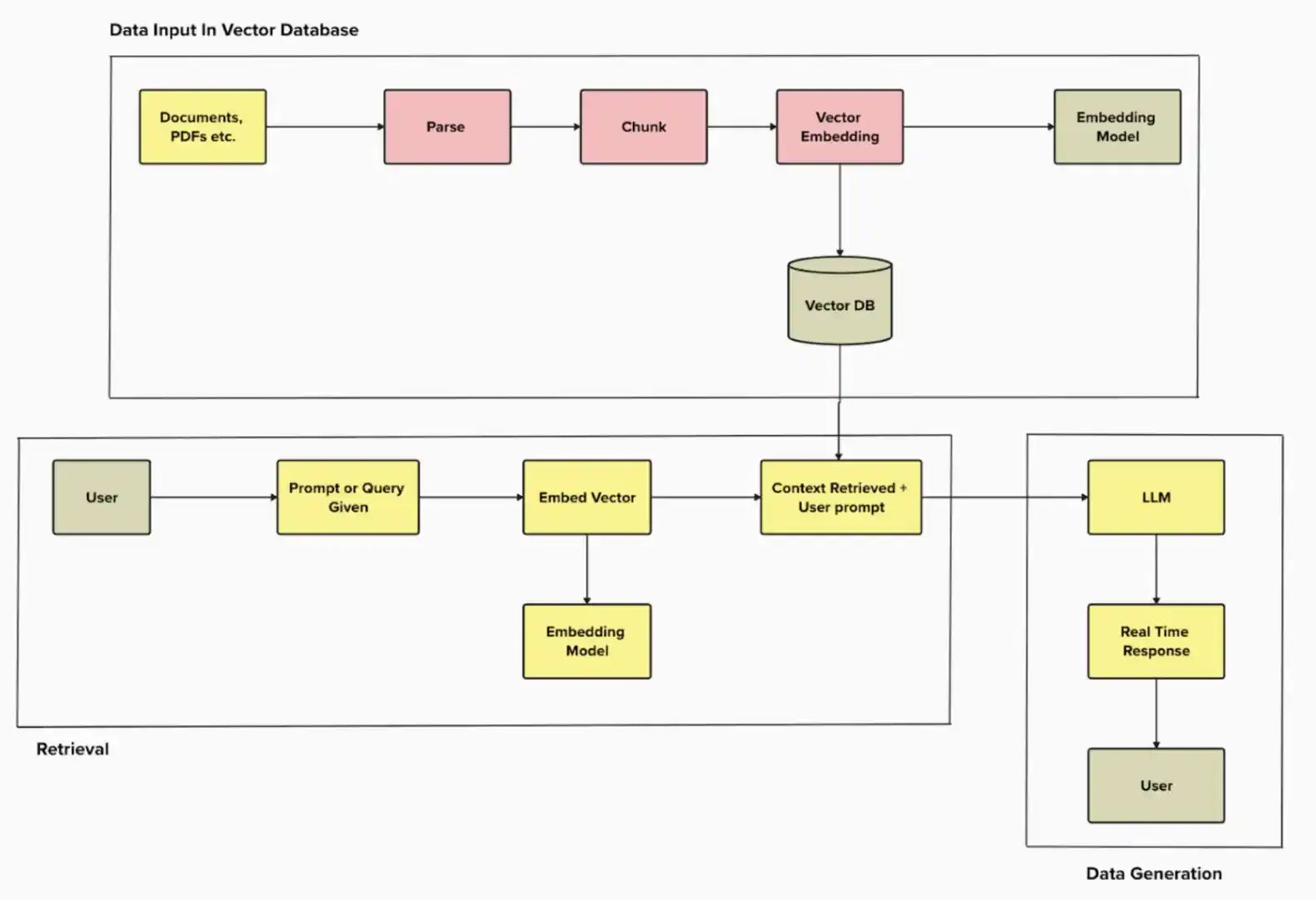
We will understand it in a 5-step process
1. Data Intake:
Imagine a new pile of information (any documents) came in, and you need to analyse it. These are the new raw materials that need to be processed and used.
2. Chunking The Data:
RAG takes the pile of data and breaks it into bite-sized pieces, and it segments them clearly so that whenever someone raises a query, depending on the query, it will send the right information. Making it highly precise.
3. Embedding:
This is when the real AI magic starts happening. With all the chunks of data present inside the RAG, it starts finding the right contextual answer based on the query given by the user.
4. Vector Storage:
Now, all your new information is going to be stored in the vector storage, and it can be used whenever a user asks for a query. For that you can use Pinecone or Chroma.
5. Retrieval
Now, the game starts once the user drops a question or query. RAG helps you find the exact answer based on the semantically correct information.
Then, you get your correct piece of information within just a few seconds.
Key Features & Benefits Of RAG
RAG brings you amazing benefits that can help you in multiple ways.
1. Dynamic Knowledge Access
RAG allows AI to access knowledge that was not part of its trained data, including real-time or domain-specific information.
2. Improved Factual Accuracy
As answers are primarily grounded in external sources, RAG reduces hallucination that often stops LLMs
3. Scalability
It easily integrates with enterprise databases, internal wikis, APIs, or document repositories to scale AI knowledge.
4. Reduced Retraining Costs
With RAG’s vector databases, it can search information in real time so that you can expand your knowledge base without retraining the old model itself. By simply updating the knowledge source, you will get the updated information in real time.
5. Fast Iterations
Got a new file? Put it in the RAG and re-embed it, then your RAG will instantly get updated with the new chunk of data. No need to wait weeks for retraining.
Limitations Of RAG
Even with multiple advantages, RAG has some limitations that we need to be aware of.
- RAG doesn’t auto-refresh content, and it needs timely updates of data.
- Retrieval often depends on vector similarity; it might fetch unrelated but semantically close documents.
- RAG doesn’t update the model or retriever based on user corrections unless manually updated or retrained.
What Is MCP?
Let’s understand MCP in a deeper way. As it is taking the market by storm because of the efficiency it brings to the table.
You know, the problem with LLMs is they can’t fetch data from any specific tool directly; you need to give it to them. That task becomes monotonous.
Now, your LLMs can talk to all of your databases.
That’s where MCP comes in, as it is a system-level feature that allows LLMs to remember context and data from a specific tool.
With that, it provides persistent memory, personalization, and stateful interactions. It wants to become the universal connector between AIs and other tools.
Here are the four things that go in MCP.
- Users
- AI (LLM)
- MCP Client
- MCL server
- Tools
Now, let’s understand how they work together.
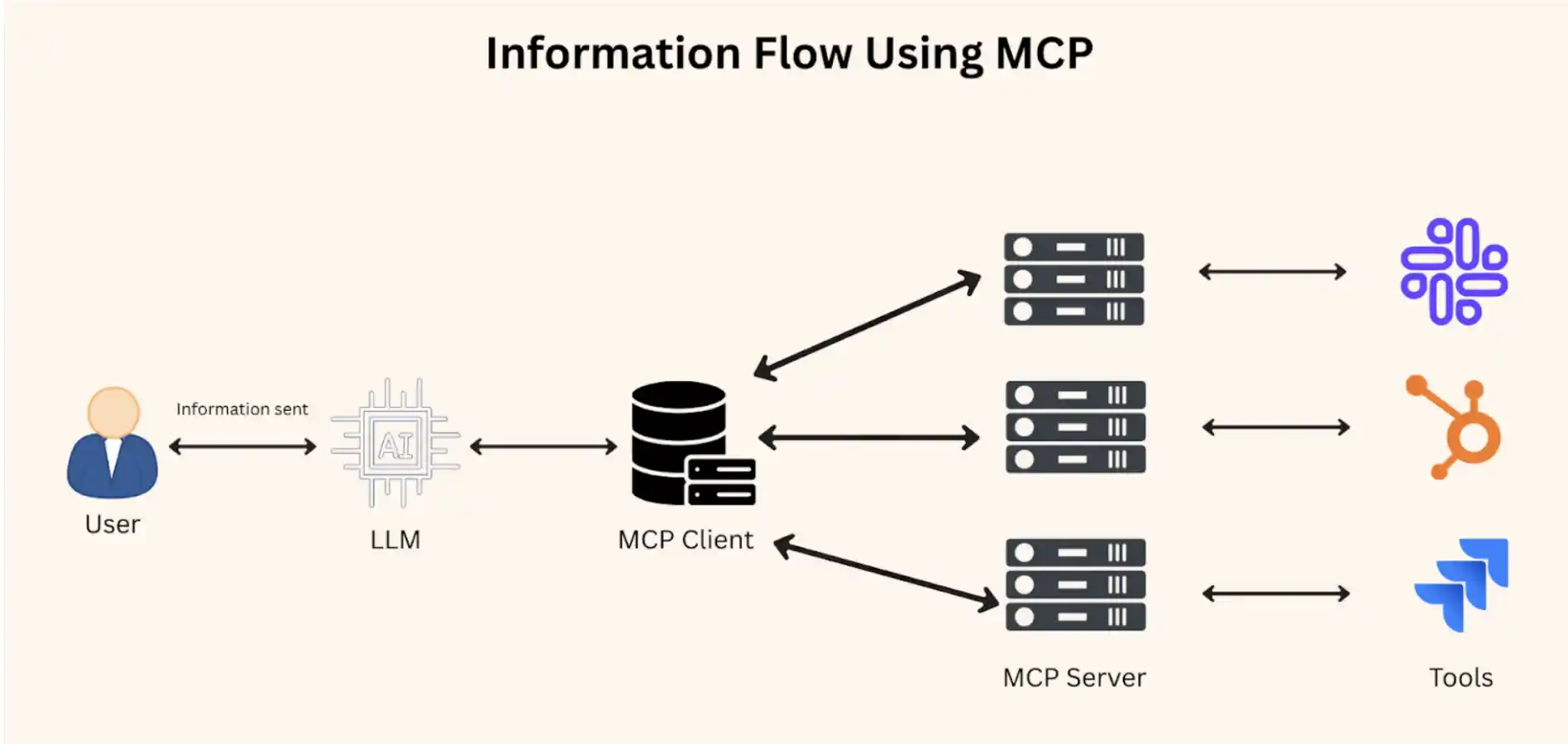
Step 1: User asked for information: “What’s the sales data overview of last month?” LLM received the query.
Step 2: LLM sent the data to the MCP client, which is an app-side agent that is integrated with LLM. MCP client communicates with MCP server.
Step 3: MCP server, which is also known as a central memory manager, will securely store your contextual information about users and make it accessible to different clients and sessions.
Step 4: Now, it gathers information from different tools and sends it to the user as per the given query.
It is solving the context problem of LLMs at the fastest pace possible.
Tools And Frameworks Used In MCP
1. Structured Memory Storage
This is the strength of MCP that remembers context.
- PostgreSQL/MongoDB – With these both, it becomes easy to manage user-specific data over time.
- Firebase/Supabase – With these, you will get real-time updates, and it’s quite simple to set up.
2. Context Management Tools
There are different types of context management tools in MCP and let’s understand them
- LangChain Memory Modules – LangChain provides built-in “memory” abstractions that allow you to manage context effectively in conversational or retrieval-based pipelines.
- LlamaIndex (Context Engine) – It is a framework that is built around ingesting structured/unstructured data and dynamically retrieving and formatting it for LLMs.
3. LLM Integration
- OpenAI & ChatGPT API
- Anthropic claude memory APIs
- LangChain agents + Tools
Key Features & Benefits Of MCP
1. Persistent Memory
- This helps in storing long-term contextual information (i.e., user preferences, project status)
- Survives across multiple sessions, unlike traditional stateless LLM chats.
2. Structure Context Representation
- Context is saved in well-defined schemas (like JSON)
- Each piece of memory can have:
Type, timestamp, source, confidence or priority score.
3. Memory Injection Into LLM Prompts
- Clients pull relevant memory and dynamically insert it into the prompt context for the language model.
- Enables personalization without fine-tuning the base model.
- It might become difficult to manage it at scale due to context overload issues.
Limitations Of MCP
MCP provides connection to different tools quickly but that also comes with multiple drawbacks. Let’s see each of those
- With multiple connections in MCP might confuse the LLM to fetch the right information from the right tool given the context overload issue.
- Malicious memory inputs or insecure context providers can manipulate LLM behaviour by putting in fake tools and data.
Key Differences Between MCP And RAG
| Feature | RAG (Retrieval Augmented Generation) | MCP (Model Context Protocol) |
| Core Function | Fetches external knowledge to answer user queries | Stores and manages user-specific memory/context |
| Primary Goal | Improve factual accuracy and domain relevance | Enable long-term memory and personalisation. |
| Data Source | External document store or knowledge base | Internal structured memory (context objects) |
| User Specific? | No, RAG retrieves general info (not tied to a specific user) | Yes, MCP is user-centric, focused on individual memory |
| Requires Prompt Injection? | Yes, retrieved docs are fed into the LLM prompt | Yes, context memory is also injected into the LLM prompt |
| Cross-Session Memory | No, stateless unless paired with other systems | Yes, designed for long-term memory across sessions |
| Cross-App Integration | No, typically app-specific | Yes, supports context sharing across multiple apps/tools |
| Retraining Dependency | Low, avoids retraining by using external sources | None, only updates memory objects, not the model itself |
Let’s Understand The Use Cases Of Both
This is important to understand when you can use RAG or MCP
When To Use RAG?
- You can use it when you need real time answers or from a specific domain.
- The LLM can directly fetch data from the vector database of the RAG.
- It will be really helpful for multiple industries like Healthcare, Legal, B2B as well as eCommerce.
- You can access it by using tools like Pinecone, LlamaIndex
When To Use MCP?
- If you’re dealing with multiple tools at a time with MCP you can link to all of them and fetch data as per need.
- Useful in all industries like Healthcare, Legal, Marketing, Sales, and many more.
When To Use Both Together?
| Uses Cases | RAGs Role | MCPs Role |
| Healthcare Virtual Assistant | Retrieve real-time medical guidelines | Track patient history and past symptoms |
| Enterprise Sales Copilot | Pull latest product sheets and lead info | Easily recall deal stages, past objections |
| HR Assistant | Fetch HR policies of a specific company | Remember user’s job level, team, past queries |
Conclusion
Perhaps you might be thinking RAG and MCP are competing with each other. But they are not.
They are complementing each other at different levels, making LLMs perform quite specifically. RAG and MCP will help you to extend the capabilities of AI.
RAG will help you retrieve real-time data, and MCP will help you connect different data sources and tools easily. Depending on the use cases, you can use any of them or both of them.
FAQ
1. What is RAG?
RAG stands for Retrieval Augmented Generation. It gives Large Language Models (LLMs) up-to-date information. RAG finds external data before the model answers. This connects old training knowledge with new facts.
2. How does RAG actually work?
First, RAG processes your question. Then, it finds relevant documents from outside sources. It adds these documents to the LLM’s context. The LLM then creates a response using both its training and the new information.
3. What are RAG’s big advantages?
RAG makes answers more accurate. It reduces made-up information. You get knowledge from specific sources. It also shows you where the information came from. Think of a university chatbot: it uses RAG to find current exam schedules.
4. When should you use RAG?
Use RAG for enterprise AI search. It’s good for customer suppnsider it for legal help, healthcare research, or financial reports. RAG improves response accuracy and context.
5. What is MCP?
MCP stands for Model Context Protocol that lets LLMs use tools and perform actions. It connects LLMs with external tools, APIs, and data in real-time. MCP moves LLMs beyond just generating text.
6. How does MCP work?
The LLM first sees it needs a tool or more information. It then sends a structured request. An outside system handles this request, getting data or performing an action. The LLM then uses the results to continue its response. For example, a university chatbot uses MCP to fetch an exam schedule.
7. What are MCP’s big advantages?
MCP uses context efficiently. It understands structured information better. It handles complex tasks needing many data sources. MCP helps LLMs take action. It helps with real-time data access. It automates tasks like sending emails or scheduling meetings. You can also trigger workflows with it.
8. When should you use MCP?
Use MCP for AI tasks that involve actions. It’s best when you want the LLM to perform actions inside an application. This could be creating a ticket or updating an account. MCP enables real-world actions, tool use, and automation.
9. Are RAG and MCP competing against each other?
No, RAG and MCP are not competitors. They do different things. RAG gives LLMs more data. MCP gives LLMs the power to act. They serve different goals.
10. Can RAG and MCP work together?
Yes, RAG and MCP can work together. They build sophisticated AI workflows. RAG helps LLMs get information. MCP executes tasks based on that information. For instance, an MCP marketing system uses RAG to get competitor info. Then, MCP tools create and schedule social media posts. MCP can also guide RAG-powered agents. Imagine an MCP agent delegating a customer query to a specialized agent who uses RAG for information.
11. How do you choose between RAG and MCP?
Your choice depends on your specific goal. Choose RAG to make LLM answers more accurate and factual. Pick MCP if your LLM needs to interact with external systems or perform actions. Combine RAG and MCP to build an intelligent system that understands and acts decisively. Many advanced AI systems combine both.