Table of Contents
Meta, the company behind Facebook, has announced that it will halt its plans for AI training systems using data from users in the European Union (EU) and the United Kingdom (UK). This decision comes in response to regulatory pushback from both the Irish Data Protection Commission (DPC) and the UK’s Information Commissioner’s Office (ICO), highlighting the complex landscape of data privacy and AI innovation in Europe.
Background: Meta’s AI Training Ambitions
Meta’s Strategy for AI Development
Meta has been a leader in leveraging AI to enhance its platforms, using vast amounts of user data to train sophisticated models. These AI models are crucial for improving content recommendation, enhancing user engagement, and developing new features. By using user-generated content, Meta aims to refine its AI systems to better serve its global user base.
The Role of Data in AI Training
AI systems require extensive datasets to function effectively. Training AI models on diverse user data allows companies like Meta to improve the accuracy and relevance of their services. This data includes user interactions, comments, status updates, photos, and their captions, all of which are valuable for training large language models.
Regulatory Concerns in Europe
The Influence of GDPR
The General Data Protection Regulation (GDPR) sets stringent rules on how companies can collect, process, and use personal data in the EU. These regulations are designed to protect individual privacy and ensure that companies handle data transparently and responsibly. Under GDPR, companies must obtain explicit consent from users before using their personal data for purposes like AI training. Effective GDPR implementation requires companies to create clear protocols for securing and managing user consent. Organizations must also regularly review and update their data protection practices to comply with GDPR standards.
Specific Objections from the DPC and ICO
The DPC, Meta’s lead regulator in the EU, expressed concerns about Meta’s plan to use public content from Facebook and Instagram to train AI models. Acting on behalf of several data protection authorities across the EU, the DPC requested Meta to pause its plans until these concerns could be addressed. Similarly, the ICO in the UK requested a halt, highlighting the need for Meta to comply with local data protection laws.
Meta’s Initial Plan and Subsequent Pause
Meta’s Intended Changes
Meta planned to start using European user data to train its AI models, arguing that such data was necessary to reflect the diverse languages, geography, and cultural references of European users. The company had begun notifying users about changes to its privacy policy, set to take effect on June 26, which would allow it to use public content for AI training. However, these plans quickly met resistance.
Pushback from Privacy Advocates
Privacy advocate group NOYB filed 11 complaints against Meta’s proposed changes, arguing that they violated various aspects of GDPR. One of the main issues was the difference between opt-in and opt-out consent. GDPR stipulates that companies should ask for user permission before processing their data, rather than requiring users to actively opt out.
The Complexity of Opting Out
Meta’s Notification Process
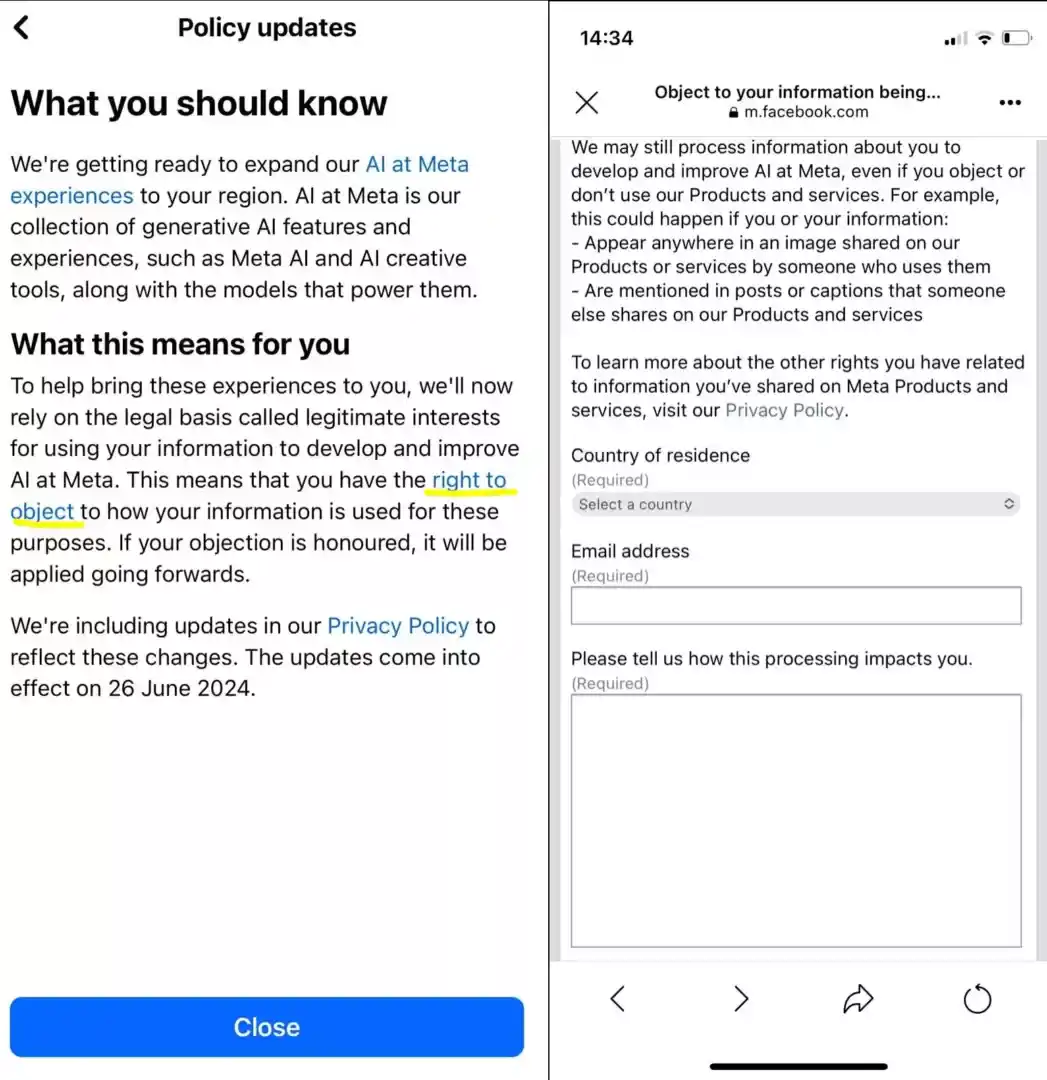
Meta informed users of the upcoming changes through notifications mixed with regular updates like friends’ birthdays and photo tag alerts. These notifications did not prominently highlight the option to opt out, making it easy for users to miss. Those who noticed the notification were directed to click through to find out more about Meta’s use of their information.
The Burden of Objection
Users wishing to opt out of having their data used for AI training faced a cumbersome process. They had to complete an objection form justifying their reasons for opting out, rather than having a straightforward opt-out option. Finding this form required navigating through multiple layers of account settings, making it difficult for users to exercise their rights easily.

Regulatory Response and Meta’s Position
Statements from the DPC and ICO
The DPC welcomed Meta’s decision to pause its AI training plans, describing the pause as a result of intensive engagement with Meta. The DPC, in cooperation with other EU data protection authorities, will continue to engage with Meta to address these issues. The ICO also emphasized the importance of ensuring that user privacy rights are respected in the development of generative AI.
Meta’s Reaction to Regulatory Pressure
Meta expressed disappointment over the regulatory request to pause its AI training plans, describing it as a setback for European innovation and competition in AI development. Despite this, Meta stated its confidence in the compliance of its approach with European laws and regulations. The company argued that its transparency in using user data for AI training exceeds that of many industry counterparts.
Broader Implications for AI and Data Privacy
The Challenge of Balancing Innovation and Compliance
Meta’s situation reflects the broader challenge faced by tech companies in balancing innovation with compliance to varying data protection regulations across different regions. The decision to pause AI training using European data highlights the difficulties companies face when operating in jurisdictions with stringent data privacy laws.
The AI Arms Race and Data Utilization
The AI arms race among tech giants emphasizes the value of data in developing advanced AI systems. Companies like Reddit and Google have faced similar challenges, with regulatory scrutiny over their data practices. This competitive landscape drives companies to navigate complex legal frameworks while seeking to leverage user data for AI development.
Future Steps for Meta
Adapting to Regulatory Requirements
Meta will likely continue to work with European regulators to find a compliant approach to AI training. This may involve revising data usage policies, improving transparency, and developing localized solutions that adhere to European data protection laws.
Exploring Alternative Training Methods
To mitigate the impact of the pause, Meta might explore alternative methods for training its AI models. Options include using synthetic data, federated learning techniques, or focusing more on non-personal data to continue enhancing its AI capabilities without violating privacy regulations.
Conclusion
Meta’s decision to pause its AI training using European user data illustrates the significant impact of regulatory pressure on tech companies. As AI technology evolves, companies must navigate the complex interplay between innovation, privacy, and compliance. Meta’s experience underscores the importance of transparent and ethical data practices, setting a precedent for how companies manage user data in the development of AI systems.
The ongoing dialogue between Meta and European regulators will likely shape the future of AI and data privacy, influencing how tech companies approach data utilization and user consent. As the regulatory landscape continues to evolve, balancing technological advancements with respect for user privacy will remain a critical challenge for the industry.