Table of Contents
Introduction to Llama 3
Llama 3 is available in two variants: an 8 billion parameter model and a larger 70 billion parameter model. These models are trained on an extensive amount of text data, making them versatile for a wide range of tasks. These tasks include but are not limited to, generating text, translating languages, creating diverse types of creative content, and providing informative answers to user queries. Meta has positioned Llama 3 as one of the top open models currently available, although it is still a work in progress. Here’s a comparison of the performance of the 8B model against Mistral and Gemma, according to Meta.
Performance of Llama 3
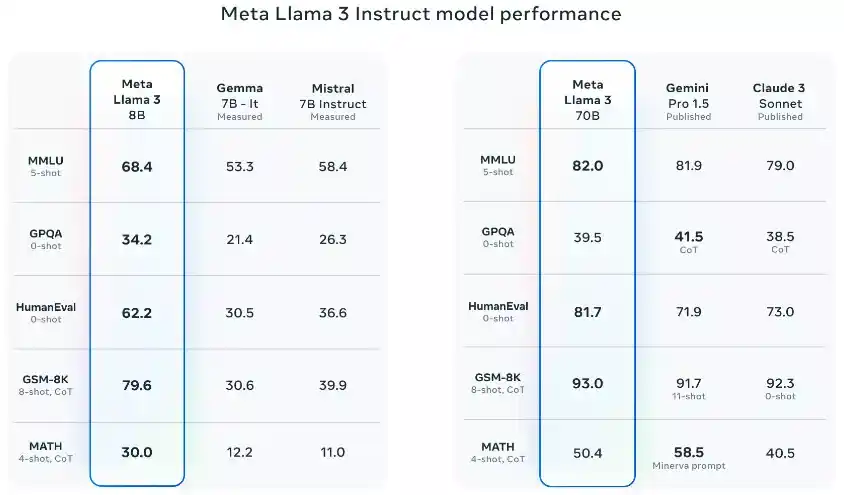
- The new 8B and 70B parameter Llama 3 models are a significant improvement over Llama 2, establishing a new state-of-the-art for LLM models at these scales.
- Thanks to advancements in pretraining and post-training, the pretrained and instruction-fine-tuned models are currently the best at the 8B and 70B parameter scale.
- Post-training improvements have led to a substantial reduction in false refusal rates, improved alignment, and increased diversity in model responses.
- Llama 3 has greatly improved capabilities like reasoning, code generation, and instruction following, making it more steerable.
- In the development of Llama 3, performance was evaluated on standard benchmarks and optimized for real-world scenarios.
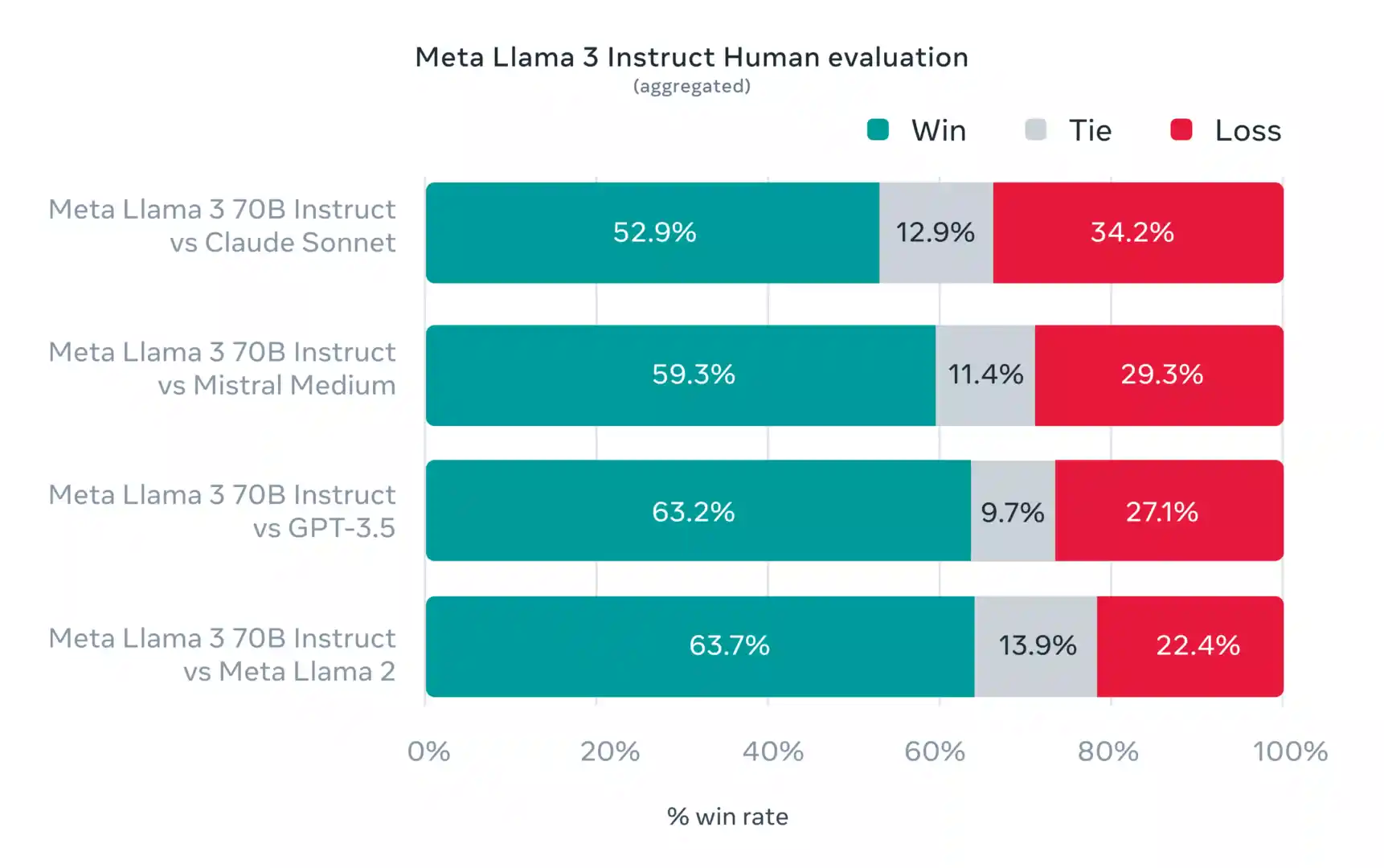
- A new high-quality human evaluation set was developed, containing 1,800 prompts covering 12 key use cases.
- To prevent accidental overfitting, even the modeling teams do not have access to this evaluation set.
- Preference rankings by human annotators based on this evaluation set highlight the strong performance of the 70B instruction-following model in real-world scenarios.
- The pretrained model also establishes a new state-of-the-art for LLM models at these scales. Please see evaluation details for setting and parameters with which these evaluations are calculated.
How to Run Llama 3 Locally? Step-by-step guide
To run these models locally, we can use different open-source tools. Here are a couple of tools for running models on your local machine.
Using HuggingFace
HuggingFace has already rolled out support for Llama 3 models. We can easily pull the models from HuggingFace Hub with the Transformers library. You can install the full-precision models or the 4-bit quantized ones. Here’s an example of running it on the Colab free tier.
Step 1: Install Libraries
First, install the necessary libraries and upgrade the Transformers library.
!pip install -U "transformers==4.40.0" --upgrade
!pip install accelerate bitsandbytesStep 2: Install Model
Now, let’s install the model and start querying.
import transformers
import torch
model_id = "unsloth/llama-3-8b-Instruct-bnb-4bit"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
)Step 3: Send Queries
Now, send queries to the model for inference.
messages = [
{"role": "system", "content": "You are a helpful assistant!"},
{"role": "user", "content": """Generate an approximately fifteen-word sentence
that describes all this data:
Cafe House eat Type restaurant;
Cafe House food Asian;
Cafe House priceRange moderate;
Cafe House customer rating 4 out of 5;
Cafe House near Star Bar """},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])Output of the query: “Here is a 15-word sentence that summarizes the data:
Cafe House is a moderate-priced Asian eatery with a 4-star rating near Star Bar.”
Step 4: Install Gradio and Run Code
To create an interactive chat interface, wrap this inside Gradio. Install Gradio and run the code below.
import gradio as gr
messages = []
def add_text(history, text):
global messages #message[list] is defined globally
history = history + [(text,'')]
messages = messages + [{"role":'user', 'content': text}]
return history
def generate(history):
global messages
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response_msg = outputs[0]["generated_text"][len(prompt):]
for char in response_msg:
history[-1][1] += char
yield history
pass
with gr.Blocks() as demo:
chatbot = gr.Chatbot(value=[], elem_id="chatbot")
with gr.Row():
txt = gr.Textbox(
show_label=False,
placeholder="Enter text and press enter",
)
txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(
generate, inputs =[chatbot,],outputs = chatbot,)
demo.queue()
demo.launch(debug=True)Here is a demo of the Gradio app and Llama 3 in action.
Using Ollama
Ollama is another open-source software for running LLMs locally. To use Ollama, you have to download the software.
Step 1: Starting Local Server
Once downloaded, use this command to start a local server.
ollama run llama3:instruct #for 8B instruct model
ollama run llama3:70b-instruct #for 70B instruct model
ollama run llama3 #for 8B pre-trained model
ollama run llama3:70b #for 70B pre-trainedStep 2: Query Through API
Send a query through the API.
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Why is the Ocean blue?",
"stream": false
}'Step 3: JSON Response
You will receive a JSON response.
{
"model": "llama3",
"created_at": "2024-04-19T19:22:45.499127Z",
"response": "The Ocean is blue because of the reflection on the sky.",
"done": true,
"context": [1, 2, 3],
"total_duration": 5043500667,
"load_duration": 5025959,
"prompt_eval_count": 26,
"prompt_eval_duration": 325953000,
"eval_count": 290,
"eval_duration": 4709213000
}Conclusion
Our journey into the realm of language modeling has led us to some truly exciting discoveries. Among these is Llama 3, a cutting-edge language model that’s making waves in the tech world. But what’s even more thrilling is that we can now run Llama 3 right on our local machines! Thanks to innovative technologies like HuggingFace Transformers and Ollama, the power of Llama 3 is now within our grasp.
This breakthrough has opened up a plethora of possibilities across various industries. Whether it’s automating customer service, generating creative content, or even aiding in scientific research, the applications of Llama 3 are virtually limitless.
But perhaps the most promising aspect of Llama 3 is its open-source nature. This means that it’s not just a tool for the tech elite, but a resource that’s accessible to developers all over the world. It’s a testament to the spirit of innovation and accessibility that drives the tech community.
Read other comparasion
Llama 2 vs Mistral 7B: Comparison of Two Leading LLM