Table of Contents
Organizations face a critical decision when choosing their data platform.
Two giants dominate this space: Databricks and Snowflake.
While both platforms help businesses unlock value from their data, they approach the problem from fundamentally different angles.
Understanding these differences is crucial for making an informed decision that aligns with your organization’s needs, as you decide which to choose between Databricks vs Snowflake.
Understanding the Core Philosophy
Before diving into technical comparisons, it’s important to understand what each platform was built to do.
Snowflake emerged as a cloud-native data warehouse designed to simplify data storage and analytics.
Its core strength lies in providing a scalable, easy-to-use SQL-based platform for business intelligence and reporting.
It excels at structured data analysis and makes it remarkably simple for analysts to query large datasets without worrying about infrastructure management.

Databricks, on the other hand, was born from the academic origins of Apache Spark at UC Berkeley.
It’s fundamentally a lakehouse platform that unifies data warehousing and data lake capabilities.
It is built for organizations that need advanced analytics, machine learning, and real-time data processing alongside traditional BI workloads.
Databricks vs Snowflake Architecture: A Deep Dive
The architectural differences between these platforms reveal much about their strengths and ideal use cases, in Databricks vs Snowflake.
Snowflake Architecture
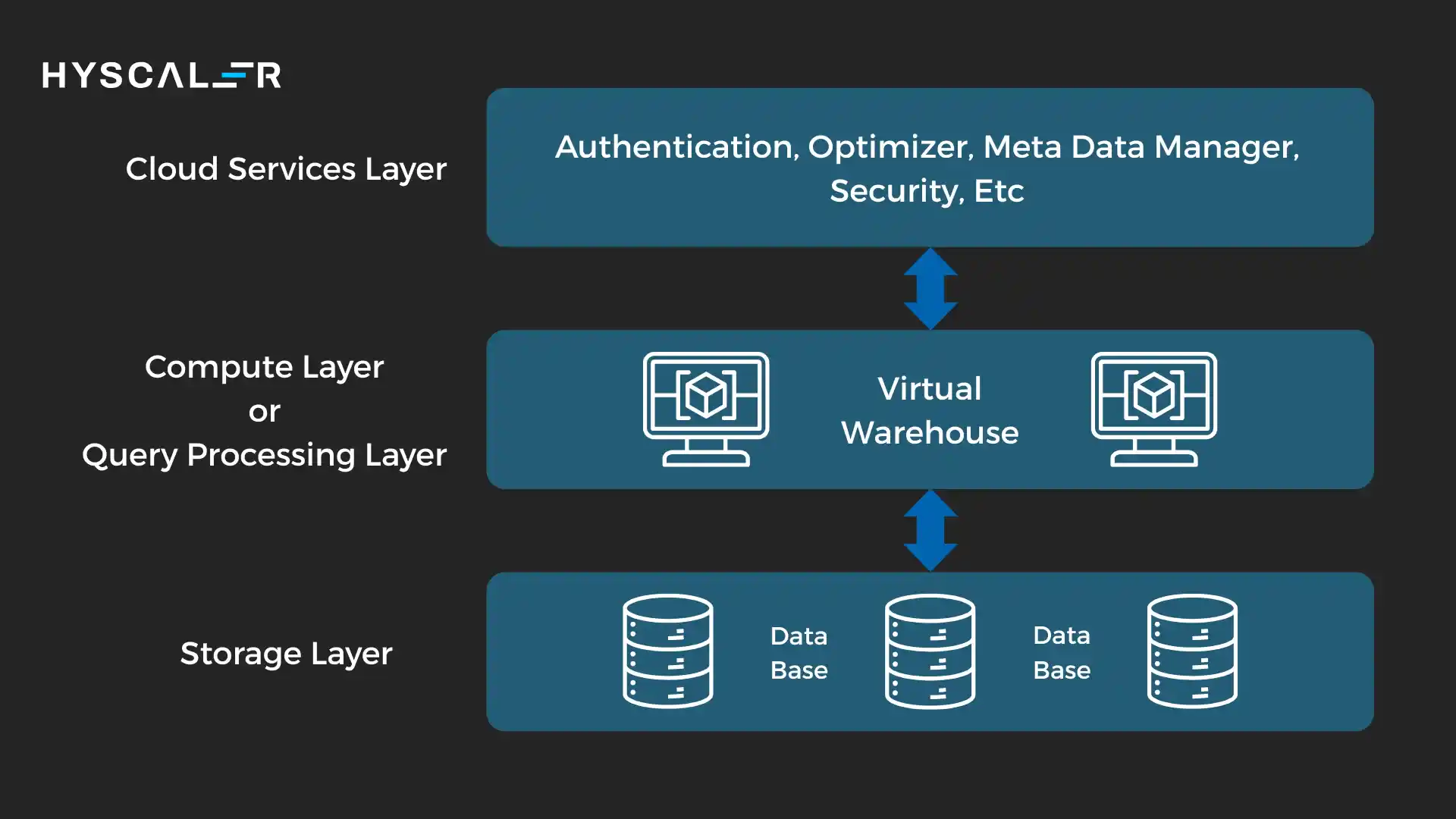
Its architecture is built on three distinct layers that can scale independently:
Storage Layer: Snowflake stores data in a proprietary format optimized for cloud object storage (AWS S3, Azure Blob, or Google Cloud Storage).
Data is automatically compressed, encrypted, and organized into micro-partitions.
Users don’t manage this storage directly.
Snowflake handles all the optimization.
Compute Layer: Virtual warehouses provide the computational power for queries.
These are independent clusters that can be spun up or down instantly.
Multiple warehouses can access the same data simultaneously without contention, which is excellent for isolating workloads (development vs. production, different departments, etc.).
Cloud Services Layer: This orchestration layer handles authentication, metadata management, query optimization, and security.
It’s the brain that coordinates between storage and compute.
This separation of storage and compute is Snowflake’s architectural innovation.
You can scale compute power without affecting storage costs, and multiple teams can work with the same data using different compute resources.
Databricks Architecture
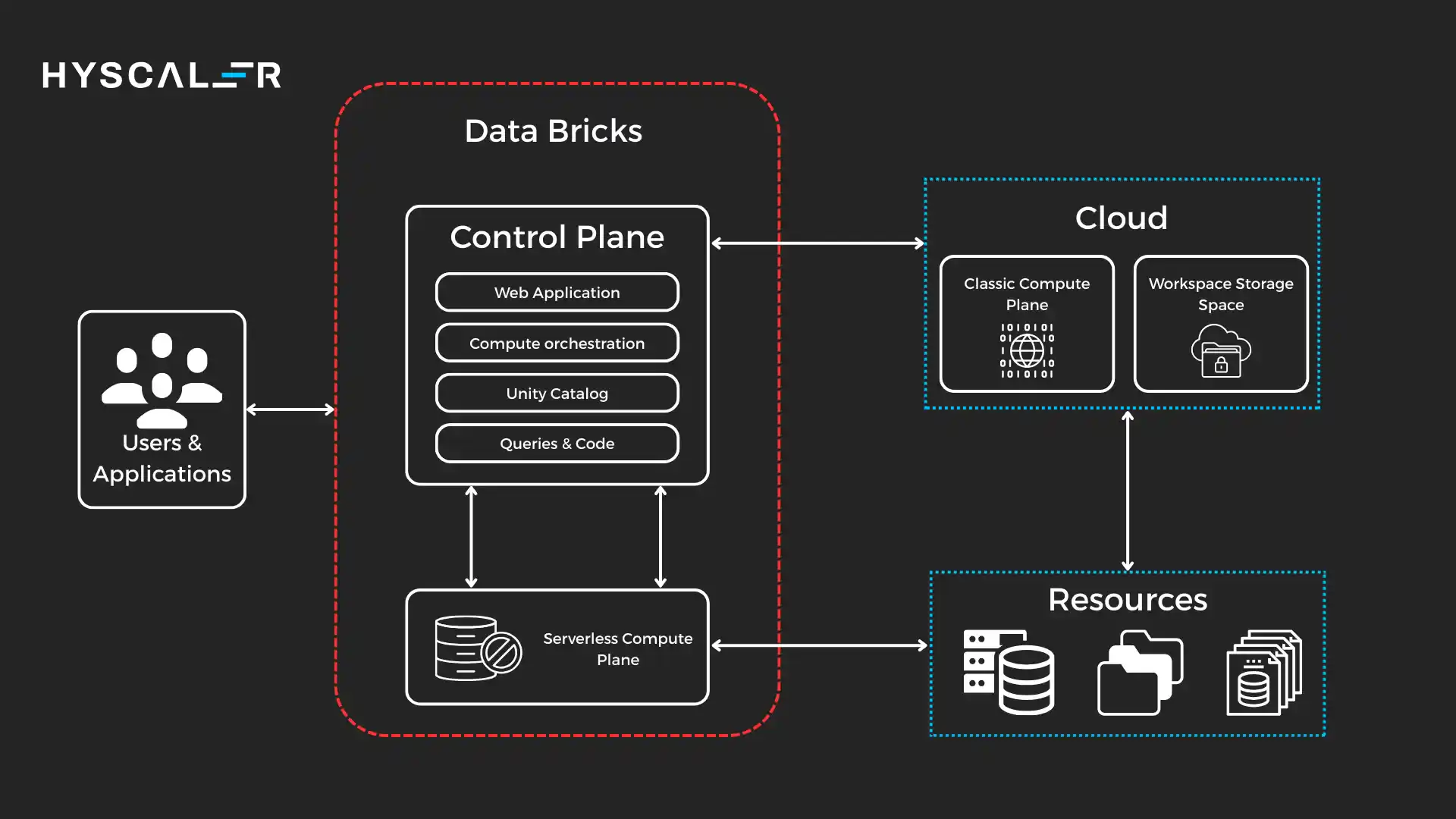
It takes a different approach with its lakehouse architecture:
Delta Lake Foundation: At the core is Delta Lake, an open-source storage layer that brings ACID transactions to data lakes.
Unlike Snowflake’s proprietary format, Delta Lake stores data in open Parquet format, meaning you’re never locked into the platform.
Delta Lake adds reliability features typically found in databases (transactions, versioning, schema enforcement) to object storage.
Unified Computing Layer: It runs on Apache Spark clusters that can be configured for different workloads like SQL analytics, streaming, machine learning, or data engineering.
These clusters use in-memory processing and distributed computing to handle massive datasets efficiently.
Delta Engine: This is Databricks’ high-performance query engine optimized for Delta Lake.
It provides vectorized execution and intelligent caching to accelerate queries.
MLflow and Feature Store: Built-in tools for the complete machine learning lifecycle, from experimentation to production deployment.
This integration is a key differentiator from Snowflake.
Unity Catalog: A unified governance layer that manages data, ML models, and AI assets across clouds.
The lakehouse architecture means all your data, like structured, semi-structured, and unstructured, lives in one place.
Data scientists can train models on the same data that analysts query, without moving or copying datasets.
Key Differences in Practice
Data Science and Machine Learning
In Databricks vs Snowflake: This is where Databricks truly shines.
The platform provides native support for Python, R, Scala, and SQL, with integrated notebooks for collaborative development.
You can build, train, and deploy machine learning models entirely within Databricks using built-in libraries and MLflow for experiment tracking.
Snowflake has added machine learning capabilities through Snowpark, which allows Python-based data science work.
However, it’s primarily focused on bringing ML to the data rather than providing a comprehensive ML platform.
For organizations with heavy ML requirements, Databricks offers a more mature and feature-rich environment.
Real-Time and Streaming Data
Databricks excels at streaming analytics through Structured Streaming in Apache Spark.
You can process real-time data streams, perform complex transformations, and update tables continuously with exactly-once semantics.
Snowflake introduced Snowpipe for continuous data ingestion and Dynamic Tables for streaming transformations, but its architecture is fundamentally designed for batch-oriented workloads.
While adequate for many streaming use cases, it doesn’t match Databricks’ real-time processing capabilities.
SQL and Business Intelligence
Snowflake was purpose-built for SQL analytics, and it shows.
The platform offers exceptional query performance on structured data, with automatic query optimization and caching.
It integrates seamlessly with every major BI tool (Tableau, Power BI, Looker), and its SQL dialect is highly compatible with existing code.
Databricks has significantly improved its SQL capabilities with Databricks SQL (formerly SQL Analytics), offering a competitive SQL experience.
The performance gap has narrowed considerably, though Snowflake still maintains an edge for pure SQL workloads, particularly for traditional analysts who prefer a data warehouse experience.
Data Engineering and ETL
Databricks provides more flexibility for complex data engineering pipelines.
With support for multiple programming languages and distributed computing frameworks, you can build sophisticated transformation logic.
Delta Live Tables simplify pipeline creation with declarative syntax while handling data quality and lineage automatically.
Snowflake’s approach is simpler with stored procedures, tasks, and streams for orchestration.
While less flexible than Databricks, this simplicity can be advantageous for teams primarily focused on SQL-based transformations.
Cost Structure
In Databricks vs Snowflake: Both platforms charge for compute and storage, but the models differ:
Snowflake uses per-second billing for compute (measured in credits) with separate storage charges.
The pay-per-query model means you only pay when you’re running queries, which can be economical for intermittent workloads.
Databricks charges for DBUs (Databricks Units) based on cluster uptime, along with the underlying cloud infrastructure costs. Long-running clusters for streaming or ML workloads can become expensive, though automated cluster management helps optimize costs.
Cost optimization requires careful attention with both platforms.
Snowflake needs proper warehouse sizing and query optimization, while Databricks requires cluster management and choosing appropriate instance types.
Open Standards and Portability
Databricks embraces open-source technologies like Spark, Delta Lake, and MLflow, giving you more flexibility and avoiding vendor lock-in.
Your data in Delta format is accessible outside it if needed.
Snowflake’s proprietary format and architecture mean your data and workloads are tightly coupled to the platform.
Migration away from Snowflake requires significant effort, though the platform’s capabilities often make this a non-issue for most organizations.
Which Platform Should You Choose?
The choice between Databricks and Snowflake depends on your organization’s specific needs, and in Databricks vs Snowflake:
Choose Snowflake if:
- Your primary use case is business intelligence and SQL-based analytics
- You have many analysts who need simple, fast access to data
- You want minimal infrastructure management and a simpler learning curve
- Your data is primarily structured
- You need a straightforward data warehouse solution
Choose Databricks if:
- You have significant machine learning and data science requirements
- You need real-time streaming analytics
- You’re working with diverse data types (structured, semi-structured, unstructured)
- You have a technical team comfortable with programming languages beyond SQL
- You want the flexibility of open-source technologies
- You need a unified platform for data engineering, data science, and analytics
Many large organizations actually use both platforms: Snowflake for their structured analytics and reporting needs, and Databricks for advanced analytics, ML, and data engineering.
This hybrid approach leverages the strengths of each platform.
The Future Landscape
Both platforms are rapidly evolving, in Databricks vs Snowflake:
Snowflake is investing heavily in data science capabilities, external data sharing, and unstructured data support.
Databricks continues to enhance its SQL performance, governance capabilities, and ease of use for analysts.
The convergence is real, both companies are expanding into each other’s traditional territories.
However, their architectural foundations mean they’ll likely maintain distinct advantages in their core areas.
Conclusion
Databricks vs Snowflake: Neither Databricks nor Snowflake is objectively “better”- they’re different tools optimized for different problems.
Snowflake offers simplicity, ease of use, and exceptional performance for traditional analytics workloads.
Databricks provides power, flexibility, and advanced capabilities for organizations pushing the boundaries of data science and real-time analytics.
The right choice depends on your team’s skills, your data’s characteristics, and your business objectives.
Consider starting with a proof of concept on both platforms using your actual data and use cases.
This hands-on experience will reveal which platform aligns better with your workflows and requirements.
FAQs
Is Databricks worth more than Snowflake?
As of late 2025, Snowflake’s public market cap is about $85-90 billion.
Databricks remains private, but recent funding and valuation estimates place it at approximately $100-134 billion, suggesting that on paper, it may be “worth more.”
That said, because Databricks is private, its valuation is based on investor funding rounds and projections, not public-market pricing, making comparisons approximate.
Will Databricks overtake Snowflake?
It’s unlikely that Databricks will fully “overtake” Snowflake across the board.
Databricks is leading in AI, ML, and lakehouse workloads, while Snowflake remains strong in enterprise analytics and traditional data warehousing.
Most analysts expect both to thrive as leaders in different use cases, rather than one replacing the other.
Who is Databricks’ biggest competitor?
While Snowflake is Databricks’ closest direct rival, competition is broader.
Google BigQuery, AWS (Redshift, EMR, Glue, SageMaker), and Azure Synapse all compete across data warehousing, analytics, and ML.
In AI/ML specifically, SageMaker and Vertex AI are key rivals.
Overall, Databricks’ toughest battles are for analytics budgets with Snowflake and for full-stack data platforms with AWS.
Who has more customers, Databricks or Snowflake?
Snowflake now reports 12,600+ customers globally as of late 2025. Databricks now claims to serve over 15,000 customers worldwide.
Should I learn Snowflake or Databricks?
Choose based on your role: Snowflake is ideal for data analysts and BI roles focused on SQL and reporting, while Databricks is better for data engineers, data scientists, and ML-focused roles.
For maximum flexibility, learning both is best, skills transfer easily between them. Start with what matches your current job and local market demand.
Who is Snowflake’s biggest competitor?
While Databricks is Snowflake’s main direct rival for next-gen cloud data platform spending, competition is broader.
Google BigQuery, Amazon Redshift, and Azure Synapse all compete strongly in cloud warehousing, while Oracle and Teradata still hold some enterprise accounts.
Open lakehouse standards like Apache Iceberg and Hudi also pose long-term competitive pressure. In the near term, Databricks remains Snowflake’s biggest growth threat.