Table of Contents
There is a persistent gap in the world of artificial intelligence applications: the chasm between elegant theory and real-world deployment. Teams invest heavily in AI development, debating architectures for weeks, only to discover their artificial intelligence applications behave unpredictably when facing real users, real data, and unforgiving production infrastructure.
This guide exists to close that gap.
Whether you are exploring AI application development for the first time or scaling an existing platform, understanding the core forces behind every large language model is essential. Every failure in artificial intelligence applications traces back to an imbalance among three key elements:
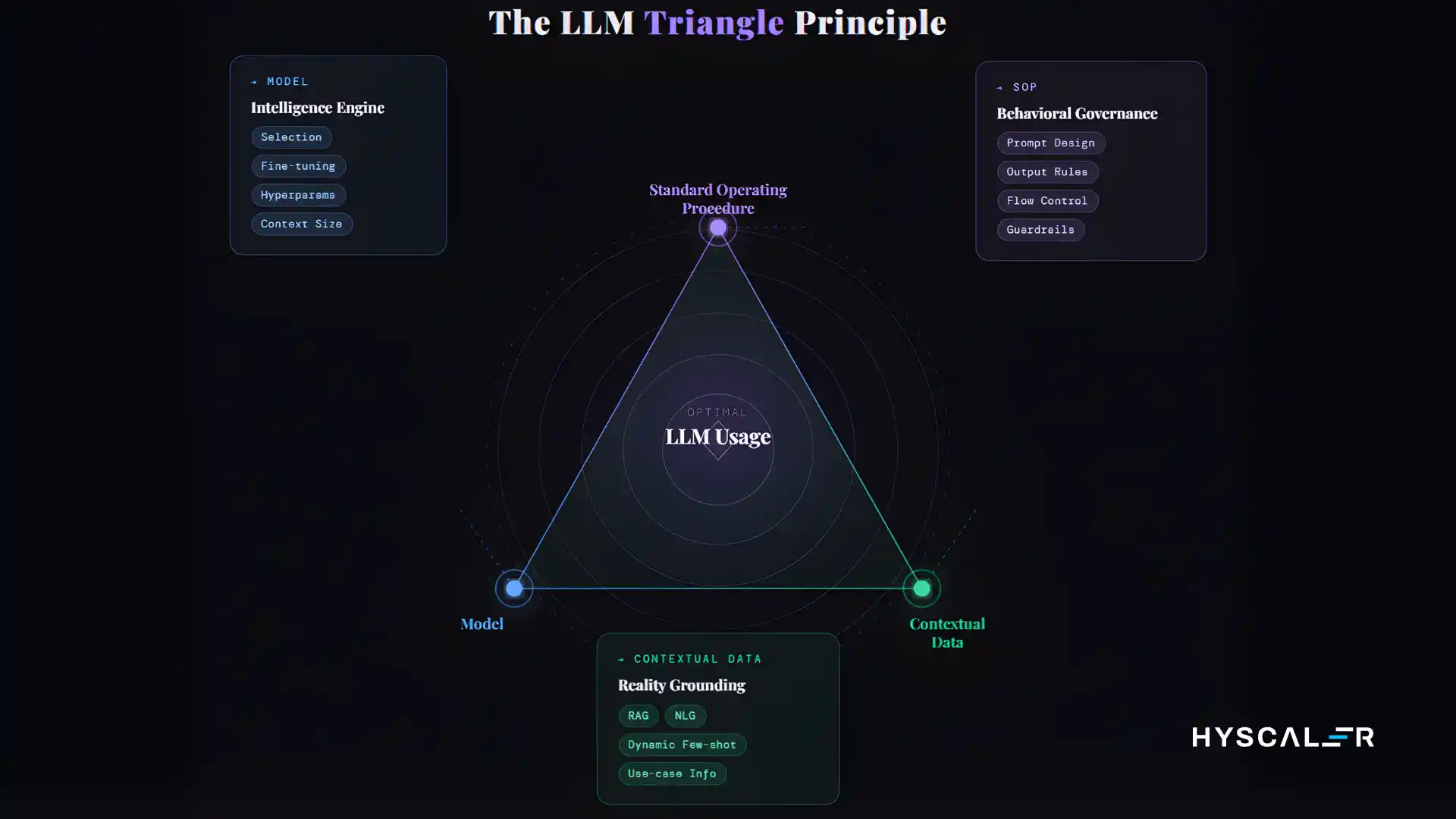
- Standard Operating Procedure (SOP): shapes how the model behaves, responds, and refuses
- Model: the intelligence engine that processes inputs and generates outputs
- Contextual Data: grounds artificial intelligence applications in reality with relevant, accurate information
This is the LLM Triangle: the foundation of every reliable AI software development effort.
Key Insight: Organizations that build artificial intelligence applications without a principled AI framework spend 3–4× more time on post-launch fixes than those who architect deliberately from the start.
The SOP: The Constitution of Your Artificial Intelligence Applications
Think of the SOP as the governing document for your artificial intelligence applications. It defines what your AI is, what it is not, how it responds under pressure, and what it absolutely refuses to do. Whether you are building internally or working with AI development services, a production-grade SOP is built around three pillars:
- Precision: Artificial intelligence applications know exactly what domain they operate in
- Resilience: handle edge cases, ambiguous queries, and multilingual inputs without breaking character
- Adaptability: evolve as business needs change without requiring a full system rebuild
Anatomy of a Production SOP
- Role Definition: Who is this AI? What is its persona and purpose?
- Scope Boundaries: What will it help with, and what is out of scope?
- Tone & Voice Guidelines: Formal, conversational, or technical?
- Escalation Protocols: When does the AI defer to a human agent?
- Safety Rails: Hard-coded refusals and ethical constraints
- Output Format Rules: JSON, Markdown, or plain text, and when each applies
An untested SOP is a liability. Before any of your artificial intelligence applications go live, subject your SOP to adversarial testing, probe it with jailbreak attempts, off-topic queries, and emotionally charged inputs. Document every failure and refine iteratively.
Pro Tip: Treat your SOP like software code version-control it, review changes via pull requests, and never modify it in production without a staged rollout.
Engineering Artificial Intelligence Applications for Production
The bridge between a prototype and production-ready artificial intelligence applications is an engineering discipline. In modern AI software development, the techniques you choose at this stage determine reliability, latency, cost, and scalability.
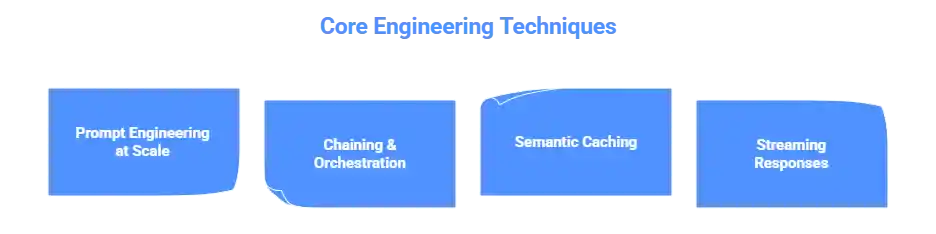
- Prompt Engineering at Scale: Design parameterized, versioned prompt templates that work reliably across millions of inputs. This is the discipline that separates prototype AI development from truly production-ready artificial intelligence applications.
- Chaining & Orchestration: Complex artificial intelligence applications involve chains of model interactions. Frameworks like LangChain or LlamaIndex are cornerstones of any solid AI framework help build pipelines with graceful failure handling.
- Semantic Caching: Reduce inference costs by storing and retrieving responses for semantically similar queries using tools like GPTCache.
- Streaming Responses: Streaming tokens as they are generated dramatically improves perceived performance across all artificial intelligence applications.
When evaluating AI development services or building in-house, always confirm these engineering fundamentals are part of your delivery process; they are non-negotiable for production-grade AI application development.
Model Selection: Choosing the Right Engine
One of the most consequential decisions when building artificial intelligence applications is choosing which model to deploy. Evaluate across five dimensions: capability, cost, latency, context window size, and compliance posture. There is no universally correct answer, only the right answer for your specific use case.
Fine-Tuning vs. Prompting vs. RAG
| Approach | Best For | Trade-off |
|---|---|---|
| Pure Prompting | Fast iteration | Limited specialization |
| Fine-Tuning | Highly specialized artificial intelligence applications | Requires labeled data & compute |
| RAG | Proprietary knowledge grounding | The right first step for most AI development teams |
In most AI application development scenarios, RAG is the right first step. Fine-tuning should be reserved for cases where even well-grounded prompting consistently falls short. Any mature AI framework should support all three approaches and guide your team toward the best fit.
Key Insight: The best model is not the most powerful one; it’s the smallest model that reliably meets the accuracy requirements of your artificial intelligence applications. Oversizing wastes money and adds latency.
Contextual Data: The Third Vertex
If the SOP is the constitution and the model is the judge, contextual data is the evidence. The quality and freshness of data you feed into artificial intelligence applications at inference time determines whether they give grounded answers or confident hallucinations.
Production artificial intelligence applications that require domain knowledge need a well-structured knowledge infrastructure:
- A vector database (Pinecone, Weaviate, or pgvector) for semantic retrieval
- A document processing pipeline for ingesting and chunking source materials
- A metadata layer for filtering retrieved context by relevance, recency, and access permissions
Chunking strategy matters enormously in any serious AI software development effort. Chunks too small lose context; chunks too large dilute relevance. Every context window has a budget; allocate it carefully across your SOP, retrieved context, conversation history, and the user’s query.
Static knowledge bases become stale. Your artificial intelligence applications need a continuous data sync pipeline to stay accurate and trustworthy, a critical consideration often overlooked early in the AI development journey.
Production Infrastructure & Observability
The most sophisticated artificial intelligence applications will still fail users if the infrastructure beneath them is unreliable. Whether you are building with internal teams or relying on external AI development services, design your inference serving layer for horizontal scalability from day one.
Implement circuit breakers to handle model API outages gracefully and route to fallback providers automatically. Design with the assumption that any external dependency will fail, users should experience a degraded-but-functional experience from your artificial intelligence applications, never a hard error.
A comprehensive observability stack for artificial intelligence applications includes:
- Structured logging of every prompt and response (with PII redaction)
- Latency and throughput metrics at every layer
- Cost tracking per user and per feature
- AI-specific metrics: response length distributions and refusal rates
Tools like Langfuse, Helicone, and Arize AI are purpose-built for this domain and should be standard in any AI framework used in production.
Security, Compliance, and Responsible AI
Building artificial intelligence applications is not just a technical challenge; it is a responsibility. Prompt injection, where malicious users craft inputs that override your SOP, is the most common attack vector in AI application development. Defend with:
- Input sanitization pipelines
- Output validation layers that detect SOP violations
- Architectural separation between user inputs and system instructions
- Secondary classifier models that screen inputs for injection patterns
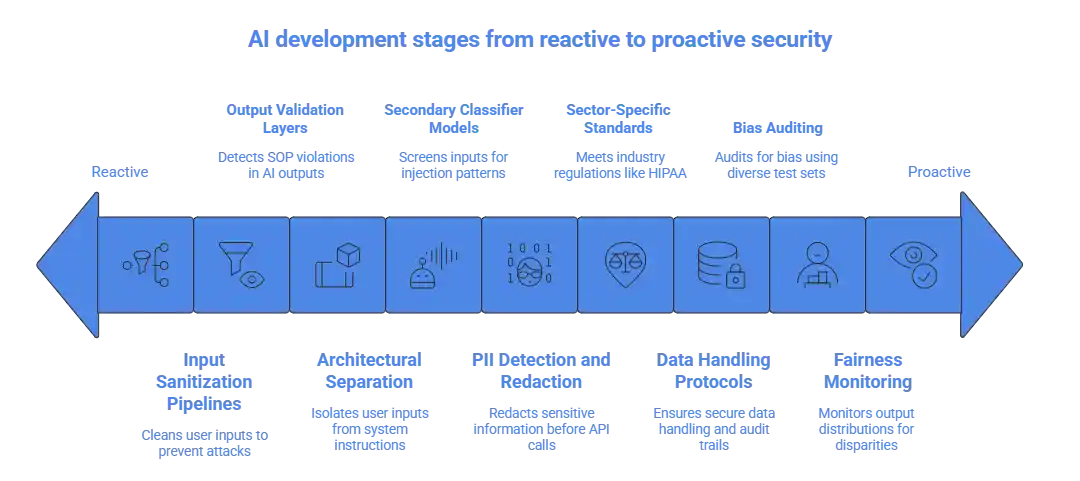
Implement PII detection and redaction before data reaches any external model API. For regulated industries, ensure your artificial intelligence applications meet sector-specific standards like HIPAA or PCI-DSS. Any reputable AI development services provider should have clear data handling protocols and audit trails built into their delivery methodology.
Conduct systematic bias auditing using diverse test sets, and monitor output distributions across user segments for quality disparities. Responsible AI software development means treating fairness as an ongoing operational discipline, not a one-time checkbox.
Optimization and Continuous Iteration
The work of building artificial intelligence applications does not end at launch; it begins there. Establish a continuous evaluation cadence that runs automatically against a golden dataset of test cases. Regression in evaluation scores should block deployments, just as failing unit tests do in traditional AI software development.
Build explicit user feedback collection into your artificial intelligence applications from day one. Triage thumbs-up/down ratings, correction submissions, and escalations into:
- SOP improvements
- Knowledge base updates
- Fine-tuning datasets
The teams with the tightest feedback loops in their AI development workflow improve fastest. As your artificial intelligence applications scale, implement model tiering, routing simpler queries to cheaper models, and escalating only when necessary. This approach, a hallmark of mature AI application development, can reduce inference costs by 50% or more at scale.
The landscape of artificial intelligence applications evolves faster than any other technology domain. Teams that evaluate new models and tools regularly within a structured AI framework maintain a competitive advantage that compounds over time.
Conclusion: Building Sustainable Artificial Intelligence Applications
The LLM Triangle SOP, Model, and Contextual Data is more than a conceptual model. It is a practical diagnostic tool that focuses your team’s attention on the three forces that determine whether your artificial intelligence applications succeed or fail in the real world.
Sustainable artificial intelligence applications are not built in a sprint. They are built through disciplined AI development practices, operational rigor, ethical commitment, and a genuine culture of learning from failure. Whether you are building in-house or partnering with AI development services, the principles are the same: start with your SOP, build your data infrastructure deliberately, choose your model with your eyes open, instrument everything, and iterate relentlessly. It is the highest-leverage investment you can make. Build your data infrastructure deliberately. Choose your model with your eyes open. Instrument everything. Iterate relentlessly.
FAQ
What is the LLM Triangle Principle in simple terms?
It is a 3-part framework: SOP (rules), Model (AI brain), and Contextual Data (information). All three must work together. If one fails, your whole AI fails.
What does production-ready AI mean?
It means your AI works reliably for real users every day, not just in a test or demo. It handles errors, stays fast, keeps data safe, and can be monitored and improved.
What is RAG, and when should I use it?
RAG is a technique where the AI searches your knowledge base and pulls in relevant information before generating an answer. It grounds the AI in real, accurate data rather than relying only on what it was trained on.
What is prompt injection, and how do I stop it?
Detect and redact personal information before sending it to any external model API. Set clear data retention policies. Give users the ability to request deletion of their data. Follow all relevant privacy laws.
What is LangChain, and do I need it?
LangChain is a framework that speeds up AI app development with ready-made components. You do not strictly need it, but it saves significant time and is widely used in production teams.
What are the 4 stages of AI development?
Discovery (understand the problem), Prototyping (test ideas quickly), Hardening (add reliability, safety, and monitoring), and Production (deploy, monitor, and continuously improve).
What laws and regulations apply to AI applications?
The EU AI Act, US state-level AI regulations, and sector-specific rules like HIPAA for healthcare and PCI-DSS for finance all apply depending on your location and industry. Assign someone in your team to own AI compliance.
What tools should I use to monitor my AI in production?
Use tools like Langfuse, Helicone, or Arize AI. These track every prompt and response, measure latency and costs, and alert you when something goes wrong before your users notice.
How do I reduce the response time of my AI?
Place your app server close to your model, use streaming, implement caching, and use prompt caching for repeated instructions. Every millisecond saved improves the user experience.
What is a vector database, and do I need one?
A vector database stores information in a way that allows AI to find the most relevant content by meaning, not just keywords. If your AI needs to search through documents or knowledge bases, yes, you need one.